Предисловие
Возможно, вам интересно, кто мы и почему написали эту книгу.
В последнем издании книги Test-Driven Development with Python (O’Reilly), в конце, Гарри поймал себя на мысли, что задает уйму вопросов по архитектуре. Типа, как лучше всего структурировать приложение, чтобы его было легко тестировать? Это вообще, про что? Может это про покрытие модульными тестами вашей основной бизнес-логики и что бы количество необходимых вам интеграционных и сквозных тестов было минимизировано? Он дал расплывчатые ссылки на «Гексагональную архитектуру», «Порты и адаптеры» и "Functional Core, Imperative Shell", но если бы он был честен, ему пришлось бы признать, что это не то, что он действительно до конца понял, принял или применял на практике.
И тут случилось чудо! Ему посчастливилось столкнуться с Бобом, у которого есть ответы на все эти вопросы.
Боб стал архитектором программного обеспечения, потому что никто из его команды этим не занимался. Оказалось, что он неплохо справлялся с этим, но ему посчастливилось столкнуться с Яном Купером, который научил его новым способам написания кода и мышления в этй области.
Управление Сложностью, Решение Бизнес-Задач
Мы оба работаем в MADE.com, европейской компании электронной коммерции, которая продает мебель онлайн; там мы применяем методы, описанные в этой книге, для создания распределенных систем, моделирующих реальные бизнес-проблемы. Наш пример домена — первая система, созданная Бобом для MADE, и эта книга-попытка записать всё то, чему мы должны научить новых программистов, когда они присоединяются к одной из наших команд.
MADE.com управляет глобальной цепочкой поставок грузов от тоговых партнеров и производителей. В целях сохранения затрат на нзком уровне, мы стараемся оптимизировать доставку запасов на наши склады, чтобы у нас не было непроданных товаров, застрявших на складах.
В идеале диван, который вы хотите купить, прибудет в порт в тот самый день, когда вы решите его купить, и мы отправим его прямо к вам домой, даже не храня. Получение правильного времени — это сложный балансирующий акт, когда товары прибывают на контейнеровозе в течение трех месяцев. По пути вещи ломаются или повреждаются водой, штормы вызывают неожиданные задержки, логистические партнеры неправильно обращаются с товарами, документы пропадают, клиенты меняют свое мнение и изменяют свои заказы и так далее.
Мы решаем эти проблемы, создавая интеллектуальное программное обеспечение, представляющее виды операций, происходящие в реальном мире, чтобы мы могли автоматизировать как можно большую часть бизнеса.
Почему Python?
Если вы читаете эту книгу, то вероятно, не нужно убеждать вас в том, что Python великолепен, поэтому реальный вопрос заключается в следующем: "Зачем сообществу Python нужна такая книга?" Ответ заключается в популярности и зрелости Python: хотя Python, вероятно, является самым быстрорастущим языком программирования в мире и приближается к вершине абсолютной таблицы популярности, он только начинает решать те проблемы, над которыми мир C# и Java работал в течение многих лет. Стартапы становятся реальным бизнесом; веб-приложения и скриптовые автоматизации становятся (говорю шепотом) enterprise software.
В мире Python мы часто цитируем Дзен Python: "Должен существовать один и, желательно, только один очевидный способ сделать это."[2] К сожалению, по мере роста размера проекта наиболее очевидный способ решения задач не всегда помогает вам управлять сложностью и меняющимися требованиями.
Ни один из методов и шаблонов, которые мы обсуждаем в этой книге, не является новым, но по большей части они являются новыми для мира Python. И эта книга не является заменой классики в этой области, такой как Domain-Driven Design Эрика Эванса или Patterns of Enterprise Application Architecture Мартина Фаулера (оба опубликованы Addison-Wesley Professional), на которые мы часто ссылаемся и призываем вас пойти и прочитать.
Но все классические примеры кода в литературе, как правило, написаны на Java или C++/#, и если вы человек из рядов Python и не использовали ни один из этих языков в течение длительного времени (или вообще никогда), то эти листинги кода могут быть довольно…трудными. Видимо это и есть причина, по которой последнее издание другого классического текста, Fowler’s Refactoring (Addison-Wesley Professional), написано в JavaScript.
TDD, DDD, и Event-Driven Architecture
В порядке популярности назовём три инструмента для управления сложностью:
-
Test-driven development (TDD) Разработка на основе тестов. Помогает нам создавать правильный код и проводить рефакторинг или добавлять новые функции, не опасаясь регресса. Но бывает сложно извлечь максимальную пользу из наших тестов: как сделать так, чтобы они выполнялись как можно быстрее? Чтобы мы получили как можно более качественное покрытие и обратную связь от быстрых модульных тестов без зависимостей (dependency-free unit tests) и имели минимальное количество более медленных, нестабильных сквозных (end-to-end) тестов?
-
Domain-driven design (DDD) Разработка на основе поведения. Просит нас сосредоточить наши усилия на построении хорошей модели бизнес-сферы, но как мы можем убедиться, чтобы наши модели не были обременены инфраструктурными проблемами и их не было трудно изменить?
-
Loose coupling Слабосвязанные (микросервисы), интегрированные через сообщения (иногда называемые reactive microservices), являются хорошо зарекомендовавшим себя решением проблемы управления сложностью в нескольких приложениях или бизнес-доменах. Но не всегда очевидно, как сделать так, чтобы они соответствовали широко распространённым инструментам мира Python-Flask, Django, Celery и так далее.
| Не пугайтесь, если вы не работаете с микросервисами (или не заинтересованы в них). Подавляющее большинство моделей, которые мы обсудим, включая большую часть материалов событийной архитектуры, абсолютно применимы в монолитной архитектуре. |
Наша цель в этой книге-представить несколько классических архитектурных моделей и показать, как они поддерживают TDD, DDD и event-driven сервисы. Мы надеемся, что он послужит ориентиром для их реализации в питоническом ключе, и что люди смогут использовать его в качестве первого шага к дальнейшим исследованиям в этой области.
Кому следует прочитать эту книгу
Вот несколько мыслей, которые мы предполагаем справедливо сказать о тебе, дорогой читатель:
-
Ты был близок к некоторым достаточно сложным приложениям Python.
-
Ты видел, а может сам испытал ту боль, которая приходит вместе с попыткой справиться с этой сложностью.
-
Ты не обязательно знаешь что-либо о DDD или любом из классических шаблонов архитектуры приложений.
Мы структурируем наши исследования архитектурных паттернов вокруг примера приложения, выстраивая его главу за главой. Мы используем TDD в работе, поэтому обычно сначала показываем списки тестов, а затем их реализацию. Если вы не привыкли работать с тестом, сначала это может показаться немного странным, но мы надеемся, что вы скоро привыкнете видеть код "используемым" (то есть снаружи), прежде чем увидите, как он построен внутри.
Мы используем некоторые специфические фреймворки и технологии Python, включая Flask, SQLAlchemy и pytest, а также Docker и Redis. Если вы уже знакомы с ними, то это не повредит, но вряд ли это необходимо. Одной из наших главных целей в этой книге является построение архитектуры, для которой конкретные технологические решения становятся второстепенными деталями реализации.
Краткий обзор того, что будет дальше
Книга разделена на две части; Вот некоторые темы, которые мы рассмотрим, и главы, в которых они живут.
#Часть1
- Domain modeling и DDD (Chapters 1, 2 и 7)
-
На каком-то уровне каждый усвоил урок, что сложные бизнес-задачи должны быть отражены в коде, в виде модели предметной области. Но почему всегда кажется, что это так трудно сделать, не запутавшись в инфраструктурных проблемах, наших веб-фреймворках или чем-то еще? В первой главе мы даем широкий обзор domain modeling и DDD, а также показываем, как начать работу с моделью, которая не имеет внешних зависимостей и быстрых модульных тестов. Позже мы вернемся к шаблонам DDD, чтобы обсудить, как выбрать правильный агрегат и как этот выбор связан с вопросами целостности данных.
- Repository, Service Layer, и Unit of Work patterns (Chapters 2, 4, и 5)
-
В этих трех главах мы представляем три тесно связанных и взаимно усиливающих друг друга паттерна, которые поддерживают наше стремление сохранить модель свободной от посторонних зависимостей. Мы выстроим слой абстракции вокруг постоянного хранилища, и уровень сервиса, чтобы определить точки входа в нашу систему и захватить основные варианты использования. Мы покажем, как этот слой позволяет легко создавать тонкие точки входа в нашу систему, будь то API Flask или CLI (Command Line Interface - Интерфейс командной строки).
- Некоторые соображения о тестировании и абстракциях (Chapter 3 и 5)
-
После представления первой абстракции (паттерна Repository) воспользуемся возможностью для общего обсуждения того, как выбирать абстракции и какова их роль в выборе того, как наше программное обеспечение связано друг с другом. После знакомства с шаблоном Service Layer, немного поговорим о построении test pyramid и написании модульных тестов на максимально возможном уровне абстракции.
#Часть2
- Архитектура, управляемая событиями (Chapters 8-11)
-
Мы вводим еще три взаимно усиливающих шаблона: Domain Events, Message Bus, и Handler patterns. События домена (Domain Events)-это средство передачи идеи о том, что некоторые взаимодействия с системой являются триггерами для других. Мы используем шину сообщений Message Bus, чтобы позволить действиям вызывать события и вызывать соответствующие handlers (обработчики). Мы переходим к обсуждению того, как события могут быть использованы в качестве шаблона для интеграции между службами в архитектуре микросервисов. Наконец, мы различаем команды и события. Наше приложение теперь по сути является системой обработки сообщений.
- Разделение ответственности по командам и запросам (Command-Query Responsibility Segregation (CQRS)[1])
-
Мы приводим пример разделения ответственности команд-запросов с событиями и без событий.
- Инъекция зависимостей (Dependency Injection (и Bootstrapping))
-
Мы приводим в порядок наши явные и неявные зависимости и реализуем простую структуру внедрения зависимостей.
Дополнительный контент
Как мне попасть туда отсюда?[3] (Эпилог):: Реализация архитектурных шаблонов всегда выглядит легко, когда вы показываете простой пример, начиная с нуля, но многие из вас, вероятно, зададутся вопросом, как применить эти принципы к существующему программному обеспечению. Мы дадим несколько указаний в эпилоге и некоторые ссылки для дальнейшего чтения.
Примеры кода и совместное кодирование
Постепенно читая эту книгу вы, вероятно, согласитесь с нами, когда мы скажем, что лучший способ узнать о коде — это код. Большую часть того, что мы знаем, мы узнали из общения с людьми, совместного написания кода с ними и обучения на практике, и мы хотели бы воссоздать этот опыт для вас как можно точнее в этой книге.
В результате мы построили книгу на примере одного проекта (хотя иногда мы приводим и другие примеры). Мы будем развивать этот проект по мере продвижения глав, как если бы вы были в паре с нами, и мы объясняем, что мы делаем и почему на каждом этапе.
Но чтобы по-настоящему разобраться с этими шаблонами, вам нужно повозиться с кодом и почувствовать, как он работает. Вы найдете весь код на GitHub; у каждой главы есть своя ветка. Вы также можете найти список веток на GitHub.
Вот три способа кодирования вместе с книгой:
-
Начните свой собственное репозиторий и попробуйте создать приложение, как это делаем мы, следуя примерам из листингов в книге и время от времени заглядывая в наше репо за подсказками. Однако предупреждаю: если вы читали предыдущую книгу Гарри и кодировали вместе с ней, вы обнаружите, что эта книга требует от вас проявить больше самостоятельности; вам, возможно, придется сильно полагаться на рабочие версии на GitHub.
-
Попробуйте применить каждый шаблон, главу за главой, к вашему собственному (желательно маленькому/игрушечному) проекту и посмотрите, сможете ли вы заставить его работать для вашего варианта использования. Высокий риск/высокая награда (и, кроме того, достаточные усилия!). Возможно придётся изрядно попотеть, чтобы заставить какие то вещи работать в соответствии со спецификой вашего проекта, но, с другой стороны, вероятно вы, узнаете много полезного.
-
В каждой главе мы описываем "Упражнение для читателя" и даём ссылки на GitHub, где вы можете скачать частично готовый код для главы с несколькими недостающими частями, чтобы написать его самостоятельно.
Особенно если вы намереваетесь применить некоторые из этих паттернов в своих собственных проектах, работа с простым примером-отличный способ безопасно практиковаться.
| По крайней мере, выполняйте «git checkout» кода из нашего репозитория при чтении каждой главы. Возможность сразу же увидеть код в контексте реального работающего приложения поможет ответить на множество вопросов по ходу дела и сделает все более реальным. Вы найдете инструкции, как это сделать, в начале каждой главы. |
Лицензия
Код (и онлайн-версия книги) находится под лицензией Creative Commons CC BY-NC-ND, что означает, что вы можете свободно копировать и делиться им с кем угодно в некоммерческих целях при условии указания авторства. Если вы хотите повторно использовать какой-либо контент из этой книги и у вас есть какие-либо опасения по поводу лицензии, свяжитесь с O’Reilly permissions@oreilly.com.
Печатное издание лицензируется по-другому; см. страницу об авторских правах.
Условные обозначения, используемые в этой книге
В этой книге используются следующие типографские условные обозначения:
- Курсив
-
Указывает новые термины, URL-адреса, адреса электронной почты, имена файлов и расширения файлов.
- Постоянная ширина
-
Используется для листинга программ, а также в абзацах для обозначения программных элементов, таких как имена переменных или функций, базы данных, типы данных, переменные среды, операторы и ключевые слова.
Постоянная ширина жирный шрифт-
Показывает команды или другой текст, который должен быть набран буквально пользователем.
- Курсив постоянной ширины
-
Показывает текст, который должен быть заменен пользовательскими значениями или значениями, определяемыми контекстом.
|
Этот элемент означает подсказку или предложение. |
|
Этот элемент обозначает общее примечание. |
|
Этот элемент указывает на предупреждение или предостережение. |
Онлайн-обучение O’Reilly
|
Более 40 лет O’Reilly Media предоставляет технологии и бизнес-тренинги, знания и идеи, чтобы помочь компаниям добиться успеха. |
Наша уникальная сеть экспертов и новаторов делится своими знаниями и опытом с помощью книг, статей, конференций и нашей онлайн-платформы обучения. Платформа онлайн-обучения O’Reilly предоставляет вам доступ по требованию к живым учебным курсам, углубленным учебным путям, интерактивным средам кодирования и обширной коллекции текстов и видео от O’Reilly и более чем 200 других издателей. Для получения дополнительной информации, пожалуйста, посетите сайт http://oreilly.com.
Как связаться с O’Reilly
Пожалуйста, направляйте комментарии и вопросы, касающиеся этой книги, издателю:
- O’Reilly Media, Inc.
- 1005 Gravenstein Highway North
- Sebastopol, CA 95472
- 800-998-9938 (in the United States or Canada)
- 707-829-0515 (international or local)
- 707-829-0104 (fax)
У нас есть веб-страница для этой книги, где мы перечисляем ошибки, примеры и любую дополнительную информацию. Вы можете получить доступ к этой странице по адресу https://oreil.ly/architecture-patterns-python.
Email bookquestions@oreilly.com для комментариев и технических вопросов по этой книге.
Для получения дополнительной информации о наших книгах, курсах, конференциях и новостях посетите наш веб-сайт по адресу http://www.oreilly.com.
Найдите нас на Facebook: http://facebook.com/oreilly
Следите за нами в Twitter: http://twitter.com/oreillymedia
Смотрите нас на YouTube: http://www.youtube.com/oreillymedia
Благодарности
Нашим техническим обозревателям Дэвиду Седдону, Эду Юнгу и Хайнеку Шлаваку: мы абсолютно не заслуживаем вас. Вы все невероятно преданные, добросовестные и строгие. Каждый из вас безмерно умен, и ваши разные точки зрения были полезны и дополняли друг друга. Спасибо вам от всего сердца.
Огромное спасибо всем нашим читателям за их комментарии и предложения: Йен Купер, Абдулла Арифф, Джонатан Мейер, Гил Гонсалвес, Матье Чоплин, Бен Джадсон, Джеймс Грегори, Лукаш Лехович, Клинтон Рой, Виторино Араужо, Сьюзан Гудбоди, Джош Харвуд, Дэниел Батлер, Лю Хайбин, Джимми Вергиа Игнасиа Игнас Канестрани, Ренне Роча, Педроаби, Ашиа Завадук, Йостейн Лейра, Брэндон Роудс, Язепс Баско, Симкимсия, Адриен Брюнет и многие другие; приносим свои извинения, если мы пропустили Вас в этом списке.
Супер-мега-спасибо нашему редактору Корбину Коллинзу за его нежное щебетание и за то, что он неутомимый защитник читателя. В такой же степени выражаем благодарность производственному персоналу Кэтрин Тозер, Шэрон Уилки, Эллен Траутман-Заиг и Ребекке Демарест за вашу преданность делу, профессионализм и внимание к деталям. Эта книга неизмеримо улучшена благодаря вам.
Любые ошибки, оставшиеся в книге, естественно, являются нашими собственными.
Введение
Почему Наш Дизайн Такой НЕУДАЧНЫЙ?
Что приходит на ум, когда вы слышите слово хаос? Возможно, вы думаете о шумной фондовой бирже или о своей кухне по утрам — все запутано и перемешано. Когда вы думаете о слове порядок, возможно, вы думаете о пустой комнате, безмятежной и спокойной. Однако для ученых хаос характеризуется однородностью (sameness), а порядок — сложностью (difference).
Например, ухоженный сад — это упорядоченная система. Садоводы определяют границы дорожками и забором, размечают клумбы или грядки. Со временем сад развивается, становясь все богаче и гуще; но без целенаправленных усилий сад разрастётся. Сорняки и травы будут заглушать другие растения, покрывая дорожки, пока в конце концов все их части не станут снова такими же — дикими и неуправляемыми.
Программные системы тоже склонны к хаосу. Когда мы впервые начинаем строить новую систему, у нас есть грандиозные идеи, что наш код будет чистым и хорошо упорядоченным, но со временем мы обнаруживаем, что он включает ненужные и оборванные элементы кода и заканчивается запутанной трясиной менеджеров классов и утилитных модулей. Мы обнаруживаем, что наша разумная многослойная архитектура рухнула сама по себе, как какая то безделушка. Хаотические программные системы характеризуются одинаковостью функций: обработчики API, которые знают предметную область и отправляют электронную почту и выполняют регистрацию; классы «бизнес-логики», которые не выполняют вычислений, но выполняют ввод-вывод; и все вместе со всем остальным, так что изменение любой части системы чревато опасностью. Это настолько распространено, что у разработчиков программного обеспечения есть собственный термин для обозначения хаоса: антипаттерн "the Big Ball of Mud" (Большой шар грязи или нелитературно по русски говнокод :) ) (Схема зависимостей из реальной жизни (source: "Enterprise Dependency: Big Ball of Yarn" by Alex Papadimoulis)).

| Говнокод — естественное состояние программного обеспечения, так же как болезнь — естественное состояние вашего сада. Чтобы предотвратить коллапс, нужны энергия и направление. |
К счастью, методы, позволяющие избежать этого, не сложны.
Инкапсуляции и абстракции
Инкапсуляция и абстракция — это инструменты, к которым мы все как программисты инстинктивно стремимся, даже если не все используем именно эти слова. Позвольте нам ненадолго остановиться на них, поскольку они являются постоянной фоновой темой книги.
Термин инкапсуляция охватывает две тесно связанные идеи: упрощение поведения и скрытие данных. В этом обсуждении мы используем первое. Мы инкапсулируем поведение, определяя задачу, которую необходимо выполнить в нашем коде, и передаём эту задачу четко определенному объекту или функции. И называем этот объект или функцию абстракцией.
Взгляните на следующие два фрагмента кода Python:
import json
from urllib.request import urlopen
from urllib.parse import urlencode
params = dict(q='Sausages', format='json')
handle = urlopen('http://api.duckduckgo.com' + '?' + urlencode(params))
raw_text = handle.read().decode('utf8')
parsed = json.loads(raw_text)
results = parsed['RelatedTopics']
for r in results:
if 'Text' in r:
print(r['FirstURL'] + ' - ' + r['Text'])import requests
params = dict(q='Sausages', format='json')
parsed = requests.get('http://api.duckduckgo.com/', params=params).json()
results = parsed['RelatedTopics']
for r in results:
if 'Text' in r:
print(r['FirstURL'] + ' - ' + r['Text'])Оба кода делают одно и то же: они отправляют закодированные в форме значения на URL-адрес, чтобы использовать API поисковой системы. Но второе проще читать и понимать, потому что оно работает на более высоком уровне абстракции.
Мы можем сделать еще один шаг вперед, определив и назвав задачу, которую нам хотелось бы, чтобы код выполнял для нас, и используем еще более высокоуровневую абстракцию, чтобы сделать ее явной:
import duckduckpy
for r in duckduckpy.query('Sausages').related_topics:
print(r.first_url, ' - ', r.text)Инкапсуляция поведения с помощью абстракций-это мощный инструмент для того, чтобы сделать код более выразительным, более тестируемым и более простым в обслуживании.
| В литературе, посвященной объектно-ориентированному (ОО) миру, одна из классических характеристик этого подхода называется responsibility-driven design; в нем используются слова roles (роли) и responsibilities (обязанности), а не tasks (задачи). Главное — думать о коде с точки зрения поведения, а не с точки зрения данных или алгоритмов.[4] |
Большинство шаблонов в этой книге связаны с выбором абстракции, поэтому вы увидите множество примеров в каждой главе. Кроме того, Краткая интерлюдия: О Связях и Абстракции конкретно обсуждает некоторые общие эвристики для выбора абстракций.
Многоуровневое представление
Инкапсуляция и абстракция помогают нам скрывать детали и защищать целостность наших данных, но нам также необходимо помнить о взаимодействии между нашими объектами и функциями. Когда одна функция, модуль или объект использует другую, мы говорим, что одна depends on (зависима) от другой. Эти зависимости образуют своего рода сеть или граф.
В большом комке грязи зависимости выходят из-под контроля (как вы видели в Схема зависимостей из реальной жизни (source: "Enterprise Dependency: Big Ball of Yarn" by Alex Papadimoulis)). Изменение одного узла графа становится затруднительным, поскольку оно может повлиять на многие другие части системы. Слоистые архитектуры являются одним из способов решения этой проблемы. В многоуровневой архитектуре мы разделяем наш код на отдельные категории или роли и вводим правила касающеся того, какие категории кода могут вызывать друг друга.
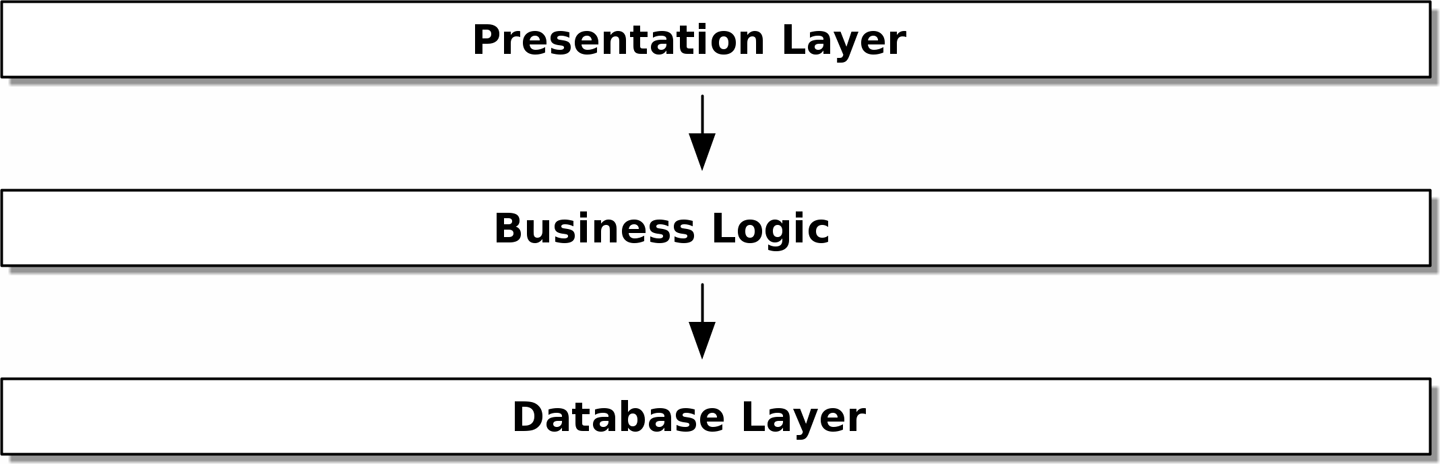
Одним из наиболее распространенных примеров является трехслойная архитектура, показанная на рис. Многоуровневая архитектура.
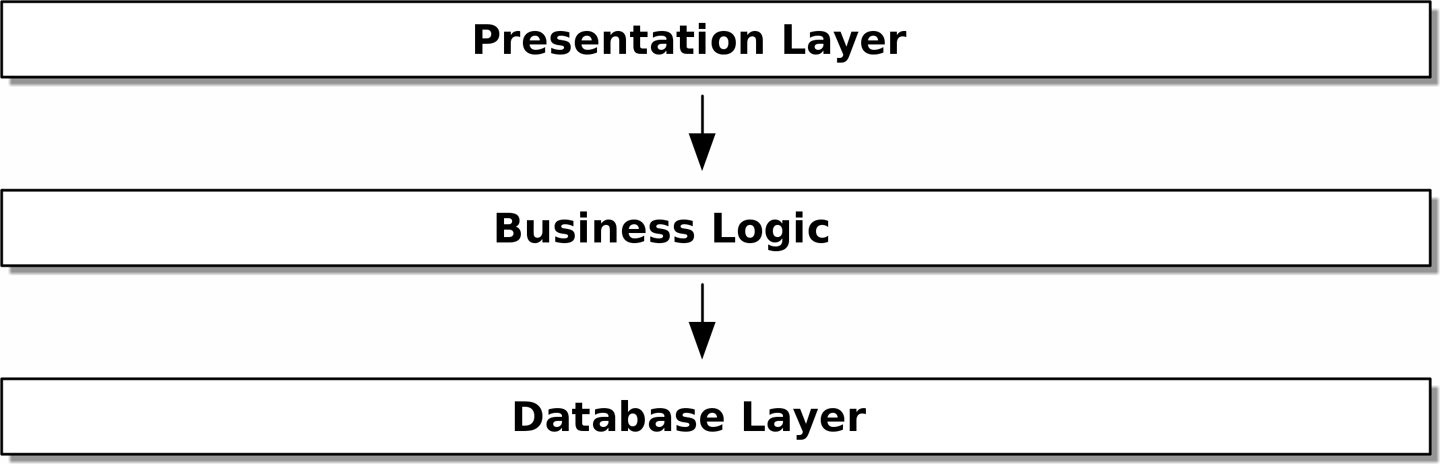
[ditaa, apwp_0002]
+----------------------------------------------------+
| Уровень представления |
+----------------------------------------------------+
|
V
+----------------------------------------------------+
| Бизнес-логика |
+----------------------------------------------------+
|
V
+----------------------------------------------------+
| Уровень базы данных |
+----------------------------------------------------+
Многоуровневая архитектура является, пожалуй, наиболее распространенным шаблоном для построения business software — коммерческого ПО. В этой модели у нас есть компоненты пользовательского интерфейса, которые могут быть веб-страницей, API или командной строкой; эти компоненты пользовательского интерфейса взаимодействуют со слоем бизнес-логики, который содержит наши бизнес-правила и наши рабочие процессы; и, наконец, у нас есть уровень базы данных, который отвечает за хранение и извлечение данных.
До конца этой книги мы будем систематически выворачивать эту модель наизнанку, следуя одному простому принципу.
The Dependency Inversion Principle (Принцип инверсии зависимостей)
Возможно, вы уже знакомы с принципом инверсии зависимостей (DIP), потому что это D в SOLID. [5]
К сожалению, мы не можем проиллюстрировать DIP, используя три небольших листинга кода, как мы это делали для инкапсуляции. Однако вся [Часть1] по сути представляет собой отработанный пример реализации DIP во всем приложении, так что вы получите множество конкретных примеров.
А пока можно поговорить о формальном определении DIP:
-
Модули высокого уровня не должны зависеть от модулей низкого уровня. И то и другое должно зависеть от абстракций.
-
Абстракции не должны зависеть от деталей. Вместо этого детали должны зависеть от абстракций.
Но что это значит? Давайте разберемся по крупицам.
Модули высокого уровня это код, который действительно волнует вашу организацию. Возможно, вы работаете в фармацевтической компании, и ваши высокоуровневые модули имеют дело с пациентами и испытаниями. Возможно, вы работаете в банке, и ваши высокоуровневые модули управляют сделками и биржами. Высокоуровневые модули программной системы-это функции, классы и пакеты, которые имеют дело с нашими концепциями реального мира.
Напротив, низкоуровневые модули — это код, который вашей организации не важен. Маловероятно, что ваш отдел кадров будет в восторге от файловых систем или сетевых сокетов. Нечасто вы обсуждаете SMTP, HTTP или AMQP со своим финансовым отделом. Для наших нетехнических заинтересованных сторон эти низкоуровневые концепции не интересны и не актуальны. Все, что их волнует, — это правильность работы высокоуровневых концепций. Если расчет заработной платы выполняется вовремя, вашему бизнесу вряд ли будет важно, выполняется ли это задание cron или временная функция, выполняемая в Kubernetes.
Depends on (зависит от) не обязательно означает imports или calls, а скорее несёт более общую идею о том, что один модуль knows about (знает о) или needs (нуждается в) другом модуле.
И мы уже упоминали abstractions: это упрощенные интерфейсы, которые инкапсулируют поведение, подобно тому, как наш модуль duckduckgo инкапсулирует API поисковой системы.
Все проблемы в информатике можно решить, добавив еще один косвеный уровень.
Итак, первая часть DIP говорит, что наш бизнес и код не должны зависеть от технических деталей; вместо этого оба должны использовать абстракции.
Почему? Говоря по простому: мы хотим иметь возможность изменять их независимо друг от друга. Модули высокого уровня должны быть легко изменены в соответствии с потребностями бизнеса. Низкоуровневые модули (детали) часто на практике сложнее изменить: подумайте о рефакторинге для изменения имени функции по сравнению с определением, тестированием и развертыванием миграции базы данных для изменения имени столбца. Мы не хотим, чтобы изменения бизнес-логики замедлялись, потому что они тесно связаны с деталями инфраструктуры низкого уровня. Но точно так же важно иметь возможность изменять детали инфраструктуры, когда это необходимо (например, подумайте о сегментировании базы данных), без необходимости вносить изменения в бизнес-уровень. Добавление абстракции между ними (знаменитый дополнительный слой косвенности) позволяет им изменяться (более) независимо друг от друга.
Вторая часть еще более загадочна. «Абстракции не должны зависеть от деталей» кажется достаточно ясным, но «Детали должны зависеть от абстракций» трудно себе представить. Как мы можем получить абстракцию, которая не зависит от деталей, которые она абстрагирует? К тому времени, когда мы дойдем до Наш первый Use Case или пример использования: Flask API и Service Layer, у нас будет конкретный пример, который должен прояснить все это.
Место для Всей Нашей Бизнес-логики: Модель Предметной Области (The Domain Model)
Но прежде чем мы сможем вывернуть нашу трехуровневую архитектуру наизнанку, нам нужно больше поговорить об этом среднем слое: высокоуровневых модулях или бизнес-логике. Одна из наиболее распространенных причин, по которой наши проекты идут "как-то не так", заключается в том, что бизнес-логика распространяется по всем слоям нашего приложения, что затрудняет ее идентификацию, понимание и изменение.
Domain Modeling показывает, как построить бизнес-уровень с помощью шаблона Domain Model. Остальные шаблоны в Построение архитектуры на основе поддержки модели предметной области показывают, как мы можем сохранить модель предметной области легко изменяемой и свободной от низкоуровневых проблем, выбирая правильные абстракции и постоянно применяя DIP.
1. Построение архитектуры на основе поддержки модели предметной области
Большинство разработчиков никогда не видели модель предметной области (domain model), только модель данных(data model).
DDD EU 2017
Большинство разработчиков, с которыми мы говорим об архитектуре, испытывают мучительное предчувствие, что все можно сделать лучше. И часто пытаясь спасти систему, которая каким-то образом вышла из строя, пытаются ввернуть какую-то структуру в "комок грязи". Они знают, что их бизнес-логика не должна распространяться повсюду, но они не знают, как это исправить.
Мы обнаружили, что многие разработчики, когда их просят спроектировать новую систему, немедленно приступают к построению схемы базы данных, а объектная модель рассматривается как нечто запоздалое. Вот тут-то все и начинает идти наперекосяк. Вместо этого поведение должно стоять на первом месте и определять наши требования к хранилищу. В конце концов, наших клиентов не волнует модель данных. Их волнует, что делает система.; в противном случае они просто использовали бы электронную таблицу.
Первая часть книги посвящена тому, как построить богатую объектную модель с помощью TDD (в Domain Modeling), а затем рассмотрим, как уберечь эту модель от технических проблем. Покажем, как создавать код, игнорирующий персистентность, и как создавать стабильные API-интерфейсы вокруг нашего домена, чтобы мы могли проводить агрессивный рефакторинг.
Для этого мы представляем четыре ключевых шаблона проектирования:
-
Repository pattern, абстракция над идеей постоянного хранения
-
Шаблон Service Layer четко определяет, где начинаются и заканчиваются наши варианты использования
-
Unit of Work pattern для обеспечения атомарных операций
-
Aggregate pattern для обеспечения целостности наших данных
Если вам нужна картина того, куда мы в итоге придем, взгляните на Диаграмма компонентов для нашего приложения в конце Построение архитектуры на основе поддержки модели предметной области, но не волнуйтесь, если для вас все эта графика не имеет смысла! Мы разберём каждую фигуру изображенную на рисунке, одну за другой, на протяжении всей этой части книги.
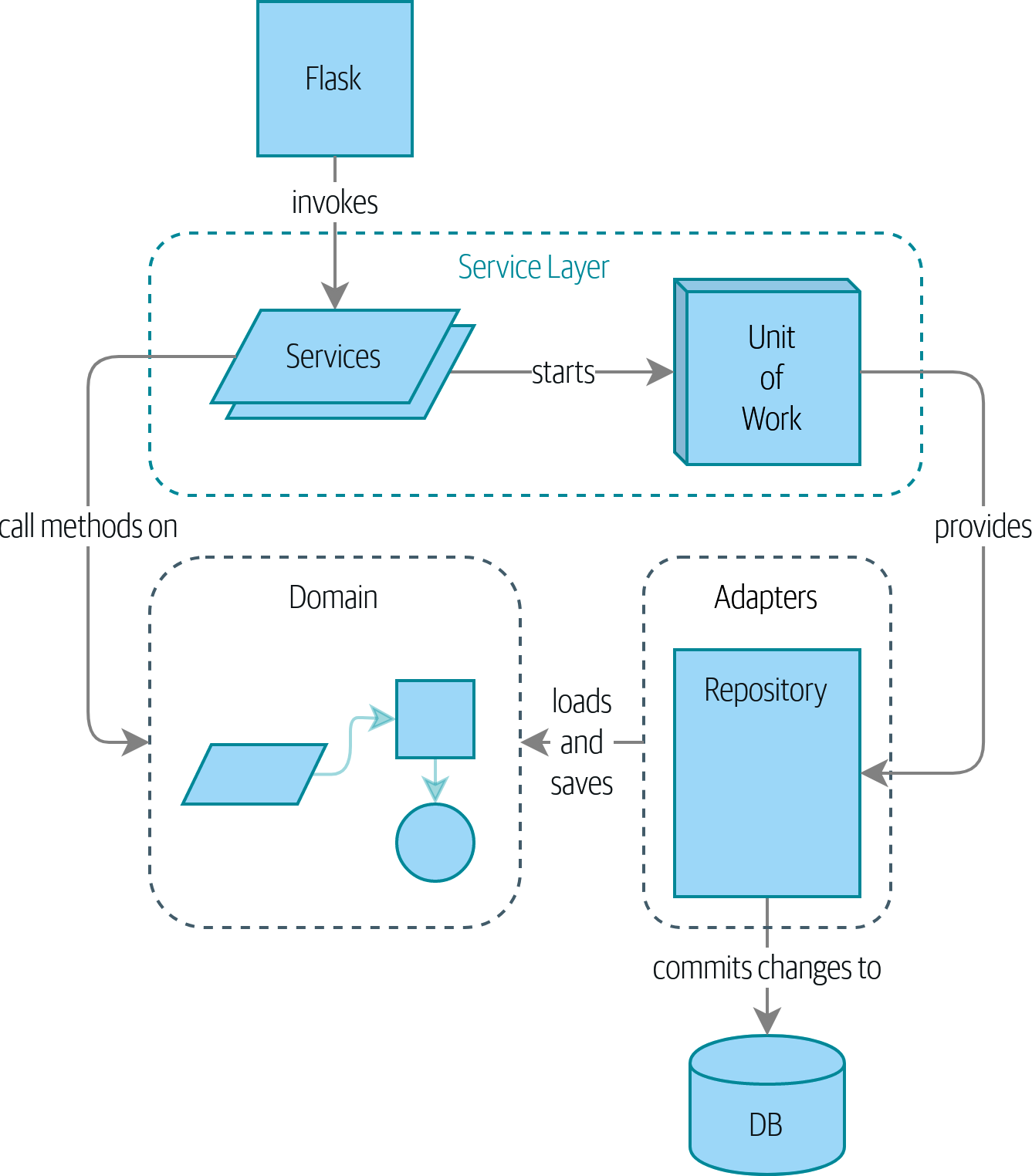
Мы также уделим немного времени, чтобы поговорить о coupling and abstractions, проиллюстрировав это на простом примере, который показывает, как и почему мы выбираем наши абстракции.
Три приложения являются дальнейшими целями исследованиями содержания Части I:
-
Шаблонная структура проекта это описание инфраструктуры для нашего примера кода: как мы строим и запускаем образы Docker, где мы управляем информацией о конфигурации и как мы запускаем различные типы тестов.
-
Замена инфраструктуры: Делайте все с CSV это своего рода контент типа "proof is in the pudding", показывающий, как легко поменять всю нашу инфраструктуру—API Flask, ORM и Postgres-на совершенно другую модель ввода-вывода, включающую CLI и CSV.
-
Наконец, [appendix_django] может представлять интерес, если вам интересно, как эти паттерны могут выглядеть при использовании Django вместо Flask и SQLAlchemy.
2. Domain Modeling
В этой главе рассматривается, как можно моделировать бизнес-процессы с помощью кода таким образом, чтобы он был полностью совместим с TDD (Test Driven Development). Обсудим, почему моделирование домена имеет важное значение, и рассмотрим несколько ключевых шаблонов для моделирования доменов: Entity, Value Object, и Domain Service.
Иллюстрация прототипа нашей модели предметной области (Domain Model) это простое визуальное представление для нашего шаблона Domain Model. В этой главе мы расскажем о некоторых деталях, а когда перейдем к другим главам, то построим все вокруг Domain Model, но вы всегда должны быть в состоянии найти эти маленькие формы в центре.
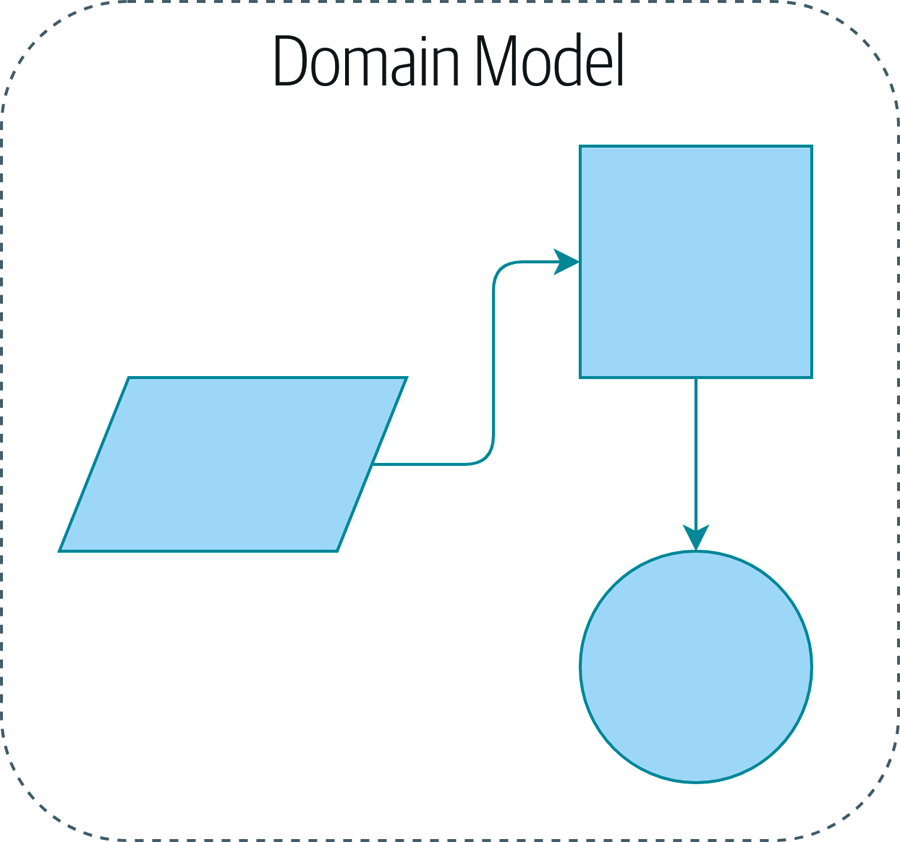
2.1. Что такое Domain Model?
В introduction мы использовали термин business logic layer для описания центрального слоя трехслойной архитектуры. Для остальной части книги будем использовать термин domain model. Это термин из методологии Domain Driven Design (DDD), который лучше улавливает наш предполагаемый смысл (подробнее о DDD читайте дальше).
domain — причудливый способ обозначить проблему, которую вы пытаетесь решить. В настоящее время ваши авторы работают в мебельном интернет-магазине. В зависимости от того, о какой системе вы говорите, предметной областью может быть совершение разовых покупок и закупка по долгосрочным договорам, дизайн продукта или логистика и доставка. Большинство программистов проводят свои дни в попытках улучшить или автоматизировать бизнес-процессы; домен является набором действий, которые поддерживают эти процессы.
model — карта процесса или явления, которая фиксирует полезное свойство. Люди исключительно хороши в производстве моделей вещей в их головах. Например, когда кто-то бросает в вас мяч, вы можете предсказать его движение почти бессознательно, потому что у вас есть модель движения объектов в пространстве. Ваша модель ни в коем случае не идеальна. У людей есть ужасные интуитивные представления о том, как объекты ведут себя на околосветовых скоростях или в вакууме, потому что наша модель никогда не предназначалась для этих случаев. Это не означает, что модель неверна, но это означает, что некоторые прогнозы выходят за рамки её области.
Модель предметной области — это ментальная карта, которую владельцы бизнеса вешают у себя на стене в кабинете и которая отображает их мысли о структуре их бизнеса. У всех деловых людей есть эти ментальные карты — это изображене мыслей этих людей о сложных процессах.
Вы можете сразу определить, когда они ориентируются по этим картам, потому что они используют деловой язык. Жаргон возникает естественным образом среди людей, которые сотрудничают в сложных системах.
Представьте себе, что вы, наш несчастный читатель, внезапно перенеслись за много световых лет от Земли на борту инопланетного космического корабля со своими друзьями и семьей и должны выяснить, исходя из первых принципов, как вернуться домой.
В первые несколько дней вы наверное будете просто нажимать кнопки случайным образом, но вскоре разберётесь, какие кнопки что делают и сможете давать друг другу инструкции. "Нажми красную кнопку возле мигающей штуковины, а затем пребрось этот большой рычаг рядом с радарной хреновиной", — скажете вы.
Через пару недель вы станете более точными, определив слова для описания функций корабля: "Увеличить уровень кислорода в третьем грузовом отсеке" или "включите дополнительные двигатели." Через несколько месяцев вы бы придумали язык для целых сложных процессов: "Начать программу посадки " или "приготовиться к перегрузке." Этот процесс происходил бы совершенно естественно, без каких-либо формальных усилий по созданию общего глоссария.
Так и в обычном мире бизнеса. Терминология, используемая заинтересованными сторонами бизнеса, представляет собой дистиллированное понимание модели предметной области, где сложные идеи и процессы сводятся к одному слову или фразе.
Когда мы слышим, как наши деловые партнеры используют незнакомые слова или используют термины определенным образом, мы должны слушать, чтобы понять более глубокий смысл и закодировать их с трудом завоеванный опыт в наше программное обеспечение.
В этой книге мы будем использовать модель предметной области реального мира, в частности модель из нашей текущей работы. MADE.com является успешным мебельным ритейлером. Мы поставляем нашу мебель от производителей по всему миру и продаем её по всей Европе.
Когда вы покупаете диван или журнальный столик, мы должны решить, как лучше всего доставить ваш товар из Польши, Китая или Вьетнама в вашу гостиную.
На высоком уровне у нас есть отдельные системы, которые отвечают за покупку акций, продажу акций клиентам и доставку товаров клиентам. Система в середине должна координировать процесс, распределяя запасы по заказам клиента; см. Контекстная диаграмма для службы распределения.
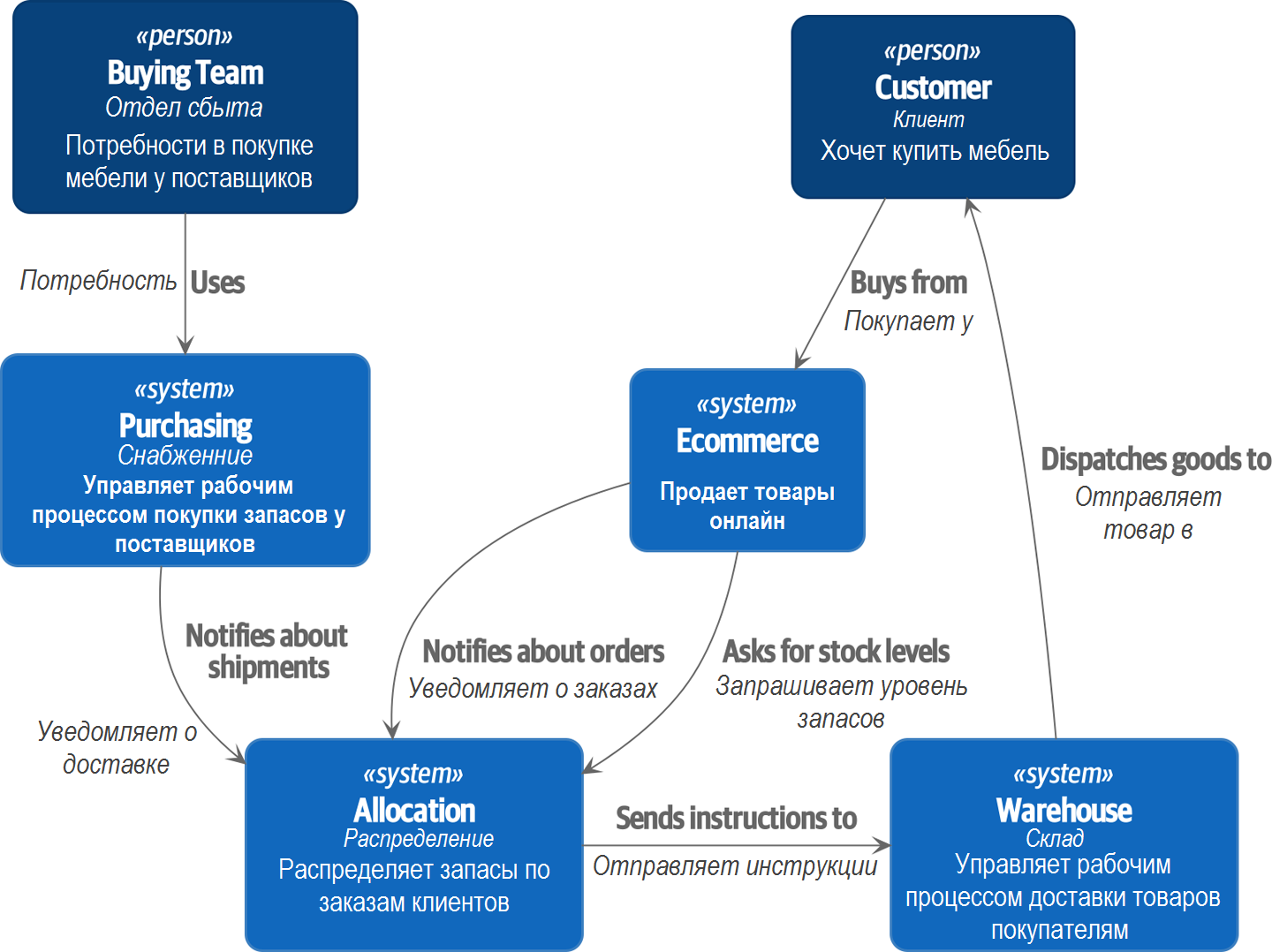
[plantuml, apwp_0102] @startuml Allocation Context Diagram !include https://raw.githubusercontent.com/plantuml-stdlib/C4-PlantUML/master/C4_Container.puml scale 2 System(systema, "Allocation", "Распределяет запасы по заказам клиентов") Person(customer, "Customer", "Хочет купить мебель") Person(buyer, "Buying Team", "Формирует заявку на закупку мебели у поставщиков") System(procurement, "Совершает закупку") , "Управляет рабочим процессом покупки запасов у поставщиков") System(ecom, "Ecommerce", "Продает товары онлайн") System(warehouse, "Warehouse", "Управляет рабочим процессом доставки товаров покупателям") Rel(buyer, procurement, "Использует") Rel(procurement, systema, "Notifies about shipments (Уведомляет о доставке)") Rel(customer, ecom, "Buys from (Покупает у)") Rel(ecom, systema, "Asks for stock levels (Запрашивает уровень запасов)") Rel(ecom, systema, "Notifies about orders (Уведомляет о заказах)") Rel_R(systema, warehouse, "Sends instructions to (Отправляет инструкции)") Rel_U(warehouse, customer, "Dispatches goods to (Отправляет товар в)") @enduml
В рамках этой книги, пофантазируем, что фирма решает внедрить новый способ распределения запасов. До сих пор компания представляла товар и время выполнения заказа на основе того, что физически доступно на складе. Если и вдруг склад пустеет, продукт считается "отсутствующим на складе" до тех пор, пока не поступит следующая партия от производителя.
Новая идея такова: если у нас есть система, которая может отслеживать все наши поставки и когда они должны прибыть, мы можем рассматривать товары на этих кораблях как реальные запасы и часть нашего инвентаря, просто с немного более длительным временем выполнения заказа. Не смотря на небольшие складские запасы, продавать будем больше, а бизнес сможет сэкономить деньги, уменьшив запасы на внутреннем складе.
Но распределение заказов больше не является тривиальным вопросом уменьшения одного количества в складской системе. Нам нужен более сложный механизм распределения. Время для некоторого моделирования предметной области.
2.2. Изучение языка предметной области
Понимание модели предметной области требует времени, терпения и заметок. Мы предварительно беседуем с нашими бизнес-экспертами и договариваемся о глоссарии и некоторых правилах для первой минимальной версии модели предметной области. Там, где это возможно, мы просим привести конкретные примеры, иллюстрирующие каждое правило.
Мы уверены, чтобы выразить эти правила на бизнес-жаргоне (на ubiquitous language в DDD терминологии) надо выбрать запоминающиеся идентификаторы для наших объектов, чтобы было легче говорить на примерах.
следующий сайдбар показывает некоторые заметки, которые мы могли бы сделать во время разговора с нашими экспертами по предметной области Распределения.
2.3. Модульное тестирование доменных моделей
Мы не собираемся показывать вам, как работает TDD в этой книге, но мы хотим показать вам, как мы могли бы построить модель из этого делового разговора.
Вот как может выглядеть один из наших первых тестов:
def test_allocating_to_a_batch_reduces_the_available_quantity():
batch = Batch("batch-001", "SMALL-TABLE", qty=20, eta=date.today())
line = OrderLine('order-ref', "SMALL-TABLE", 2)
batch.allocate(line)
assert batch.available_quantity == 18Название нашего модульного теста описывает поведение, которое мы хотим получить от системы, а имена классов и переменных, которые мы используем, взяты из делового жаргона. Мы могли бы показать этот код нашим нетехническим коллегам, и они согласились бы, что это правильно описывает поведение системы.
А вот и доменная модель, отвечающая нашим требованиям:
@dataclass(frozen=True) (1) (2)
class OrderLine:
orderid: str
sku: str
qty: int
class Batch:
def __init__(
self, ref: str, sku: str, qty: int, eta: Optional[date] (2)
):
self.reference = ref
self.sku = sku
self.eta = eta
self.available_quantity = qty
def allocate(self, line: OrderLine):
self.available_quantity -= line.qty (3)| 1 | OrderLine это неизменяемый класс данных без какого-либо поведения.[9] |
| 2 | Мы не показываем импорт в большинстве листингов кода, чтобы сохранить их в чистоте. Мы надеемся, что вы догадались, что это появилось здесь благодаря from dataclasses import dataclass; аналогично, typing.Optional и datetime.date. Если вы хотите что-то перепроверить, вы можете увидеть полный рабочий код для каждой главы в её ветке (например,
chapter_01_domain_model). |
| 3 | Аннотации типов по-прежнему вызывают споры в мире Python. Для моделей предметной области они иногда могут помочь прояснить или задокументировать ожидаемые аргументы, и люди с IDE часто благодарны за них. Вы можете решить, что цена, заплаченная с точки зрения удобочитаемости, слишком высока. |
Наша реализация здесь тривиальна: Batch просто декоратор! Берёт целое число available_quantity, и уменьшает это значение при резервровании товара в заказе. Мы написали кучу кода только для того, чтобы вычесть одно число из другого, но мы надеемся, что моделирование нашего домена точно окупится off.[10]
Давайте напишем несколько новых failing tests:
def make_batch_and_line(sku, batch_qty, line_qty):
return (
Batch("batch-001", sku, batch_qty, eta=date.today()),
OrderLine("order-123", sku, line_qty)
)
def test_can_allocate_if_available_greater_than_required():
large_batch, small_line = make_batch_and_line("ELEGANT-LAMP", 20, 2)
assert large_batch.can_allocate(small_line)
def test_cannot_allocate_if_available_smaller_than_required():
small_batch, large_line = make_batch_and_line("ELEGANT-LAMP", 2, 20)
assert small_batch.can_allocate(large_line) is False
def test_can_allocate_if_available_equal_to_required():
batch, line = make_batch_and_line("ELEGANT-LAMP", 2, 2)
assert batch.can_allocate(line)
def test_cannot_allocate_if_skus_do_not_match():
batch = Batch("batch-001", "UNCOMFORTABLE-CHAIR", 100, eta=None)
different_sku_line = OrderLine("order-123", "EXPENSIVE-TOASTER", 10)
assert batch.can_allocate(different_sku_line) is FalseЗдесь нет ничего неожиданного. Мы переработали наш набор тестов, чтобы не повторять одни и те же строки кода для создания партии товара (Batch) и позиции заказа (OrderLine) для одного и того же SKU; и мы написали четыре простых теста для нового метода can_allocate. Again, notice that the names we use mirror the language of our domain experts, and the examples we agreed upon are directly written into code.
Мы также можем реализовать это напрямую, написав can_allocate
метод Batch:
def can_allocate(self, line: OrderLine) -> bool:
return self.sku == line.sku and self.available_quantity >= line.qtyПока что мы можем управлять реализацией, просто увеличивая и уменьшая Batch.available_quantity, но когда мы перейдем к тестам deallocate(), мы будем вынуждены перейти к более интеллектуальному решению:
def test_can_only_deallocate_allocated_lines():
batch, unallocated_line = make_batch_and_line("DECORATIVE-TRINKET", 20, 2)
batch.deallocate(unallocated_line)
assert batch.available_quantity == 20В этом тесте мы assert-им, что deallocating (освобождение) строки из пакета не имеет никакого эффекта, если только пакет ранее не allocated (резервировал) эту позицию . Чтобы это сработало, наша Batch должна понять, какие позиции или строки были зарезервированы. Давайте посмотрим на реализацию:
class Batch:
def __init__(
self, ref: str, sku: str, qty: int, eta: Optional[date]
):
self.reference = ref
self.sku = sku
self.eta = eta
self._purchased_quantity = qty
self._allocations = set() # type: Set[OrderLine]
def allocate(self, line: OrderLine):
if self.can_allocate(line):
self._allocations.add(line)
def deallocate(self, line: OrderLine):
if line in self._allocations:
self._allocations.remove(line)
@property
def allocated_quantity(self) -> int:
return sum(line.qty for line in self._allocations)
@property
def available_quantity(self) -> int:
return self._purchased_quantity - self.allocated_quantity
def can_allocate(self, line: OrderLine) -> bool:
return self.sku == line.sku and self.available_quantity >= line.qtyOur model in UML показывает модель в UML.
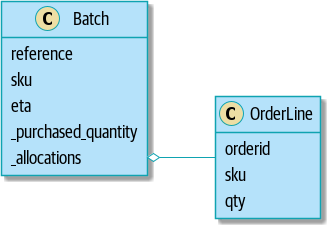
[plantuml, apwp_0103, config=plantuml.cfg]
@startuml
scale 4
left to right direction
hide empty members
class Batch {
reference
sku
eta
_purchased_quantity
_allocations
}
class OrderLine {
orderid
sku
qty
}
Batch::_allocations o-- OrderLine
Теперь мы кое-чего добились! Партия товара(Batch) теперь отслеживает набор выделенных(allocated) объектов OrderLine. Когда мы распределяем (allocate), если у нас достаточно свободного количества(available quantity), мы просто добавляем к набору. Наше available_quantity теперь является вычисляемым свойством: купленное количество минус выделенное количество.
Да, мы могли бы сделать еще много. Немного обескураживает то, что и allocate(), и deallocate() могут потерпеть неудачу без предупреждения, но основа у нас теперь есть.
Кстати, использование набора для ._allocations упрощает нам обработку последнего теста, потому что элементы в наборе уникальны:
def test_allocation_is_idempotent():
batch, line = make_batch_and_line("ANGULAR-DESK", 20, 2)
batch.allocate(line)
batch.allocate(line)
assert batch.available_quantity == 18На данный момент, вероятно, будет обоснованной критикой сказать, что модель предметной области слишком тривиальна, чтобы беспокоиться о DDD (или даже об объектной ориентации!). В реальной жизни возникает множество бизнес-правил и крайних случаев: клиенты могут запросить доставку в определенные будущие даты, а это означает, что мы можем не захотеть распределять их на самую раннюю партию. Некоторые SKU (артикулы) не выпускаются партиями, а заказываются по требованию непосредственно у поставщиков, поэтому у них другая логика. В зависимости от местоположения клиента мы можем выделить только подмножество складов и отгрузок, которые находятся в его регионе, за исключением некоторых SKU, которые мы с удовольствием доставляем со склада в другом регионе, если у нас нет запасов в домашнем регионе. And so on. Настоящий бизнес в реальном мире знает, как нагромождать сложности быстрее, чем мы можем показать на странице!
Но взяв эту простую модель предметной области в качестве заменителя чего-то более сложного, мы расширим нашу простую модель предметной области в остальной части книги и подключим её к реальному миру API, баз данных и электронных таблиц. Мы увидим, как строгое следование нашим принципам инкапсуляции и тщательного проанализированного наслоения поможет нам избежать :) "говнокодинга"
2.3.1. Dataclasses отлично подходят для Value Objects
Мы широко использовали line в предыдущих листингах кода, но что такое строка? На нашем деловом языке order состоит из нескольких line товаров, где каждая строка имеет SKU и количество. Представм, что простой файл YAML, содержащий информацию о заказе, может выглядеть так:
Order_reference: 12345
Lines:
- sku: RED-CHAIR
qty: 25
- sku: BLU-CHAIR
qty: 25
- sku: GRN-CHAIR
qty: 25Обратите внимание, что в то время как заказ имеет reference, который однозначно идентифицирует его, line нет. (Даже если мы добавим ссылку на порядок в класс OrderLine, это не то, что однозначно идентифицирует саму строку.)
Всякий раз, когда у нас есть бизнес-концепция, имеющая данные, но не имеющая идентичности, мы часто предпочитаем представлять её с помощью шаблона Value Object. value object-это любой объект предметной области, который однозначно идентифицируется содержащимися в нем данными; обычно мы делаем их неизменяемыми:
@dataclass(frozen=True)
class OrderLine:
orderid: OrderReference
sku: ProductReference
qty: Quantity
Одна из приятных вещей, которые дают нам dataclasses (или namedtuples), — это value equality, что является причудливым способом сказать: "Две строки с одинаковыми orderid, sku и qty равны."
from dataclasses import dataclass
from typing import NamedTuple
from collections import namedtuple
@dataclass(frozen=True)
class Name:
first_name: str
surname: str
class Money(NamedTuple):
currency: str
value: int
Line = namedtuple('Line', ['sku', 'qty'])
def test_equality():
assert Money('gbp', 10) == Money('gbp', 10)
assert Name('Harry', 'Percival') != Name('Bob', 'Gregory')
assert Line('RED-CHAIR', 5) == Line('RED-CHAIR', 5)Эти ценностные объекты соответствуют нашему реальнму передставлению о том, как работают их ценности. Не имеет значения, о какой банкноте в 10 фунтов мы говорим, потому что все они имеют одинаковую ценность. Аналогично, два имени равны, если совпадают имя и фамилия; и две строки эквивалентны, если они имеют один и тот же заказ клиента, код продукта и количество. Однако мы все еще можем иметь сложное поведение на ценностном объекте. На самом деле, обычно поддерживают операции со значениями; например, математические операторы:
fiver = Money('gbp', 5)
tenner = Money('gbp', 10)
def can_add_money_values_for_the_same_currency():
assert fiver + fiver == tenner
def can_subtract_money_values():
assert tenner - fiver == fiver
def adding_different_currencies_fails():
with pytest.raises(ValueError):
Money('usd', 10) + Money('gbp', 10)
def can_multiply_money_by_a_number():
assert fiver * 5 == Money('gbp', 25)
def multiplying_two_money_values_is_an_error():
with pytest.raises(TypeError):
tenner * fiver2.3.2. Value Objects и Entities
Строка заказа однозначно идентифицируется по идентификатору заказа (ID), артикулу (SKU) и количеству (quantity); если мы изменим одно из этих значений, теперь у нас будет новая строка. Это определение value object: любой объект, который идентифицируется только своими данными и не имеет долгоживущей идентичности. А как насчет партии товара? Это is идентифицировано ссылкой.
Мы используем термин entity для описания объекта домена, который имеет долгосрочную идентичность. На предыдущей странице мы представили класс Name как объект значения. Если мы возьмем имя Гарри Персиваль и изменим одну букву, у нас будет новый объект Name, Барри Персиваль.
Должно быть ясно, что Гарри Персиваль не равен Барри Персивалю:
def test_name_equality():
assert Name("Harry", "Percival") != Name("Barry", "Percival")Но как насчет Гарри как личности? Люди меняют свои имена, семейное положение и даже пол, но мы продолжаем признавать их как одного человека. Это потому, что люди, в отличие от имен, имеют постоянное identity:
class Person:
def __init__(self, name: Name):
self.name = name
def test_barry_is_harry():
harry = Person(Name("Harry", "Percival"))
barry = harry
barry.name = Name("Barry", "Percival")
assert harry is barry and barry is harryСущности, в отличие от значений, обладают identity equality (равенством идентичности). Мы можем изменить их ценности, и они по-прежнему узнаваемы. Batches (партии), в нашем примере, являются сущностями. Мы можем выделить строки в заказе для партии товара или изменить дату, когда мы ожидаем, что она прибудет, и это будет все та же сущность.
Обычно мы делаем это явно в коде, реализуя операторы равенства для сущностей:
class Batch:
...
def __eq__(self, other):
if not isinstance(other, Batch):
return False
return other.reference == self.reference
def __hash__(self):
return hash(self.reference)
Магический метод Python __eq__
определяет поведение класса для == operator.[12]
И для объектов сущностей, и для объектов значений также стоит подумать о том, как __hash__ будет работать. Это волшебный метод, который Python использует для управления поведением объектов, когда вы добавляете их в наборы или используете их как ключи dict; вы можете найти дополнительную информацию в документации Python.
Для value objects хэш должен основываться на всех атрибутах value, и мы должны гарантировать, что объекты неизменяемы. Мы получаем это бесплатно, указав @frozen=True в классе данных.
Для сущностей самый простой вариант-сказать, что хэш-это None, что означает, что объект не является хэшируемым и не может, например, использоваться в множестве (имеется ввиду set). Если по какой-то причине вы решите, что действительно хотите использовать операции set или dict с сущностями, хэш должен основываться на атрибуте(атрибутах), таком как .reference, который определяет уникальную идентичность сущности с течением времени. Вы должны также попытаться как-то сделать этот атрибут read-only.
Это сложная территория; вы не должны изменять __hash__ без изменения __eq__. Если вы не уверены в том, что делаете, рекомендуется продолжить разбор почитав "Python Hashes and Equality" от нашего технического обозревателя Хайнека Шлавака - хорошее место для начала.
|
2.4. Не Все Должно быть Объектом: A Domain Service Function
Мы создали модель для представления партий, но на самом деле нам нужно распределить строки заказа по определенному набору партий, представляющих все наши запасы.
Иногда это просто не так.
Domain-Driven Design
Эванс обсуждает идею Domain Service operations, которые не имеют естественного дома в entity или value object.[13] То, что выделяет строку заказа для данного набора партий, очень похоже на функцию, и мы можем воспользоваться тем фактом, что Python - это многопарадигмальный язык, и просто сделать его функцией.
Давайте посмотрим, как мы можем протестировать такую функцию:
def test_prefers_current_stock_batches_to_shipments():
in_stock_batch = Batch("in-stock-batch", "RETRO-CLOCK", 100, eta=None)
shipment_batch = Batch("shipment-batch", "RETRO-CLOCK", 100, eta=tomorrow)
line = OrderLine("oref", "RETRO-CLOCK", 10)
allocate(line, [in_stock_batch, shipment_batch])
assert in_stock_batch.available_quantity == 90
assert shipment_batch.available_quantity == 100
def test_prefers_earlier_batches():
earliest = Batch("speedy-batch", "MINIMALIST-SPOON", 100, eta=today)
medium = Batch("normal-batch", "MINIMALIST-SPOON", 100, eta=tomorrow)
latest = Batch("slow-batch", "MINIMALIST-SPOON", 100, eta=later)
line = OrderLine("order1", "MINIMALIST-SPOON", 10)
allocate(line, [medium, earliest, latest])
assert earliest.available_quantity == 90
assert medium.available_quantity == 100
assert latest.available_quantity == 100
def test_returns_allocated_batch_ref():
in_stock_batch = Batch("in-stock-batch-ref", "HIGHBROW-POSTER", 100, eta=None)
shipment_batch = Batch("shipment-batch-ref", "HIGHBROW-POSTER", 100, eta=tomorrow)
line = OrderLine("oref", "HIGHBROW-POSTER", 10)
allocation = allocate(line, [in_stock_batch, shipment_batch])
assert allocation == in_stock_batch.referenceА наш сервис может выглядеть так:
def allocate(line: OrderLine, batches: List[Batch]) -> str:
batch = next(
b for b in sorted(batches) if b.can_allocate(line)
)
batch.allocate(line)
return batch.reference2.4.1. Магические методы Python позволяют нам использовать наши модели с идиоматическим Python
Вам может понравиться или не понравиться использование next() в предыдущем коде, но мы почти уверены, что вы согласитесь с тем, что возможность использовать sorted() в нашем списке партий — это хороший идиоматический Python.
Чтобы заставить его работать, мы реализуем __gt__ на нашей доменной модели:
class Batch:
...
def __gt__(self, other):
if self.eta is None:
return False
if other.eta is None:
return True
return self.eta > other.etaЭто прекрасно.
2.4.2. Исключения тоже могут выражать концепции предметной области
Имеется еще одна, наверное, последняя концепция, которую нужно охватить: исключения также могут использоваться для выражения концепций предметной области. В наших беседах с экспертами в предметной области мы узнали о возможности того, что заказ не может быть размещен, потому что у нас out of stock (нет запасов), и мы можем зафиксировать это, используя domain exception:
def test_raises_out_of_stock_exception_if_cannot_allocate():
batch = Batch('batch1', 'SMALL-FORK', 10, eta=today)
allocate(OrderLine('order1', 'SMALL-FORK', 10), [batch])
with pytest.raises(OutOfStock, match='SMALL-FORK'):
allocate(OrderLine('order2', 'SMALL-FORK', 1), [batch])Мы не будем слишком утомлять вас реализацией, но главное, что следует отметить, - это то, что мы тщательно называем наши исключения на ubiquitous language, так же как и наши сущности, объекты ценности и службы:
class OutOfStock(Exception):
pass
def allocate(line: OrderLine, batches: List[Batch]) -> str:
try:
batch = next(
...
except StopIteration:
raise OutOfStock(f'Нет в наличии для артикула {line.sku}')Наша модель предметной области в конце главы это визуальное представление того, где мы оказались.
Пожалуй, на сегодня хватит! У нас есть доменная служба, которую мы можем использовать для нашего первого варианта использования. Но сначала нам понадобится база данных…
3. Repository Pattern
Пришло время выполнить обещание использовать принцип инверсии зависимостей как способ отделить основную логику от инфраструктурных проблем.
Представляем вам шаблон Repository, он упрощает абстракцию над хранилищем данных, позволяющую нам отделить слой модели от слоя данных. Давайте приведем конкретный пример того, как эта упрощающая абстракция делает нашу систему более тестируемой, скрывая сложности базы данных.
Картина До и после шаблона репозитория илюстрирует то, что мы собираемся построить: объект Repository, который находится между нашей моделью предметной области и базой данных.
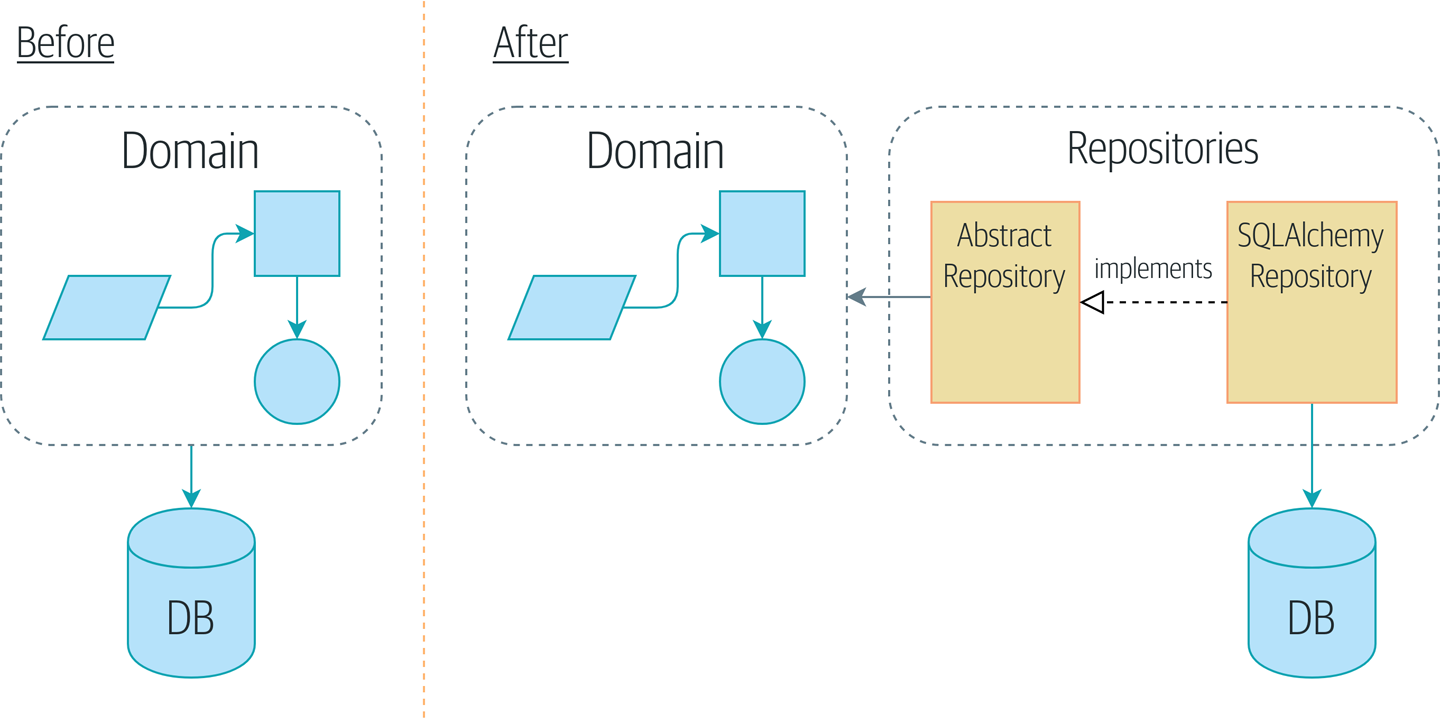
|
Код для этой главы находится в chapter_02_repository branch on GitHub. git clone https://github.com/cosmicpython/code.git cd code git checkout chapter_02_repository # или чтобы писать код вместе с нами, ознакомьтесь с предыдущей главой: git checkout chapter_01_domain_model |
3.1. Persisting Our Domain Model
В Domain Modeling мы построили простую модель домена, которая может распределять заказы по партиям запасов. Мы относительно легко написали тесты для такого кода, потому что нет никаких зависимостей или инфраструктуры для настройки. Если бы нужно было запустить базу данных или API и создать тестовые данные, тесты было бы сложнее писать и поддерживать.
К сожалению, в какой-то момент нам придется передать эту идеальную маленькую модель в руки пользователей и бороться с реальным миром электронных таблиц, веб-браузеров и условий гонки. В следующих нескольких главах мы рассмотрим, как связать идеализированную модель предметной области с внешним состоянием.
В надежде на то, что мы будем работать гибко, наш основной приоритет — как можно быстрее получить минимально жизнеспособный продукт. В нашем случае это будет веб-API. В реальном проекте вы можете сразу погрузиться в несколько сквозных (end-to-end) тестов и начать подключать веб-фреймворк, тестируя функционал извне.
Но мы знаем, что, несмотря ни на что, нам понадобится какая-то форма постоянного хранения. Поскольку это учебник, мы можем позволить себе немного больше развития снизу вверх и начать думать о хранении и базах данных.
3.2. Псевдокод: Что делать то будем?
Когда мы создаём наш первый endpoint API, подразумеваем, что у нас будет некоторый код, который выглядит более или менее похожим на этот.
@flask.route.gubbins
def allocate_endpoint():
# извлечь строку заказа из запроса
line = OrderLine(request.params, ...)
# загрузить все партии из БД
batches = ...
# передать в domain service
allocate(line, batches)
# затем сохраните выделеные позици обратно в базу данных
return 201| Мы использовали Flask, потому что он достаточно простой, но вам не нужно быть с Flask на "ты", чтобы понять эту книгу. На самом деле, наша задача объяснить, как сделать выбор фреймворка незначительной деталью. |
Нам понадобится способ извлечения пакетной информации из базы данных и создания из нее экземпляров объектов модели домена, а также способ сохранения их обратно в базу данных.
Какого…? Ух-х-х, «gubbins» - это британское слово, означающее «фигня». Вы можете просто забить на это. Это’ж псевдокод, понятно?
3.3. Применение DIP для доступа к данным
Как уже упоминалось в введение, многоуровневая архитектура — это общий подход к структурированию системы, которая имеет пользовательский интерфейс, некоторую логику и базу данных (см. Многослойная архитектура).
Структура Django Model-View-Template тесно связана, как и Model-View-Controller (MVC). В любом случае цель состоит в том, чтобы слои были разделены (что хорошо), и чтобы каждый слой зависел только от того, который находится под ним.
Надо, чтобы в нашей модели предметной области не было никаких зависимостей .[14] Не надо, чтобы проблемы с инфраструктурой проникли в нашу модель предметной области и замедлили наши модульные тесты или нашу способность вносить изменения.
Вместо этого, как обсуждалось во введении, мы будем думать, что наша модель находится "inside (внутри)", и зависимости текут внутрь неё; это то, что умные люди иногда называют onion (луковая) architecture (см. Onion architecture).
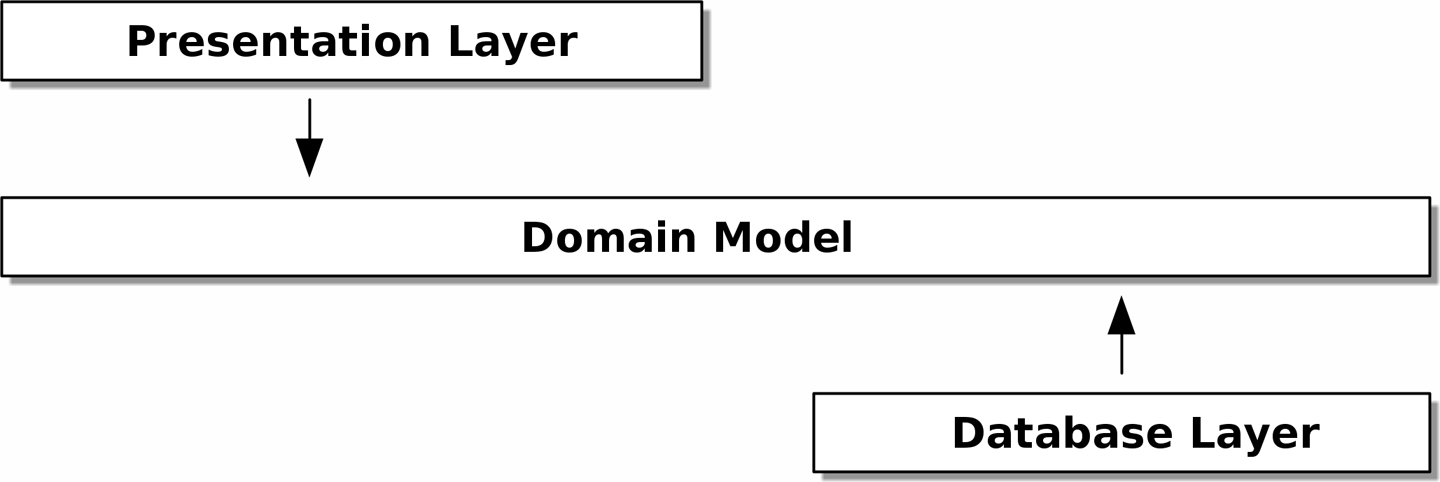
[ditaa, apwp_0203]
+------------------------+
| Presentation Layer |
+------------------------+
|
V
+--------------------------------------------------+
| Domain Model |
+--------------------------------------------------+
^
|
+---------------------+
| Database Layer |
+---------------------+
3.4. Напоминание: Наша модель
Давайте вспомним нашу модель предметной области (см. Наша модель):
Распределение - это концепция связывания OrderLine с Batch. Мы сохраняем выделенные позиици как коллекцию в нашем объекте Batch.
Давайте посмотрим, как мы можем перенести это в реляционную базу данных.
3.4.1. "Нормальный" способ это ORM: Модель зависит от ORM
В наши дни маловероятно, что члены вашей команды вручную создают свои собственные SQL-запросы. Вместо этого вы почти наверняка используете какой-то фреймворк для генерации строк SQL на основе ваших объектов модели.
Эти структуры называются объектно-реляционными картографами object-relational mappers (ОРМ), поскольку они существуют для преодоления концептуального разрыва между миром объектов и моделирования предметной области и миром баз данных и реляционной алгебры.
Самая важная вещь, которую дает нам ORM, - это игнорирование сохраняемости persistence ignorance: идея в том, что наша доменная модель не должна ничего знать о том, как данные загружаются или сохраняются. Это помогает сохранить наш домен чистым от прямых зависимостей конкретных технологий баз данных.[16]
Но если вы будете следовать типичному учебнику SQLAlchemy, то в итоге получите что-то вроде этого:
from sqlalchemy import Column, ForeignKey, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship
Base = declarative_base()
class Order(Base):
id = Column(Integer, primary_key=True)
class OrderLine(Base):
id = Column(Integer, primary_key=True)
sku = Column(String(250))
qty = Integer(String(250))
order_id = Column(Integer, ForeignKey('order.id'))
order = relationship(Order)
class Allocation(Base):
...Вам не нужно разбираться в SQLAlchemy, чтобы увидеть, что наша изначальная модель теперь полна зависимостей от ORM и к тому же начинает выглядеть чертовски уродливо. Можно ли сказать, что эта модель игнорирует базу данных? Как это можно отделить от проблем с хранением, когда свойства нашей модели напрямую связаны со столбцами базы данных?
3.4.2. Инвертирование зависимости: ORM зависит от модели
К счастью, это не единственный способ использовать SQLAlchemy. Альтернативой является определение вашей схемы отдельно и определение явного mapper-а для преобразования между схемой и нашей моделью предметной области, что SQLAlchemy называет classical mapping:
from sqlalchemy.orm import mapper, relationship
import model (1)
metadata = MetaData()
order_lines = Table( (2)
'order_lines', metadata,
Column('id', Integer, primary_key=True, autoincrement=True),
Column('sku', String(255)),
Column('qty', Integer, nullable=False),
Column('orderid', String(255)),
)
...
def start_mappers():
lines_mapper = mapper(model.OrderLine, order_lines) (3)| 1 | ORM импортирует (или "зависит от" или "знает о") модель предметной области, а не наоборот. |
| 2 | Мы определяем таблицы и столбцы нашей базы данных с помощью абстракций SQLAlchemy.[17] |
| 3 | Когда мы вызываем функцию mapper, SQLAlchemy творит чудеса, связывая классы нашей модели предметной области с различными таблицами, которые мы определили. |
Конечным результатом будет то, что, если мы вызовем start_mappers, мы сможем легко загружать и сохранять экземпляры модели домена из базы данных и в нее. Но если мы никогда не вызываем эту функцию, наши классы доменных моделей остаются в блаженном неведении о базе данных.
Это дает нам все преимущества SQLAlchemy, включая возможность использовать alembic для миграций и возможность прозрачного запроса с использованием наших классов домена, как мы увидим.
Когда вы впервые пытаетесь создать свою конфигурацию ORM, может быть полезно написать для неё тесты, как в следующем примере:
def test_orderline_mapper_can_load_lines(session): (1)
session.execute(
'INSERT INTO order_lines (orderid, sku, qty) VALUES '
'("order1", "RED-CHAIR", 12),'
'("order1", "RED-TABLE", 13),'
'("order2", "BLUE-LIPSTICK", 14)'
)
expected = [
model.OrderLine("order1", "RED-CHAIR", 12),
model.OrderLine("order1", "RED-TABLE", 13),
model.OrderLine("order2", "BLUE-LIPSTICK", 14),
]
assert session.query(model.OrderLine).all() == expected
def test_orderline_mapper_can_save_lines(session):
new_line = model.OrderLine("order1", "DECORATIVE-WIDGET", 12)
session.add(new_line)
session.commit()
rows = list(session.execute('SELECT orderid, sku, qty FROM "order_lines"'))
assert rows == [("order1", "DECORATIVE-WIDGET", 12)]| 1 | Если вы не использовали pytest, то аргумент session для этого теста нуждается в объяснении. Смысл такой: Вам не нужно беспокоиться о деталях pytest или его фикстурах в целях этой книги, но главная мысль состоит в том, что вы можете определить общие зависимости для ваших тестов в виде "fixtures", и pytest передаст их в тесты, которые нуждаются в них, приняв их в качестве аргументов функций. В данном случае это сеанс session базы данных SQLAlchemy.
|
Вероятно, вам не стоит хранить эти тесты. Как вы вскоре увидите, после того, как поближе познакомитесь с инверсией зависимости ORM и модели предметной области, это всего лишь небольшой дополнительный шаг для реализации другой абстракции, называемой шаблоном репозитория, для которого будет легче писать тесты, и он предоставит простой интерфейс для, скажем так — фейка, позже в тестах.
Но мы уже достигли нашей цели инвертировать традиционную зависимость: модель предметной области остается «чистой» и свободной от инфраструктурных проблем. Мы могли бы выбросить SQLAlchemy и использовать другую ORM или совершенно другую систему сохранения, и модель предметной области вообще не нуждалась бы в изменении.
В зависимости от того, что вы делаете в своей модели предметной области, и особенно если вы отходите далеко от парадигмы объектно-ориентированного программирования, вам может оказаться все труднее заставить ORM обеспечить точное поведение, которое вам нужно, и вам может потребоваться изменить модель предметной области. [18] Как это часто бывает с архитектурными решениями, вам нужно будет найти компромисс. Как говорит дзэн Python: «Практичность лучше чистоты!»
На данный момент, однако, наш endpoint API может выглядеть примерно так, и мы могли бы заставить её работать просто отлично:
@flask.route.gubbins
def allocate_endpoint():
session = start_session()
# извлечение строки заказа из запроса
line = OrderLine(
request.json['orderid'],
request.json['sku'],
request.json['qty'],
)
# загрузите все пакеты из БД
batches = session.query(Batch).all()
# call our domain service
allocate(line, batches)
# сохраните распределения обратно в базу данных
session.commit()
return 2013.5. Знакомство с шаблоном репозитория
Шаблон Repository — это абстракция над постоянным хранилищем. Он скрывает скучные детали доступа к данным, делая вид, что все наши данные находятся в памяти.
Если бы у нас была бесконечная память в наших ноутбуках, у нас не было бы необходимости в неуклюжих базах данных. Вместо этого мы могли просто использовать наши объекты, когда нам заблагорассудится. Как это будет выглядеть?
import all_my_data
def create_a_batch():
batch = Batch(...)
all_my_data.batches.add(batch)
def modify_a_batch(batch_id, new_quantity):
batch = all_my_data.batches.get(batch_id)
batch.change_initial_quantity(new_quantity)Несмотря на то, что наши объекты находятся в памяти, нам нужно поместить их где-нибудь, чтобы снова найти их. Наши данные в памяти позволят нам добавлять новые объекты, как список или множество. Поскольку объекты находятся в памяти, нам никогда не нужно вызывать метод .save (); мы просто получаем объект, который нам нужен, и модифицируем его в памяти.
3.5.1. The Repository in the Abstract
В простейшем репозитории всего два метода: add () для добавления нового элемента в репозиторий и get() для возврата ранее добавленного элемента.[19]
Мы твердо придерживаемся использования этих методов для доступа к данным в нашем домене и на уровне сервиса. Эта добровольная простота не позволяет нам связать нашу модель предметной области с базой данных.
Вот как будет выглядеть абстрактный базовый класс (ABC) для нашего репозитория:
class AbstractRepository(abc.ABC):
@abc.abstractmethod (1)
def add(self, batch: model.Batch):
raise NotImplementedError (2)
@abc.abstractmethod
def get(self, reference) -> model.Batch:
raise NotImplementedError| 1 | Python tip: @abc.abstractmethod — это одна из немногих вещей, которая заставляет ABCs действительно "работать" в Python. Python не позволит вам создать экземпляр класса, который не реализует все "абстрактные методы", определенные в его родительском классе.[20]
|
| 2 | raise NotImplementedError — это хорошо, но это не обязательно и не достаточно. На самом деле, ваши абстрактные методы могут иметь реальное поведение, которое подклассы могут вызвать, если вы действительно хотите. |
3.5.2. Что такое компромисс?
Знаете, говорят, что экономисты знают всё о цене и ничего о ценности? Программисты же, знают всё о преимуществе и ничего о компромисе.
Всякий раз, когда мы представляем архитектурный паттерн в этой книге, мы всегда задаёмся вопроосом: «Что нам ЭТО даст? И во что нам ЭТО обойдётся?»
Обычно, вводя дополнительный уровень абстракции, мы по крайней мере надеемся, что это уменьшит сложность в целом, а в действительности всё это добавляет сложности локальной и имеет свою стоимость с точки зрения необработанного количества перемещений и текущего обслуживания.
Шаблон репозитория, вероятно, является одним из самых простых вариантов в книге, если вы уже идёте по пути DDD и инверсии зависимостей. Что касается нашего кода, на самом деле мы просто меняем абстракцию SQLAlchemy (session.query (Batch)) на другую (batches_repo.get), которую мы разработали.
Нам придется добавлять несколько строк кода в нашем классе репозитория каждый раз, когда мы добавляем новый объект домена, который мы хотим получить, но взамен мы получаем простую абстракцию над нашим уровнем хранения, который мы контролируем. Шаблон репозитория позволит легко вносить фундаментальные изменения в то, как мы храним объекты (см. Замена инфраструктуры: Делайте все с CSV), и, как мы увидим, его легко подменить для модульных тестов.
Кроме того, шаблон репозитория настолько распространен в мире DDD, что, если вы сотрудничаете с программистами, пришедшими в Python из мира Java и C#, они, скорее всего, узнают его. Repository pattern иллюстрирует этот паттерн.
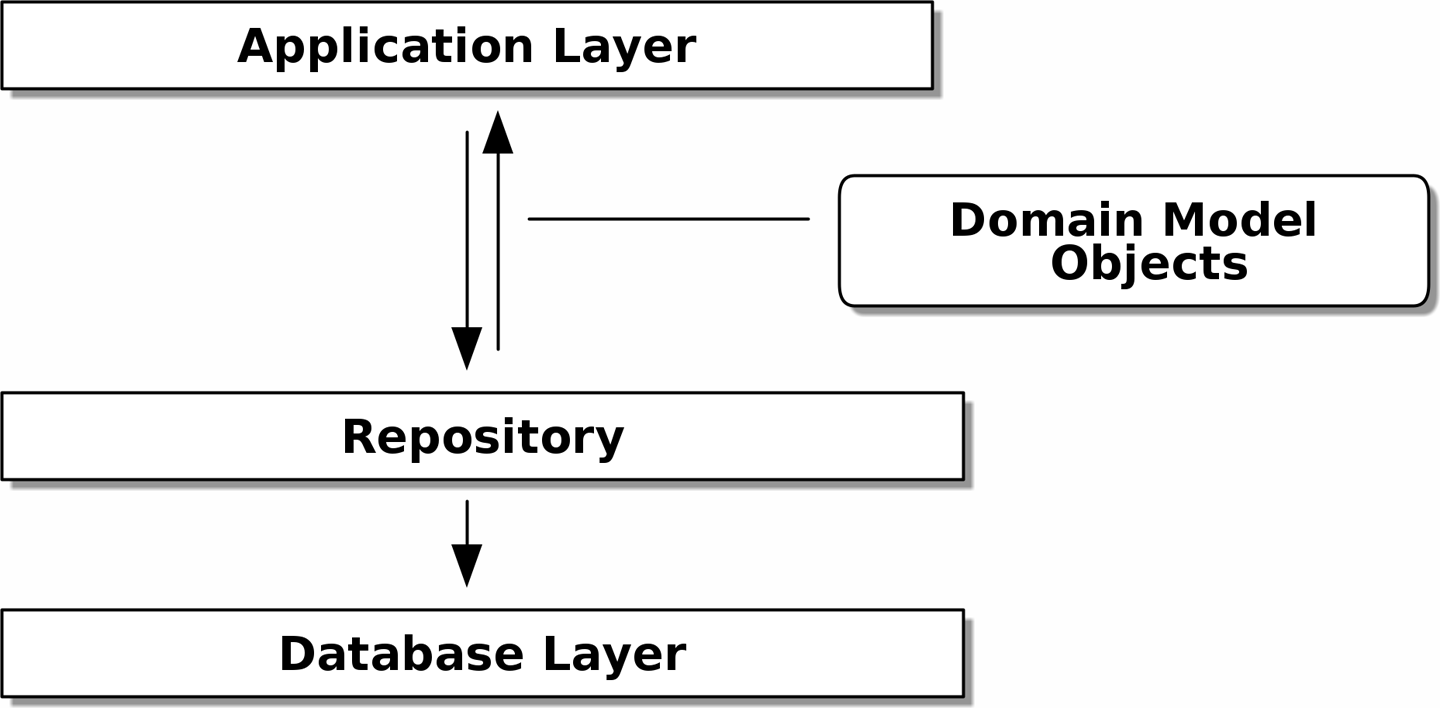
[ditaa, apwp_0205]
+-----------------------------+
| Application Layer |
+-----------------------------+
|^
|| /------------------\
||----------| Domain Model |
|| | Objects |
|| \------------------/
V|
+------------------------------+
| Repository |
+------------------------------+
|
V
+------------------------------+
| Database Layer |
+------------------------------+
Как всегда, мы начинаем с теста. Это, вероятно, было бы классифицировано как интеграционный тест, поскольку мы проверяем, что наш код (репозиторий) правильно интегрирован с базой данных; следовательно, тесты, как правило, смешивают необработанный SQL с вызовами и ассертами в нашем собственном коде.
| В отличие от предыдущих тестов ORM, эти тесты являются хорошими кандидатами на то, чтобы оставаться частью вашей кодовой базы в долгосрочной перспективе, особенно если какие-либо части вашей модели предметной области означают, что объектно-реляционная карта нетривиальна. |
def test_repository_can_save_a_batch(session):
batch = model.Batch("batch1", "RUSTY-SOAPDISH", 100, eta=None)
repo = repository.SqlAlchemyRepository(session)
repo.add(batch) (1)
session.commit() (2)
rows = list(session.execute(
'SELECT reference, sku, _purchased_quantity, eta FROM "batches"' (3)
))
assert rows == [("batch1", "RUSTY-SOAPDISH", 100, None)]| 1 | repo.add() это тестируемый здесь метод. |
| 2 | Мы храним .commit() вне репозитория и возлагаем ответственность на вызывающего. В этом есть свои плюсы и минусы; некоторые из причин станут яснее, когда мы доберемся до Паттерн Unit of Work(Единица работы). |
| 3 | Используем необработанный SQL, чтобы убедиться, что были сохраненыправильные данные . |
Следующий тест включает в себя извлечение пакетов и распределений, поэтому он более сложный:
def insert_order_line(session):
session.execute( (1)
'INSERT INTO order_lines (orderid, sku, qty)'
' VALUES ("order1", "GENERIC-SOFA", 12)'
)
[[orderline_id]] = session.execute(
'SELECT id FROM order_lines WHERE orderid=:orderid AND sku=:sku',
dict(orderid="order1", sku="GENERIC-SOFA")
)
return orderline_id
def insert_batch(session, batch_id): (2)
...
def test_repository_can_retrieve_a_batch_with_allocations(session):
orderline_id = insert_order_line(session)
batch1_id = insert_batch(session, "batch1")
insert_batch(session, "batch2")
insert_allocation(session, orderline_id, batch1_id) (2)
repo = repository.SqlAlchemyRepository(session)
retrieved = repo.get("batch1")
expected = model.Batch("batch1", "GENERIC-SOFA", 100, eta=None)
assert retrieved == expected # Batch.__eq__ only compares reference (3)
assert retrieved.sku == expected.sku (4)
assert retrieved._purchased_quantity == expected._purchased_quantity
assert retrieved._allocations == { (4)
model.OrderLine("order1", "GENERIC-SOFA", 12),
}| 1 | Проверяет сторону чтения, поэтому необработанный SQL готовит данные для чтения repo.get(). |
| 2 | Избавляем вас от деталей insert_batch и insert_allocation; Зыдача в том, чтобы создать пару партий, а для интересующей нас партии выделить одну существующую строку заказа. |
| 3 | Вот что мы здесь проверяем. Первый assert == проверяет соответствие типов и совпадение ссылок (потому что, как вы помните, Batch — это сущность, и для нее у нас есть собственный __ eq __ ). |
| 4 | Поэтому мы также явно проверяем его основные атрибуты, в том числе
._allocations, который представляет собой набор Python-объектов значений OrderLine. |
Независимо от того, насколько вы кропотливо написали тесты для каждой модели. После того, как у вас будет протестирован один класс на создание/изменение/сохранение, вы можете продолжить и протестировать другие с минимальным тестом на обратную связь или вообще ничего, если все они следуют схожему шаблону. В нашем случае конфигурация ORM, которая устанавливает набор ._allocations, немного сложна, поэтому заслуживает особого тестирования.
Вы получите что-то вроде этого:
class SqlAlchemyRepository(AbstractRepository):
def __init__(self, session):
self.session = session
def add(self, batch):
self.session.add(batch)
def get(self, reference):
return self.session.query(model.Batch).filter_by(reference=reference).one()
def list(self):
return self.session.query(model.Batch).all()И теперь наша конечная точка Flask может выглядеть примерно так:
@flask.route.gubbins
def allocate_endpoint():
batches = SqlAlchemyRepository.list()
lines = [
OrderLine(l['orderid'], l['sku'], l['qty'])
for l in request.params...
]
allocate(lines, batches)
session.commit()
return 2013.6. Создание поддельного репозитория для тестов теперь тривиально!
Вот одно из самых больших преимуществ шаблона репозиторий:
class FakeRepository(AbstractRepository):
def __init__(self, batches):
self._batches = set(batches)
def add(self, batch):
self._batches.add(batch)
def get(self, reference):
return next(b for b in self._batches if b.reference == reference)
def list(self):
return list(self._batches)Поскольку это простая оболочка для set, все методы являются однострочными.
Использовать фальшивое репо в тестах действительно просто, и у нас есть простая абстракция, которую легко использовать и рассуждать:
fake_repo = FakeRepository([batch1, batch2, batch3])Вы увидите эту подделку в действии в следующей главе.
| Создание подделок для ваших абстракций - отличный способ получить обратную связь от дизайна: если подделать сложно, значит, абстракция слишком сложна. |
3.7. Что такое порт и что такое адаптер в Python?
Мы не хотим слишком подробно останавливаться здесь на терминологии, потому что главное, на чем мы хотим сосредоточиться, - это инверсия зависимостей, а специфика используемой вами техники не имеет большого значения. Кроме того, мы знаем, что разные люди используют несколько разные определения.
Порты и адаптеры вышли из мира OO, и определение, которое мы придерживаемся, состоит в том, что port — это interface между нашим приложением и тем, что мы хотим абстрагировать, а adapter — это implementation (реализация) за этим интерфейсом или абстракцией.
Python не имеет интерфейсов как таковых, поэтому, хотя обычно легко идентифицировать адаптер, определение порта может быть сложнее. Если вы используете абстрактный базовый класс, это порт. Если нет, то порт—это просто duck type, которому соответствуют ваши адаптеры и который ожидает ваше основное приложение — имена используемых функций и методов, а также имена и типы их аргументов.
Конкретно, в этой главе, AbstractRepository это порт, a
SqlAlchemyRepository и FakeRepository - это адаптеры.
3.8. Заключение
Помня цитату Рича Хики, в каждой главе мы суммируем затраты и преимущества каждого представленного архитектурного шаблона. Мы хотим, чтобы было ясно, что мы не говорим, что каждое отдельное приложение должно быть построено именно таким образом; только иногда сложность приложения и домена заставляет тратить время и усилия на добавление этих дополнительных слоев косвенности.
Имея это в виду, Шаблон репозитория и persistence ignorance: компромиссы показывает некоторые плюсы и минусы шаблона репозитория и нашей модели с игнорированием персистентности.
| Плюсы | Минусы |
|---|---|
|
|
Компромиссы модели предметной области в виде диаграммы демонстрирует основной тезис: да, для простых случаев развязанная модель предметной области является более сложной работой, чем простой шаблон ORM/ActiveRecord.[21]
| Если ваше приложение представляет собой простую оболочку CRUD (создание-чтение-обновление-удаление) вокруг базы данных, вам не нужна модель предметной области или репозиторий. |
Но чем сложнее домен, тем больше окупаются инвестиции в избавление от проблем с инфраструктурой с точки зрения простоты внесения изменений.
Наш пример кода не настолько сложен, чтобы дать больше, чем намек на то, как выглядит правая часть графика, но намеки есть. Представьте себе, например, что однажды мы решим, что хотим изменить распределение, чтобы жить на "OrderLine", а не на "Batch" объекте: если бы мы использовали, скажем, Django, нам пришлось бы определить и продумать миграцию базы данных, прежде чем мы могли бы запустить какие-либо тесты. Как бы то ни было, поскольку наша модель-это просто старые объекты Python, мы можем изменить set() на новый атрибут, не думая о базе данных до более подходящего момента.
Вам будет интересно, как мы создаем экземпляры этих хранилищ, поддельные или настоящие? Как на самом деле будет выглядеть наше приложение Flask? Вы узнаете об этом в следующей захватывающей части, the Service Layer pattern.
Но сначала небольшое отступление.
4. Краткая интерлюдия: О Связях и Абстракции
Позвольте нам, дорогой читатель, сделать небольшое отступление от темы абстракций. Мы довольно много говорили об абстракциях. Например, шаблон репозитория-это абстракция над складом. Но что делает хорошую абстракцию? Чего мы хотим от абстракций? И как они связаны с тестированием?
|
Код для этой главы находится в ветке chapter_03_abstractions on GitHub: git clone https://github.com/cosmicpython/code.git git checkout chapter_03_abstractions |
Ключевая тема этой книги, скрытая среди причудливых хитроплетений, заключается в том, что мы можем использовать простые абстракции, чтобы скрыть беспорядочные детали. Когда мы пишем код для удовольствия или в ката,[22] мы можем свободно упражняться с идеями, вычленяя сущности и агрессивно рефакторингуя. Однако, в крупномасштабной системе, наши решения становимся ограниченными, другими решениями, принятыми в других частях системы.
Когда мы не можем изменить компонент A из опасения сломать компонент B, мы говорим, что компоненты стали связанными или сцепленными (coupled). Локальное сцепление — это хорошо: это признак того, что наш код работает дружно "всем коллективом", каждый компонент поддерживает другие, все они подходят друг к другу, как колёсики в часах. Говоря на жаргоне будет сказано как то так: это работает, когда существуют жесткие связи между связанными элементами.
Вот в глобальном масштабе жёстка связанность (сцепление) — это неприятность: Увеличивается риск и стоимость внесения изменений нашего кода, иногда до такой степени, что мы чувствуем себя неспособными внести какие-либо изменения вообще. Это проблема на рисунке Шара грязи может быть описана так: по мере роста приложения, в случае если мы не можем предотвратить жесткую связанность между элементами, которые не связаны друг с другом, эта взаимосвязь будет прогрессировать сверхлинейно, до тех пор пока мы больше не сможем эффективно вносить изменения в наши системы.
Мы можем уменьшить степень сцепления внутри системы (Много жёстких связей) абстрагируясь от деталей (Меньше жёстких связей).
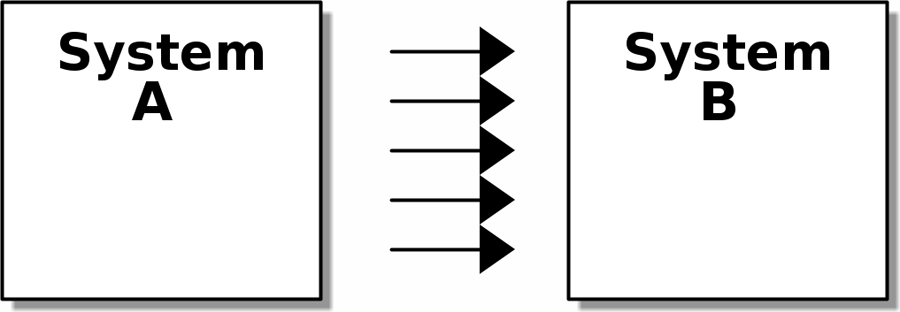
[ditaa, apwp_0301] +--------+ +--------+ | System | ---> | System | | A | ---> | B | | | ---> | | | | ---> | | | | ---> | | +--------+ +--------+

[ditaa, apwp_0302] +--------+ +--------+ | System | /-------------\ | System | | A | ---> | | ---> | B | | | ---> | Abstraction | ---> | | | | | | ---> | | | | \-------------/ | | +--------+ +--------+
На обеих диаграммах у нас есть пара подсистем, одна из которых зависит от другой.В Много жёстких связей между ними существует высокая степень связаности; количество стрелок указывает на множество видов зависимостей между ними. Если нам нужно изменить систему B, есть большая вероятность, что это изменение отразится на системе A.
Однако в Меньше жёстких связей мы уменьшили степень связаности, вставив новую, более простую абстракцию. Поскольку она проще, система А имеет меньше видов зависимостей от абстракции. Абстракция служит для защиты нас от изменений, скрывая сложные детали того, что делает система B - мы можем изменить стрелки справа, не меняя стрелки слева.
4.1. Абстрагирование от Состояния Улучшает Тестируемость
Давайте рассмотрим пример. Представьте, что мы хотим написать код для синхронизации двух файловых каталогов, которые назовем source и destination:
-
Если файл существует в источнике, но не в месте назначения, скопируйте его.
-
Если файл существует в источнике, но имеет другое имя, отличное от имеющегося в папке назначения, переименуйте его в соответствующее.
-
Если файл существует в папке назначения, но отсутствует в источнике, удалите его.
Первое и третье требования достаточно просты: мы можем просто сравнить два списка путей. Но, вот, со вторым сложнее. Чтобы выявить необходимость переименования, нам придется проверить содержимое файлов. Для этого мы можем использовать функцию хеширования, такую как MD5 или SHA-1. Код для генерации хэша SHA-1 из файла достаточно прост:
BLOCKSIZE = 65536
def hash_file(path):
hasher = hashlib.sha1()
with path.open("rb") as file:
buf = file.read(BLOCKSIZE)
while buf:
hasher.update(buf)
buf = file.read(BLOCKSIZE)
return hasher.hexdigest()Теперь нам нужно чуть дописать, часть принятия решения "что делать" — Бизнес-логику, если хотите.
Когда нам нужно решить проблему основываясь на первичных принципах, мы обычно пытаемся написать простую реализацию, а затем заняться рефакторингом в сторону лучшего дизайна. Мы будем использовать этот подход на протяжении всей книги, потому что именно так мы пишем код в реальном мире: начните с решения самой маленькой части проблемы, а затем итеративно делайте решение более продвинутым и лучше разработанным.
Наш первый подход выглядит примерно так:
import hashlib
import os
import shutil
from pathlib import Path
def sync(source, dest):
# Пройдите по исходной папке и создайте список имен файлов и их хэшей
source_hashes = {}
for folder, _, files in os.walk(source):
for fn in files:
source_hashes[hash_file(Path(folder) / fn)] = fn
seen = set() # Следите за файлами, которые мы нашли в целевой папке
# Пройдитесь по целевой папке и получите имена файлов и их хэши
for folder, _, files in os.walk(dest):
for fn in files:
dest_path = Path(folder) / fn
dest_hash = hash_file(dest_path)
seen.add(dest_hash)
# если в целевой папке есть файл, которого нет в исходной,
# удалите его
if dest_hash not in source_hashes:
dest_path.remove()
# если в target есть файл, который имеет другой путь в source,
# переместите его на правильный путь
elif dest_hash in source_hashes and fn != source_hashes[dest_hash]:
shutil.move(dest_path, Path(folder) / source_hashes[dest_hash])
# для каждого файла, который появляется в исходной папке,
# но не в целевой, скопируйте его в целевую
for src_hash, fn in source_hashes.items():
if src_hash not in seen:
shutil.copy(Path(source) / fn, Path(dest) / fn)Фантастика! У нас есть какой-то код, и он выглядит нормально, но прежде чем мы запустим его на жестком диске, может быть, нам стоит его протестировать. Как мы будем тестировать такие штуковины?
def test_when_a_file_exists_in_the_source_but_not_the_destination():
try:
source = tempfile.mkdtemp()
dest = tempfile.mkdtemp()
content = "Я очень полезный файл"
(Path(source) / 'my-file').write_text(content)
sync(source, dest)
expected_path = Path(dest) / 'my-file'
assert expected_path.exists()
assert expected_path.read_text() == content
finally:
shutil.rmtree(source)
shutil.rmtree(dest)
def test_when_a_file_has_been_renamed_in_the_source():
try:
source = tempfile.mkdtemp()
dest = tempfile.mkdtemp()
content = "Я файл, который был переименован"
source_path = Path(source) / 'source-filename'
old_dest_path = Path(dest) / 'dest-filename'
expected_dest_path = Path(dest) / 'source-filename'
source_path.write_text(content)
old_dest_path.write_text(content)
sync(source, dest)
assert old_dest_path.exists() is False
assert expected_dest_path.read_text() == content
finally:
shutil.rmtree(source)
shutil.rmtree(dest)
Строго говоря, тут многовато установок для двух простых случаев! Проблема в том, что логика нашей предметной области «выяснение разницы между двумя каталогами» тесно связана с I/O кодом. Мы не можем запустить наш алгоритм поиска различий без вызова модулей pathlib, shutil и hashlib.
Только вот беда в том, что даже с нашими текущими требованиями мы не написали достаточно тестов: текущая реализация имеет несколько ошибок (например, shutil.move() неверен). Чтобы получить достойное покрытие и выявить эти ошибки, нужно написать больше тестов, но если все они будут такими же громоздкими, как предыдущие, это быстро станет очень геморно.
Вдобавок наш код не очень расширяемый. Представьте, что вы пытаетесь реализовать флаг --dry-run, который заставляет наш код просто распечатать то, что он собирается делать, а не выполнять это на самом деле. А что, если мы хотим синхронизироваться с удаленным сервером или с облачным хранилищем?
Наш высокоуровневый код связан с низкоуровневыми деталями, и это усложняет жизнь. По мере усложнения рассматриваемых сценариев наши тесты будут становиться все более громоздкими. Мы определенно можем провести рефакторинг этих тестов (например, некоторая очистка может быть перенесена в фикстуры pytest), но пока мы выполняем операции с файловой системой, они будут медленными, их будет трудно читать и писать.
4.2. Выбор правильной Абстракции(-й)
Что мы можем сделать, чтобы переписать наш код и сделать его более тестируемым?
Во-первых, нам нужно подумать о том, что нужно нашему коду от файловой системы. Разбирая код, мы видим три различных момента. Воспримем их как три различных обязанности, которые выполняет код:
-
Мы опрашиваем файловую систему с помощью
os.walkи определяем хэши для ряда путей. Это похоже как для исходного, так и конечного случая. -
Мы решаем, является ли файл новым, переименованным или лишним.
-
Мы копируем, перемещаем или удаляем файлы в соответствии с источником.
Помните, что мы хотим найти упрощающие абстракции для каждой из этих обязанностей. Это позволит нам скрыть беспорядочные детали, чтобы мы могли сосредоточиться на интересующей нас логике.[23]
В этой главе мы отрефакторим слегка корявый код в более проверяемую структуру,
определяя отдельные задачи, которые необходимо выполнить, и предоставляя каждую задачу четко
определенному субъекту, аналогично пример duckduckgo.
|
Для шагов 1 и 2 мы уже интуитивно начали использовать абстракцию, словарь хэшей для путей. Возможно, вы уже думали: «Почему бы не создать словарь для целевой папки, а также для источника, а затем мы просто сравним два словаря?» Это похоже на хороший способ абстрагироваться от текущего состояния файловой системы:
source_files = {'hash1': 'path1', 'hash2': 'path2'}
dest_files = {'hash1': 'path1', 'hash2': 'pathX'}
А как насчет перехода от пункта 2 к пункту 3? Как мы можем абстрагироваться от фактического взаимодействия файловой системы перемещения/копирования/удаления?
Мы применим здесь трюк, который будем применять позже в этой книге достаточно широко. Мы собираемся отделить то, что мы хотим сделать, от того, как это сделать. Мы собираемся сделать так, чтобы наша программа выводила список команд, которые выглядят следующим образом:
("COPY", "sourcepath", "destpath"),
("MOVE", "old", "new"),
Теперь мы могли бы написать тесты, которые просто используют два дикта файловой системы в качестве входных данных, и мы ожидали бы списки кортежей строк, представляющих действия в качестве выходных данных.
Вместо того чтобы сказать: "Учитывая фактическую файловую систему при запуске своей функции, проверить, какие действия произошли", мы говорим: "Учитывая абстрацию файловой системы, какое абстрактное действие файловой системы произойдет?"
def test_when_a_file_exists_in_the_source_but_not_the_destination():
src_hashes = {'hash1': 'fn1'}
dst_hashes = {}
expected_actions = [('COPY', '/src/fn1', '/dst/fn1')]
...
def test_when_a_file_has_been_renamed_in_the_source():
src_hashes = {'hash1': 'fn1'}
dst_hashes = {'hash1': 'fn2'}
expected_actions == [('MOVE', '/dst/fn2', '/dst/fn1')]
...4.3. Реализация Выбранных Нами Абстракций
Это все очень хорошо, но как нам на самом деле написать эти новые тесты и как изменить нашу реализацию, чтобы все это работало?
Наша цель состоит в том, чтобы изолировать умную часть нашей системы и иметь возможность тщательно протестировать её без необходимости создавать реальную файловую систему. Мы создадим "ядро" кода, которое не имеет зависимостей от внешнего состояния, а затем посмотрим, как оно реагирует, когда мы даем ему входные данные из внешнего мира (такой подход был охарактеризован Гэри Бернхардтом как Functional Core, Imperative Shell, или FCIS).
Давайте начнем с разделения кода, чтобы отделить части с состоянием от логики.
И наша функция верхнего уровня не будет содержать почти никакой логики вообще; это просто обязательная серия шагов: собрать входные данные, вызвать нашу логику, применить результаты:
def sync(source, dest):
# imperative shell Шаг 1, собрать входные данные
source_hashes = read_paths_and_hashes(source) (1)
dest_hashes = read_paths_and_hashes(dest) (1)
# Шаг 2: вызов функционального ядра
actions = determine_actions(source_hashes, dest_hashes, source, dest) (2)
# imperative shell Шаг 3, применить результаты
for action, *paths in actions:
if action == 'copy':
shutil.copyfile(*paths)
if action == 'move':
shutil.move(*paths)
if action == 'delete':
os.remove(paths[0])| 1 | Первая функция, которую мы учитываем, read_paths_and_hashes(), которая изолирует часть ввода-вывода нашего приложения. |
| 2 | Именно здесь мы вырежем функциональное ядро, бизнес-логику. |
Код для создания словаря путей и хешей теперь написать тривиально просто:
def read_paths_and_hashes(root):
hashes = {}
for folder, _, files in os.walk(root):
for fn in files:
hashes[hash_file(Path(folder) / fn)] = fn
return hashesФункция define_actions() будет ядром нашей бизнес-логики, которая выясняет: «Учитывая эти два набора хэшей и имен файлов, что мы должны копировать/перемещать/удалять?». Она принимает простые структуры данных и возвращает простые структуры данных:
def determine_actions(src_hashes, dst_hashes, src_folder, dst_folder):
for sha, filename in src_hashes.items():
if sha not in dst_hashes:
sourcepath = Path(src_folder) / filename
destpath = Path(dst_folder) / filename
yield 'copy', sourcepath, destpath
elif dst_hashes[sha] != filename:
olddestpath = Path(dst_folder) / dst_hashes[sha]
newdestpath = Path(dst_folder) / filename
yield 'move', olddestpath, newdestpath
for sha, filename in dst_hashes.items():
if sha not in src_hashes:
yield 'delete', dst_folder / filenameТеперь наши тесты действуют непосредственно на функцию determine_actions():
def test_when_a_file_exists_in_the_source_but_not_the_destination():
src_hashes = {'hash1': 'fn1'}
dst_hashes = {}
actions = determine_actions(src_hashes, dst_hashes, Path('/src'), Path('/dst'))
assert list(actions) == [('copy', Path('/src/fn1'), Path('/dst/fn1'))]
def test_when_a_file_has_been_renamed_in_the_source():
src_hashes = {'hash1': 'fn1'}
dst_hashes = {'hash1': 'fn2'}
actions = determine_actions(src_hashes, dst_hashes, Path('/src'), Path('/dst'))
assert list(actions) == [('move', Path('/dst/fn2'), Path('/dst/fn1'))]Поскольку мы отделили логику нашей программы — код для идентификации изменений — от низкоуровневых деталей ввода-вывода, мы можем легко протестировать ядро нашего кода.
При таком подходе мы перешли от тестирования нашей основной функции точки входа sync() к тестированию функции более низкого уровня determine_actions(). Вы можете решить, что это нормально, потому что sync() теперь выполняется так просто. Или вы можете решить провести несколько интеграционных/приемочных тестов, чтобы проверить эту sync(). Но есть еще один вариант, который заключается в изменении функции sync(), чтобы её можно было тестировать модульно и тестировать от начала до конца; это подход, который Боб называет edge-to-edge testing.
4.3.1. Тестирование Edge to Edge с Fakes и Dependency Injection
Когда мы начинаем писать новую систему, мы часто сначала фокусируемся на основной логике, управляя ею с помощью прямых модульных тестов. Однако в какой-то момент мы хотим протестировать совместное использование большой части системы.
Мы бы могли вернуться к нашим сквозным тестам, но они все еще так же сложны в написании и обслуживании, как и раньше. Вместо этого мы часто пишем тесты, которые вызывают целую систему вместе, но подделывают ввод-вывод, своего рода edge to edge:
def sync(reader, filesystem, source_root, dest_root): (1)
source_hashes = reader(source_root) (2)
dest_hashes = reader(dest_root)
for sha, filename in src_hashes.items():
if sha not in dest_hashes:
sourcepath = source_root / filename
destpath = dest_root / filename
filesystem.copy(destpath, sourcepath) (3)
elif dest_hashes[sha] != filename:
olddestpath = dest_root / dest_hashes[sha]
newdestpath = dest_root / filename
filesystem.move(olddestpath, newdestpath)
for sha, filename in dst_hashes.items():
if sha not in source_hashes:
filesystem.delete(dest_root/filename)| 1 | Наша функция верхнего уровня теперь предоставляет две новые зависимости: reader и filesystem. |
| 2 | Мы вызываем reader для создания наших файлов dict. |
| 3 | Мы вызываем filesystem, чтобы применить обнаруженные нами изменения. |
| Хотя мы используем инъекцию зависимостей, нет необходимости определять абстрактный базовый класс или какой-либо явный интерфейс. В этой книге мы часто показываем ABC, потому что надеемся, что этот модуль поможет вам понять, что такое абстракция, но в этом нет необходимости. Динамический характер Python означает, что мы всегда можем положиться на утиную типизацию[24]. |
class FakeFileSystem(list): (1)
def copy(self, src, dest): (2)
self.append(('COPY', src, dest))
def move(self, src, dest):
self.append(('MOVE', src, dest))
def delete(self, dest):
self.append(('DELETE', dest))
def test_when_a_file_exists_in_the_source_but_not_the_destination():
source = {"sha1": "my-file" }
dest = {}
filesystem = FakeFileSystem()
reader = {"/source": source, "/dest": dest}
sync(reader.pop, filesystem, "/source", "/dest")
assert filesystem == [("COPY", "/source/my-file", "/dest/my-file")]
def test_when_a_file_has_been_renamed_in_the_source():
source = {"sha1": "renamed-file" }
dest = {"sha1": "original-file" }
filesystem = FakeFileSystem()
reader = {"/source": source, "/dest": dest}
sync(reader.pop, filesystem, "/source", "/dest")
assert filesystem == [("MOVE", "/dest/original-file", "/dest/renamed-file")]| 1 | Боб обожает использовать списки для создания простых тестовых двойников, даже если это бесит его коллег. Это означает, что мы можем писать тесты вроде assert 'foo' not in database. |
| 2 | Каждый метод в нашей FakeFileSystem просто добавляет что-то в список, чтобы мы могли проверить это позже. Это пример spy object.
|
Преимущество этого подхода заключается в том, что наши тесты работают с той же функцией, которая используется нашим production кодом. Недостатком является то, что мы должны сделать наши компоненты с отслеживанием состояния явными и передавать их по кругу. Дэвид Хайнемайер Ханссон, создатель Ruby on Rails, как известно, описал это как "вызванное тестом повреждение конструкции."
В любом случае, теперь мы можем работать над исправлением всех ошибок в нашей реализации; Перечисление тестов для всех крайних случаев стало намного проще.
4.3.2. Почему бы просто не запатчить это?
В этот момент вы можете почесать затылок и подумать: "Почему бы просто не использовать 'mock.patch' и не сэкономить свои усилия?"
Мы избегаем использования моков в этой книге и в нашем production коде. Мы не собираемся устраивать ХолиВар по этому поводу, но инстинкт подсказывает, что mocking frameworks, особенно monkeypatching, - это дурнопахнущий код.
Вместо этого мы предпочитаем четко определять обязанности в нашей кодовой базе и разделять эти обязанности на небольшие, сфокусированные объекты, которые легко заменить тестовым дублёром.
Вы можете увидеть пример в События и шина сообщений, где мы mock.patch()-ем выводим модуль отправки электронной почты, но в конечном итоге заменяем его явным небольшим кодом внедрения зависимостей в
Dependency Injection (и Bootstrapping).
|
У нас есть три тесно связанных причины нашего предпочтения:
-
Исправление зависимости, которую вы используете, позволяет модульно протестировать код, но это никак не улучшает дизайн. Использование
mock.patchне позволит вашему коду работать с флагом--dry-runи не поможет вам работать с FTP-сервером. Для этого вам нужно будет ввести абстракции. -
Тесты, которые используют mocks стремятся быть более связанными с деталями реализации кодовой базы. Это потому, что имитационные тесты проверяют взаимодействие между объектами: вызывали ли мы
shutil.copyс правильными аргументами? По нашему опыту, эта связь между кодом и тестом стремится сделать тесты более хрупкими. -
Чрезмерное использование моков приводит к созданию сложных наборов тестов, которые не могут объяснить код.
| Проектирование для тестируемости на самом деле означает проектирование для расширяемости. Мы обмениваем немного большую сложность на более чистый дизайн, который допускает новые варианты использования. |
Мы рассматриваем TDD в первую очередь как практику проектирования, а затем как практику тестирования. Тесты выполняют функцию хранения наших вариантов проектирования и служат для объяснения системы, когда мы возвращаемся к коду после долгого отсутствия.
Тесты, использующие слишком много mocks, перегружаются установочным кодом, который скрывает интересующую нас историю.
В своем выступлении Стив Фриман приводит отличный пример чрезмерно замкнутых тестов. "Test-Driven Development". Вам также следует ознакомиться с этим выступлением PyCon, "Mocking and Patching Pitfalls", от нашего уважаемого технического обозревателя Эда Юнга, который также рассматривает mocking и их альтернативы. И в то время как мы рекомендуем доклады, не пропустите Брэндона Родса, говорящего о "Hoisting Your I/O", который действительно хорошо охватывает проблемы, о которых мы говорим, используя еще один простой пример.
| В этой главе мы потратили много времени, заменяя сквозные тесты модульными. Это не значит, что мы считаем, что вы никогда не должны использовать тесты E2E! В этой книге мы показываем методы, которые помогут вам составить достойную пирамиду тестов с максимально возможным количеством модульных тестов и с минимальным количеством тестов E2E, необходимых для уверенности. Прочтите Резюме: Эмпирические правила для различных типов тестов для получения более подробной информации. |
4.4. Подведение итогов
Мы будем видеть эту идею в книге снова и снова: мы можем упростить тестирование и обслуживание наших систем, упростив интерфейс между нашей бизнес-логикой и беспорядочным вводом-выводом. Найти правильную абстракцию сложно, но вот несколько эвристик и вопросов, которые нужно задать себе:
-
Могу ли я выбрать знакомую структуру данных Python для представления состояния беспорядочной системы, а затем попытаться представить себе единственную функцию, которая может вернуть это состояние?
-
Где я могу провести границу между моими системами, где я смогу использовать шов чтобы вставить эту абстракцию?
-
Что такое разумный способ разделения объектов на компоненты с различными обязанностями? Какие неявные понятия я могу сделать явными?
-
Что же такое зависимость, и каковы основные бизнес-логики?
Практика делает его менее несовершенным! А теперь вернемся к нашим баранам нашему обычному программированию…
5. Наш первый Use Case или пример использования: Flask API и Service Layer
Вернемся к нашему исходному проекту! Схема Управляем приложением, общаясь с репозиторием и моделью домена показывает точку, которую мы достигли в конце Repository Pattern, которая включает в себя шаблон репозитория.
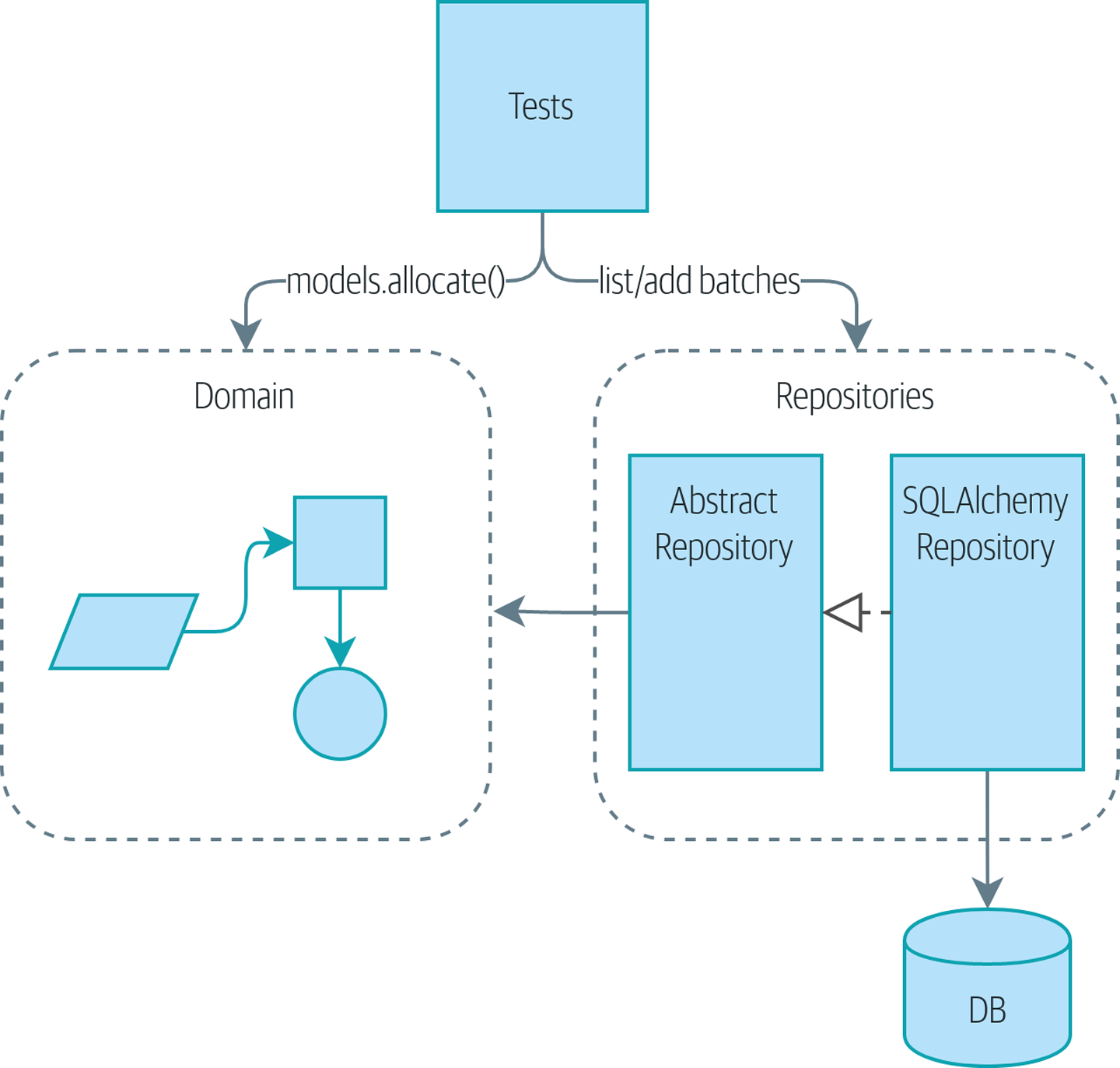
В этой главе мы обсудим различие между Orchestration logic, business logic и interfacing code, а также введем модель Service Layer для координации наших бизнес - процессов и определения вариантов использования системы.
Мы также обсудим тестирование: объединив уровень сервиса с нашей абстракцией репозитория над базой данных, мы можем писать быстрые тесты не только нашей модели предметной области, но и всего рабочего процесса для конкретного случая использования.
Схема Сервис будет основным способом доступа к нашим приложениям показывает, то к чему мы стремимся: Собираемся добавить API Flask, который будет общаться с уровнем сервиса, который будет служить точкой входа в нашу доменную модель. Поскольку наш уровень обслуживания зависит от AbstractRepository, мы можем модульно протестировать его с помощью FakeRepository, но запустить наш production код с помощью SqlAlchemyRepository.
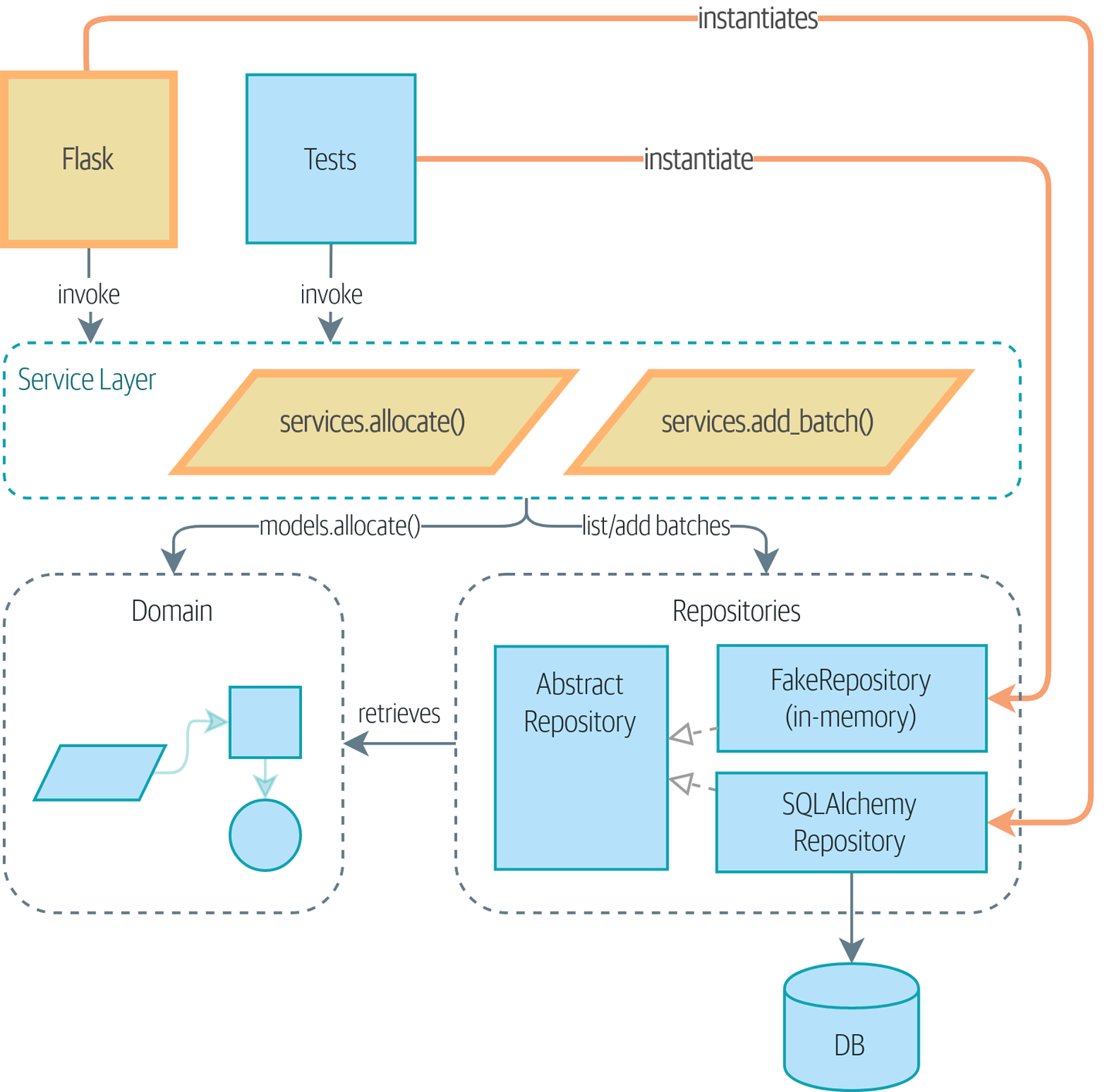
В наших диаграммах мы используем соглашение о том, что новые компоненты выделяются жирным шрифтом/линиями (и желтым/оранжевым цветом, если вы читаете цифровую версию).
|
Код этой главы находится в ветке chapter_04_service_layer on GitHub: git clone https://github.com/cosmicpython/code.git cd code git checkout chapter_04_service_layer # or to code along, checkout Chapter 2: git checkout chapter_02_repository |
5.1. Подключение нашего приложения к реальному миру
Как и любая другая команда, быстрая и проворная, мы пытаемся получить MVP (минимально жизнеспособный продукт) и собрать обратную связь на глазах у пользователей. У нас есть ядро нашей доменной модели и доменная служба, необходимая для распределения заказов, а также интерфейс репозитория для постоянного хранилища.
Давайте как можно скорее соединим все мобильные компоненты и перестроим их в более чистую архитектуру. Наш план таков:
-
Используем Flask, чтобы поместить endpoint API перед сервисом
allocate. Подключаем сеанс базы данных и наш репозиторий. Тестируем его с помощью сквозного теста и некоторого quick-and-dirty SQL для подготовки тестовых данных. Проводим сеанс работы с базой данных и нашим репозиторием. Протестируем его с помощью сквозного теста и небольшого количества quick-and-dirty SQL запросов для подготовки тестовых данных. -
Отрефакторим сервисный уровень, который будет служить абстракцией для захвата сценария использования и который будет находиться между Flask и нашей моделью домена. Построим несколько тестов сервисного уровня и покажем, как они могут использовать
FakeRepository. -
Поэкспериментируем с различными типами параметров для наших функций сервисного уровня; продемонстрируем, что использование примитивных типов данных позволяет отделить клиентов сервисного уровня (наши тесты и наш API Flask) от уровня модели.
5.2. Первый сквозной тест
Никто не заинтересован в долгих терминологических дебатах о том, что считается сквозным тестом (E2E) по сравнению с функциональным тестом по сравнению с приемочным тестом по сравнению с интеграционным тестом по сравнению с модульным тестом. Различные проекты нуждаются в различных комбинациях тестов, и мы видели, как совершенно успешные проекты просто делят вещи на "быстрые тесты" и "медленные тесты"."
На данный момент мы хотим написать один или, может быть, два теста, которые будут использовать "реальную" конечную точку API (используя HTTP) и общаться с реальной базой данных. Давайте назовем их сквозные тесты, потому что это одно из самых понятных названий.
Ниже показан первый разрез:
@pytest.mark.usefixtures('restart_api')
def test_api_returns_allocation(add_stock):
sku, othersku = random_sku(), random_sku('other') (1)
earlybatch = random_batchref(1)
laterbatch = random_batchref(2)
otherbatch = random_batchref(3)
add_stock([ (2)
(laterbatch, sku, 100, '2011-01-02'),
(earlybatch, sku, 100, '2011-01-01'),
(otherbatch, othersku, 100, None),
])
data = {'orderid': random_orderid(), 'sku': sku, 'qty': 3}
url = config.get_api_url() (3)
r = requests.post(f'{url}/allocate', json=data)
assert r.status_code == 201
assert r.json()['batchref'] == earlybatch| 1 | random_sku(), random_batchref () и так далее — это небольшие вспомогательные функции, которые генерируют случайные символы с помощью модуля uuid. Поскольку сейчас мы работаем с реальной базой данных, это один из способов предотвратить взаимное влияние различных тестов друг на друга. |
| 2 | add_stock — это вспомогательная фикстура, инструмент, который просто скрывает детали ручной вставки строк в базу данных с помощью SQL. В конце этой главы мы покажем способ получше. |
| 3 | config.py это модуль, в котором мы храним информацию о конфигурации. |
Все решают эти проблемы по-разному, но вам понадобится какой-то способ развернуть Flask, возможно, в контейнере, и пообщаться с базой данных Postgres. Если вы хотите увидеть, как мы это сделали, ознакомьтесь Шаблонная структура проекта.
5.3. Простая Реализация
Реализуя вещи самым очевидным образом, вы можете получить что-то вроде этого:
from flask import Flask, jsonify, request
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
import config
import model
import orm
import repository
orm.start_mappers()
get_session = sessionmaker(bind=create_engine(config.get_postgres_uri()))
app = Flask(__name__)
@app.route("/allocate", methods=['POST'])
def allocate_endpoint():
session = get_session()
batches = repository.SqlAlchemyRepository(session).list()
line = model.OrderLine(
request.json['orderid'],
request.json['sku'],
request.json['qty'],
)
batchref = model.allocate(line, batches)
return jsonify({'batchref': batchref}), 201Пока всё слишком хорошо. Боб и Гарри, вы наверное думаете, что вам больше не нужно говорить про "архитектурных астронавтов".
Но подождите минутку — никаких обязательств. На самом деле мы не сохраняем наше распределение в базе данных. Теперь нам нужен второй тест, либо тот, который проверит состояние базы данных после (не очень black-boxy чёрного ящика), или, может быть, тот, который проверяет, что мы не можем выделить вторую строку, если первая уже должна была исчерпать пакет:
@pytest.mark.usefixtures('restart_api')
def test_allocations_are_persisted(add_stock):
sku = random_sku()
batch1, batch2 = random_batchref(1), random_batchref(2)
order1, order2 = random_orderid(1), random_orderid(2)
add_stock([
(batch1, sku, 10, '2011-01-01'),
(batch2, sku, 10, '2011-01-02'),
])
line1 = {'orderid': order1, 'sku': sku, 'qty': 10}
line2 = {'orderid': order2, 'sku': sku, 'qty': 10}
url = config.get_api_url()
# первый заказ использует все запасы в партии 1
r = requests.post(f'{url}/allocate', json=line1)
assert r.status_code == 201
assert r.json()['batchref'] == batch1
# второй заказ должен перейти в партию 2
r = requests.post(f'{url}/allocate', json=line2)
assert r.status_code == 201
assert r.json()['batchref'] == batch2Не совсем так красиво, но это заставит нас добавить коммит.
5.4. Ошибочные условия требуют проверки базы данных
Если мы будем продолжать в том же духе, все станет ещё хуже и хуже.
Предположим, что мы добавим несколько обработок ошибок. Что делать, если домен вызывает ошибку для SKU, которого нет в наличии? Или как насчет SKU, которого даже не существует? Об этом домен даже не знает, да и не должен знать. Это скорее проверка на вменяемость, которую мы должны применить на уровне базы данных, прежде чем мы даже вызовем службу домена.
Теперь мы рассмотрим еще пару сквозных теста:
@pytest.mark.usefixtures('restart_api')
def test_400_message_for_out_of_stock(add_stock): (1)
sku, smalL_batch, large_order = random_sku(), random_batchref(), random_orderid()
add_stock([
(smalL_batch, sku, 10, '2011-01-01'),
])
data = {'orderid': large_order, 'sku': sku, 'qty': 20}
url = config.get_api_url()
r = requests.post(f'{url}/allocate', json=data)
assert r.status_code == 400
assert r.json()['message'] == f'Out of stock for sku {sku}'
@pytest.mark.usefixtures('restart_api')
def test_400_message_for_invalid_sku(): (2)
unknown_sku, orderid = random_sku(), random_orderid()
data = {'orderid': orderid, 'sku': unknown_sku, 'qty': 20}
url = config.get_api_url()
r = requests.post(f'{url}/allocate', json=data)
assert r.status_code == 400
assert r.json()['message'] == f'Invalid sku {unknown_sku}'| 1 | В первом тесте мы пытаемся выделить больше единиц, чем есть на складе. |
| 2 | Во втором случае SKU просто не существует (потому что мы никогда не вызывали add_stock), поэтому он недействителен для нашего приложения. |
И конечно, мы могли бы реализовать его и в приложении Flask:
def is_valid_sku(sku, batches):
return sku in {b.sku for b in batches}
@app.route("/allocate", methods=['POST'])
def allocate_endpoint():
session = get_session()
batches = repository.SqlAlchemyRepository(session).list()
line = model.OrderLine(
request.json['orderid'],
request.json['sku'],
request.json['qty'],
)
if not is_valid_sku(line.sku, batches):
return jsonify({'message': f'Invalid sku {line.sku}'}), 400
try:
batchref = model.allocate(line, batches)
except model.OutOfStock as e:
return jsonify({'message': str(e)}), 400
session.commit()
return jsonify({'batchref': batchref}), 201Но наше приложение Flask начинает выглядеть слегка громоздким. И наше количество тестов E2E начинает выходить из-под контроля, и вскоре мы получим перевернутую тестовую пирамиду (или "модель рожка мороженого", как любит называть ее Боб).
5.5. Представляем сервисный слой и используем FakeRepository для его модульного тестирования
Если мы посмотрим на то, что делает наше приложение Flask, то увидим довольно много того, что мы могли бы назвать orchestration —- извлечение материала из нашего репозитория, проверка наших входных данных на соответствие состоянию базы данных, обработка ошибок и фиксация в happy path. Большинство из этих вещей не имеют ничего общего с наличием web API endpoint (они понадобились бы вам, если бы вы создавали, например CLI; см. Замена инфраструктуры: Делайте все с CSV), и на самом деле это не те вещи, которые нужно тестировать сквозными тестами.
Часто имеет смысл разделить service layer, иногда называемый orchestration layer слоем оркестровки или use-case слоем прецедентов .
Вы помните "FakeRepository", который мы подготовили в Краткая интерлюдия: О Связях и Абстракции?
class FakeRepository(repository.AbstractRepository):
def __init__(self, batches):
self._batches = set(batches)
def add(self, batch):
self._batches.add(batch)
def get(self, reference):
return next(b for b in self._batches if b.reference == reference)
def list(self):
return list(self._batches)Вот где он будет полезен; он позволяет нам тестировать наш уровень обслуживания с помощью хороших, быстрых модульных тестов:
def test_returns_allocation():
line = model.OrderLine("o1", "COMPLICATED-LAMP", 10)
batch = model.Batch("b1", "COMPLICATED-LAMP", 100, eta=None)
repo = FakeRepository([batch]) (1)
result = services.allocate(line, repo, FakeSession()) (2) (3)
assert result == "b1"
def test_error_for_invalid_sku():
line = model.OrderLine("o1", "NONEXISTENTSKU", 10)
batch = model.Batch("b1", "AREALSKU", 100, eta=None)
repo = FakeRepository([batch]) (1)
with pytest.raises(services.InvalidSku, match="Invalid sku NONEXISTENTSKU"):
services.allocate(line, repo, FakeSession()) (2) (3)| 1 | FakeRepository содержит объекты Batch, которые будут использоваться в нашем тесте. |
| 2 | Наш сервисный модуль (services.py) определит функцию сервисного уровня allocate(). Он будет находиться между нашей функцией allocate_endpoint() на уровне API и функцией доменной службы allocate() из нашей модели домена.[27] |
| 3 | Нам также нужен "FakeSession", чтобы подделать сеанс базы данных, как показано в следующем фрагменте кода. |
class FakeSession():
committed = False
def commit(self):
self.committed = TrueЭта фальшивая сессия - лишь временное решение. Мы скоро избавимся от него и сделаем все лучше. Паттерн Unit of Work(Единица работы). Но в то же время фейковый .commit() позволяет нам перенести третий тест со слоя E2E:
def test_commits():
line = model.OrderLine('o1', 'OMINOUS-MIRROR', 10)
batch = model.Batch('b1', 'OMINOUS-MIRROR', 100, eta=None)
repo = FakeRepository([batch])
session = FakeSession()
services.allocate(line, repo, session)
assert session.committed is True5.5.1. Типичная Service Function
Мы напишем служебную функцию, которая выглядит примерно так:
class InvalidSku(Exception):
pass
def is_valid_sku(sku, batches):
return sku in {b.sku for b in batches}
def allocate(line: OrderLine, repo: AbstractRepository, session) -> str:
batches = repo.list() (1)
if not is_valid_sku(line.sku, batches): (2)
raise InvalidSku(f'Invalid sku {line.sku}')
batchref = model.allocate(line, batches) (3)
session.commit() (4)
return batchrefТипичные функции сервисного уровня имеют сходные этапы:
| 1 | Извлекаем некоторые объекты из репозитория. |
| 2 | Мы делаем несколько подтверждений или опровергаем требования о текущем состоянии мира. |
| 3 | Мы вызываем доменную службу. |
| 4 | Если все хорошо, то мы сохраняем/обновляем любое состояние, которое мы изменили. |
Этот последний шаг на данный момент несовсем удовлетворителен, поскольку наш сервисный уровень тесно связан с нашим уровнем базы данных. Мы улучшим это в Паттерн Unit of Work(Единица работы) с помощью шаблона Unit of Work.
Но самое необходимое для уровня сервиса уже есть, и наше приложение Flask теперь выглядит намного чище:
@app.route("/allocate", methods=['POST'])
def allocate_endpoint():
session = get_session() (1)
repo = repository.SqlAlchemyRepository(session) (1)
line = model.OrderLine(
request.json['orderid'], (2)
request.json['sku'], (2)
request.json['qty'], (2)
)
try:
batchref = services.allocate(line, repo, session) (2)
except (model.OutOfStock, services.InvalidSku) as e:
return jsonify({'message': str(e)}), 400 (3)
return jsonify({'batchref': batchref}), 201 (3)| 1 | Инстанцируем сеанс работы с базой данных и некоторые объекты репозитория. |
| 2 | Извлекаем команды пользователя из веб-запроса и передаем их службе домена. |
| 3 | Возвращаем несколько ответов JSON с соответствующими кодами состояния. |
Обязанности приложения Flask - это обычные веб-вещи: управление сеансами по каждому запросу, анализ информации из параметров POST, коды состояния ответа и JSON. Вся логика оркестрации находится на уровне использования case/service, а логика домена остается в домене.
Наконец, мы можем уверенно разделить наши тесты E2E всего на два: один для пути удачных решений и один для неверного выбора:
@pytest.mark.usefixtures('restart_api')
def test_happy_path_returns_201_and_allocated_batch(add_stock):
sku, othersku = random_sku(), random_sku('other')
earlybatch = random_batchref(1)
laterbatch = random_batchref(2)
otherbatch = random_batchref(3)
add_stock([
(laterbatch, sku, 100, '2011-01-02'),
(earlybatch, sku, 100, '2011-01-01'),
(otherbatch, othersku, 100, None),
])
data = {'orderid': random_orderid(), 'sku': sku, 'qty': 3}
url = config.get_api_url()
r = requests.post(f'{url}/allocate', json=data)
assert r.status_code == 201
assert r.json()['batchref'] == earlybatch
@pytest.mark.usefixtures('restart_api')
def test_unhappy_path_returns_400_and_error_message():
unknown_sku, orderid = random_sku(), random_orderid()
data = {'orderid': orderid, 'sku': unknown_sku, 'qty': 20}
url = config.get_api_url()
r = requests.post(f'{url}/allocate', json=data)
assert r.status_code == 400
assert r.json()['message'] == f'Invalid sku {unknown_sku}'Мы успешно разделили наши тесты на две большие категории: тесты на веб-материалы, которые мы реализуем от начала до конца; и тесты, связанные с оркестровкой, которые мы можем протестировать на уровне сервиса в памяти.
5.6. Почему всё называется сервисом?
Некоторые из вас, вероятно, сейчас ломают голову, пытаясь точно понять, в чем разница между доменным сервисом и уровнем сервиса.
К сожалению, не мы выбрали имена, иначе у нас были бы более разумные и дружелюбные способы поговорить об этом.
В этой главе мы используем две вещи, называемые service. Первый-это application service (наш service layer). Его работа заключается в обработке запросов из внешнего мира и в orchestrate операции. Мы имеем в виду, что уровень сервиса управляет приложением, следуя нескольким простым шагам:
-
Получить некоторые данные из базы данных
-
Обновить модели домена
-
Сохранить любые изменения
Это рутина, которая должна выполняться для каждой операции в вашей системе, и отделение её от бизнес-логики помогает поддерживать порядок.
Второй тип сервиса-это domain service. Это имя для части логики, которая принадлежит модели предметной области, но не находится естественным образом внутри состояния сущности или value object. Например, если вы создаете приложение для корзины покупок, вы можете выбрать создание правил налогообложения в качестве доменной службы. Расчет налога-это отдельная работа от обновления корзины, и это важная часть модели, но не кажется правильным иметь постоянную сущность для этой работы. Вместо этого эту работу может выполнять класс TaxCalculator или функция calculate_tax.
5.7. Разложим всё по папкам, чтобы увидеть, чему всё это принадлежит
По мере того, как приложения становятся все больше и больше, нам необходимо постоянно обновлять структуру каталогов. Компоновка проекта предоставляет полезные советы о том, что в каком файле находится.
Мы можем организовать все так:
.
├── config.py
├── domain (1)
│ ├── __init__.py
│ └── model.py
├── service_layer (2)
│ ├── __init__.py
│ └── services.py
├── adapters (3)
│ ├── __init__.py
│ ├── orm.py
│ └── repository.py
├── entrypoints (4)
│ ├── __init__.py
│ └── flask_app.py
└── tests
├── __init__.py
├── conftest.py
├── unit
│ ├── test_allocate.py
│ ├── test_batches.py
│ └── test_services.py
├── integration
│ ├── test_orm.py
│ └── test_repository.py
└── e2e
└── test_api.py| 1 | Давайте создадим папку для нашей доменной модели.
В настоящее время это всего лишь один файл, но для более сложного приложения у
вас может быть один файл на класс; у вас могут быть вспомогательные родительские классы для Entity, ValueObject, и Aggregate, и вы могли бы добавить
exceptions.py для исключений доменного уровня и, как вы увидите в Событийно-Ориентированная архитектура, commands.py и events.py.
|
| 2 | Мы будем различать уровень обслуживания. В настоящее время это всего лишь один файл с именем services.py для наших функций сервисного уровня. Здесь вы можете добавить исключения сервисного уровня, и, как вы увидите в TDD на Высокой и Низкой передаче, мы добавим unit_of_work.py. |
| 3 | Adapters - это дань терминологии портов и адаптеров. Это заполнит любые другие абстракции вокруг внешнего I/O (напр., a redis_client.py). Строго говоря, вы бы назвали эти адаптеры secondary или driven адаптерами, или иногда inward-facing адаптерами. |
| 4 | Точки входа entrypoints — это места, откуда мы управляем нашим приложением. В официальной терминологии портов и адаптеров они тоже являются адаптерами и называются адаптерами primary первичными, driving управляющими или outward-facing обращенными наружу. |
А как насчет портов? Как вы помните, это абстрактные интерфейсы, которые реализуют адаптеры. Мы склонны хранить их в том же файле, что и адаптеры, которые их реализуют.
5.8. Резюме
Добавление service layer уровня сервиса даёт немало преимуществ.
-
Наши entrypoints Flask API становятся очень тонкими и легкими в написании: их единственная обязанность-делать "web stuff", такие как разбор JSON и создание правильных HTTP-кодов для удачных или неудачных случаев.
-
Мы определили четкий API для нашего домена, набор вариантов использования или точек входа, которые могут быть использованы любым адаптером без необходимости знать что-либо о наших классах моделей домена-будь то API, CLI (см. Замена инфраструктуры: Делайте все с CSV) или тесты! Они также являются адаптером для нашего домена.
-
Мы можем писать тесты на «высокой скорости», используя уровень сервиса, что дает нам возможность рефакторинга модели предметной области любым способом, который мы сочтем нужным. Пока мы можем предоставлять те же сценарии использования, мы можем экспериментировать с новыми проектами без необходимости переписывать множество тестов.
-
И наша пирамида тестирования выглядит неплохо — большая часть наших тестов — это быстрые модульные тесты, с минимальным количеством E2E и интеграционных тестов.
5.8.1. DIP в действии
Abstract dependencies of the service layer показывает зависимости нашего уровня сервиса: модель предметной области и AbstractRepository (порт в терминологии портов и адаптеров).
Когда мы запускаем тесты, Tests provide an implementation of the abstract dependency показывает, как мы реализуем абстрактные зависимости с помощью FakeRepository (адаптера).
И когда мы на самом деле запускаем наше приложение, мы меняем "реальную" зависимость, показанную в Dependencies at runtime.
[ditaa, apwp_0403]
+-----------------------------+
| Service Layer |
+-----------------------------+
| |
| | depends on abstraction
V V
+------------------+ +--------------------+
| Domain Model | | AbstractRepository |
| | | (Port) |
+------------------+ +--------------------+

[ditaa, apwp_0404]
+-----------------------------+
| Tests |-------------\
+-----------------------------+ |
| |
V |
+-----------------------------+ |
| Service Layer | provides |
+-----------------------------+ |
| | |
V V |
+------------------+ +--------------------+ |
| Domain Model | | AbstractRepository | |
+------------------+ +--------------------+ |
^ |
implements | |
| |
+----------------------+ |
| FakeRepository |<--/
| (in–memory) |
+----------------------+
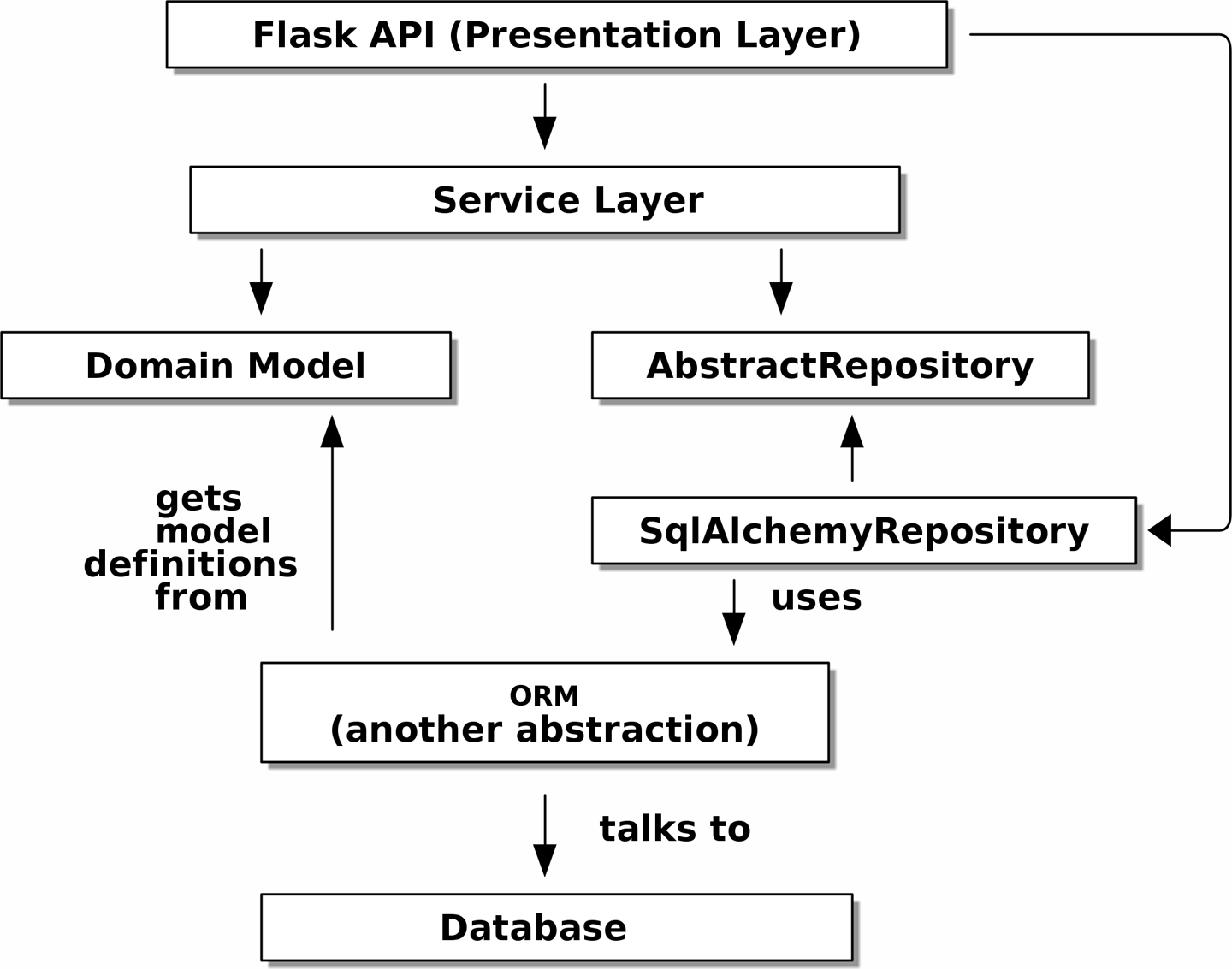
[ditaa, apwp_0405]
+--------------------------------+
| Flask API (Presentation Layer) |-----------\
+--------------------------------+ |
| |
V |
+-----------------------------+ |
| Service Layer | |
+-----------------------------+ |
| | |
V V |
+------------------+ +--------------------+ |
| Domain Model | | AbstractRepository | |
+------------------+ +--------------------+ |
^ ^ |
| | |
gets | +----------------------+ |
model | | SqlAlchemyRepository |<--/
definitions| +----------------------+
from | | uses
| V
+-----------------------+
| ORM |
| (another abstraction) |
+-----------------------+
|
| talks to
V
+------------------------+
| Database |
+------------------------+
Чудесно.
Давайте сделаем паузу для Service layer: Компромиссы, в которой мы рассмотрим плюсы и минусы наличия service layer вообще.
| Плюсы | Минусы |
|---|---|
|
|
Но есть еще несколько неловких моментов, которые нужно убрать:
-
Уровень сервиса по-прежнему тесно связан с доменом, поскольку его API выражается в терминах объектов
OrderLine. В TDD на Высокой и Низкой передаче мы исправим это и поговорим о том, как уровень сервиса обеспечивает более производительный TDD. -
Уровень сервиса тесно связан с объектом
session. В Паттерн Unit of Work(Единица работы) мы введем еще один паттерн, который тесно работает с паттернами Уровня Репозитория и Сервиса, паттерн Unit of Work, и все будет абсолютно прекрасно. Вот увидите!
6. TDD на Высокой и Низкой передаче
Мы ввели уровень сервиса, чтобы захватить некоторые дополнительные обязанности по оркестровке, которые нам нужны от рабочего приложения. Уровень сервиса помогает нам четко определить наши варианты использования и рабочий процесс для каждого из них: что нам нужно получить из наших репозиториев, какие предварительные проверки и проверку текущего состояния мы должны сделать, и что мы сохраняем в конце.
Но в настоящее время многие из наших модульных тестов работают на более низком уровне, воздействуя непосредственно на модель. В этой главе мы обсудим компромиссы, связанные с переносом этих тестов на уровень сервисного уровня, и некоторые более общие рекомендации по тестированию.
6.1. Как выглядит наша тестовая пирамида?
Давайте посмотрим, что этот переход к использованию сервисного уровня с его собственными тестами сервисного уровня делает с нашей тестовой пирамидой:
$ grep -c test_ **/test_*.py
tests/unit/test_allocate.py:4
tests/unit/test_batches.py:8
tests/unit/test_services.py:3
tests/integration/test_orm.py:6
tests/integration/test_repository.py:2
tests/e2e/test_api.py:2Неплохо! У нас есть 15 модульных тестов, 8 интеграционных тестов и всего 2 сквозных теста. Это уже здоровая на вид тестовая пирамида.
6.2. Должны ли тесты доменного уровня перейти на уровень сервиса?
Посмотрим, что произойдет, если мы сделаем еще один шаг. Поскольку мы можем тестировать наше программное обеспечение на уровне сервисов, нам больше не нужны тесты для модели предметной области. Вместо этого мы могли бы переписать все тесты уровня домена из Domain Modeling с точки зрения уровня обслуживания:
# domain-layer test:
def test_prefers_current_stock_batches_to_shipments():
in_stock_batch = Batch("in-stock-batch", "RETRO-CLOCK", 100, eta=None)
shipment_batch = Batch("shipment-batch", "RETRO-CLOCK", 100, eta=tomorrow)
line = OrderLine("oref", "RETRO-CLOCK", 10)
allocate(line, [in_stock_batch, shipment_batch])
assert in_stock_batch.available_quantity == 90
assert shipment_batch.available_quantity == 100
# service-layer test:
def test_prefers_warehouse_batches_to_shipments():
in_stock_batch = Batch("in-stock-batch", "RETRO-CLOCK", 100, eta=None)
shipment_batch = Batch("shipment-batch", "RETRO-CLOCK", 100, eta=tomorrow)
repo = FakeRepository([in_stock_batch, shipment_batch])
session = FakeSession()
line = OrderLine('oref', "RETRO-CLOCK", 10)
services.allocate(line, repo, session)
assert in_stock_batch.available_quantity == 90
assert shipment_batch.available_quantity == 100Зачем нам это нужно?
Предполагается, что тесты помогают нам безбоязненно изменять нашу систему, но часто мы видим, как команды пишут слишком много тестов для своей модели предметной области. Это вызывает проблемы, когда они приходят изменить свою кодовую базу и обнаруживают, что им необходимо обновить десятки или даже сотни модульных тестов.
В этом есть смысл, если вы перестанете задумываться о назначении автоматических тестов. Мы используем тесты, чтобы убедиться, что свойство системы не меняется во время работы. Мы используем тесты, чтобы проверить, что API продолжает возвращать 200, что сеанс базы данных продолжает фиксироваться и что заказы все еще распределяются.
Если мы случайно изменим одно из этих поведений, наши тесты сломаются. Однако оборотная сторона состоит в том, что если мы захотим изменить дизайн нашего кода, любые тесты, напрямую полагающиеся на этот код, также потерпят неудачу.
По мере того, как мы углубимся в книгу, вы увидите, как уровень сервиса формирует API для нашей системы, которым мы можем управлять разными способами. Тестирование этого API сокращает объем кода, который нам нужно изменить при рефакторинге нашей модели предметной области. Если мы ограничимся тестированием только на уровне сервиса, у нас не будет никаких тестов, которые напрямую взаимодействуют с «частными» методами или атрибутами объектов нашей модели, что дает нам больше свободы для их рефакторинга.
| Каждая строка кода, которую мы помещаем в тест, подобна капле клея, удерживающему систему в определенной форме. Чем больше у нас будет тестов низкого уровня, тем труднее будет что-то изменить. |
6.3. О принятии решения О том, Какие Тесты писать
Вы можете спросить себя: «А стоит ли мне тогда переписать все свои модульные тесты? Разве неправильно писать тесты для модели предметной области?» Чтобы ответить на эти вопросы, важно понимать компромисс между связью и обратной связью по проекту (см. Тестовый спектр).

[ditaa, apwp_0501] | Низкая обратная связь Высокая обратная связь | | Низкий барьер для изменений Высокий барьер для перемен | | Высокий охват системы Сфокусированное покрытие | | | | <--------- ----------> | | | | API Tests Service–Layer Tests Domain Tests |
Экстремальное программирование (XP) призывает нас «слушать код». Когда мы пишем тесты, мы можем обнаружить, что код трудно использовать, или заметим запах кода. Это повод для рефакторинга и пересмотра нашего дизайна.
Однако мы получаем эту обратную связь только тогда, когда тесно работаем с целевым кодом. Тест HTTP API ничего не говорит нам о детальном дизайне наших объектов, потому что он находится на гораздо более высоком уровне абстракции.
С другой стороны, мы можем переписать все наше приложение, и, пока мы не меняем URL-адреса или форматы запросов, наши HTTP-тесты будут продолжать проходить. Это дает нам уверенность в том, что крупномасштабные изменения, такие как изменение схемы базы данных, не нарушили наш код.
На другом конце спектра тесты, которые мы написали в Domain Modeling, помогли нам конкретизировать наше понимание необходимых нам объектов. Тесты привели нас к разработке, которая имеет смысл и читается на языке предметной области. Когда наши тесты читаются на языке предметной области, мы чувствуем себя комфортно, потому что наш код соответствует нашей интуиции относительно проблемы, которую мы пытаемся решить.
Поскольку тесты написаны на языке предметной области, они служат живой документацией для нашей модели. Новый член команды может прочитать эти тесты, чтобы быстро понять, как работает система и как взаимосвязаны основные концепции.
Мы часто «зарисовываем» новое поведение, написав тесты на этом уровне, чтобы увидеть, как может выглядеть код. Однако, когда мы хотим улучшить дизайн кода, нам нужно будет заменить или удалить эти тесты, потому что они тесно связаны с конкретной implementation реализацей.
6.4. Высокая и низкая передача
В большинстве случаев, когда мы добавляем новую функцию или исправляем ошибку, нам не нужно вносить значительные изменения в модель домена. В этих случаях мы предпочитаем писать тесты против сервисов из-за более низкой связи и более высокого покрытия.
Например, при написании функции add_stock или функции cancel_order мы можем работать быстрее и с меньшей связью, написав тесты на уровне сервиса.
Когда мы начинаем новый проект или сталкиваемся с особенно сложной проблемой, мы возвращаемся к написанию тестов против модели предметной области, чтобы получить лучшую обратную связь и исполняемую документацию о наших намерениях.
Мы используем в качестве метафоры термины переключения передач. В начале поездки велосипед должен быть на пониженной передаче, чтобы он мог преодолеть инерцию. Когда мы тронемся и бежим, мы можем двигаться быстрее и эффективнее, переключившись на повышенную передачу; но если мы внезапно наталкиваемся на крутой холм или вынуждены замедляться из-за опасности, мы снова переключаемся на низкую передачу, пока не сможем снова набрать скорость.
6.5. Полное отделение тестов уровня сервиса от домена
У нас все еще есть прямые зависимости от домена в наших тестах уровня обслуживания, потому что мы используем объекты домена для настройки наших тестовых данных и вызова наших функций уровня обслуживания.
Чтобы иметь уровень сервиса, который полностью отделен от домена, нам нужно переписать его API, чтобы работать в терминах примитивов.
Наш уровень обслуживания в настоящее время принимает доменный объект OrderLine:
def allocate(line: OrderLine, repo: AbstractRepository, session) -> str:Как бы это выглядело, если бы все его параметры были примитивными типами?
def allocate(
orderid: str, sku: str, qty: int, repo: AbstractRepository, session
) -> str:Мы также переписываем тесты в этих терминах:
def test_returns_allocation():
batch = model.Batch("batch1", "COMPLICATED-LAMP", 100, eta=None)
repo = FakeRepository([batch])
result = services.allocate("o1", "COMPLICATED-LAMP", 10, repo, FakeSession())
assert result == "batch1"Но наши тесты все еще зависят от домена, потому что мы все еще вручную создаем экземпляры Batch объектов. Поэтому, если в один прекрасный день мы решим провести массовый рефакторинг того, как работает наша Batch модель, нам придется изменить кучу тестов.
6.5.1. Смягчение последствий: Храните Все доменные зависимости в функциях Fixture
Мы могли бы, по крайней мере, абстрагировать это до вспомогательной функции или фикстуры в наших тестах. Вот один из способов, которым вы могли бы это сделать, добавив фабричную функцию в FakeRepository:
class FakeRepository(set):
@staticmethod
def for_batch(ref, sku, qty, eta=None):
return FakeRepository([
model.Batch(ref, sku, qty, eta),
])
...
def test_returns_allocation():
repo = FakeRepository.for_batch("batch1", "COMPLICATED-LAMP", 100, eta=None)
result = services.allocate("o1", "COMPLICATED-LAMP", 10, repo, FakeSession())
assert result == "batch1"По крайней мере, это переместило бы все зависимости наших тестов из домена в одно место.
6.5.2. Добавление отсутствующей службы
Но мы могли бы сделать еще один шаг. Если бы у нас был сервис для добавления запасов, мы могли бы использовать его и сделать наши тесты уровня сервиса полностью выраженными в терминах официальных вариантов использования уровня сервиса, удалив все зависимости от домена:
def test_add_batch():
repo, session = FakeRepository([]), FakeSession()
services.add_batch("b1", "CRUNCHY-ARMCHAIR", 100, None, repo, session)
assert repo.get("b1") is not None
assert session.committed| В общем, если вам нужно делать что-то на уровне домена непосредственно в тестах уровня сервиса, это может быть признаком того, что ваш уровень сервиса не завершен. |
А реализация — это всего две строчки:
def add_batch(
ref: str, sku: str, qty: int, eta: Optional[date],
repo: AbstractRepository, session,
):
repo.add(model.Batch(ref, sku, qty, eta))
session.commit()
def allocate(
orderid: str, sku: str, qty: int, repo: AbstractRepository, session
) -> str:
...
Стоит ли писать новую службу только потому, что она поможет устранить зависимости из ваших тестов? Возможно нет. Но в этом случае нам почти наверняка однажды понадобится сервис add_batch.
так или иначе.
|
Теперь это позволяет нам переписать все наши тесты сервисного уровня исключительно с точки зрения самих сервисов, используя только примитивы и без каких-либо зависимостей от модели:
def test_allocate_returns_allocation():
repo, session = FakeRepository([]), FakeSession()
services.add_batch("batch1", "COMPLICATED-LAMP", 100, None, repo, session)
result = services.allocate("o1", "COMPLICATED-LAMP", 10, repo, session)
assert result == "batch1"
def test_allocate_errors_for_invalid_sku():
repo, session = FakeRepository([]), FakeSession()
services.add_batch("b1", "AREALSKU", 100, None, repo, session)
with pytest.raises(services.InvalidSku, match="Invalid sku NONEXISTENTSKU"):
services.allocate("o1", "NONEXISTENTSKU", 10, repo, FakeSession())Это действительно хорошее место. Наши тесты уровня сервиса зависят только от самого уровня сервиса, что дает нам полную свободу для рефакторинга модели по своему усмотрению.
6.6. Внесение улучшений в тесты E2E
Точно так же, как добавление add_batch помогло отделить наши тесты сервисного уровня от модели, добавление конечной точки API для добавления пакета устранило бы необходимость в уродливом приспособлении add_stock, и наши тесты E2E могли бы быть свободны от этих жестко закодированных SQL-запросов и прямой зависимости от базы данных.
Благодаря нашей сервисной функции добавить endpoint очень просто, требуется всего лишь немного порботать с JSON и один раз вызвать функцию:
@app.route("/add_batch", methods=['POST'])
def add_batch():
session = get_session()
repo = repository.SqlAlchemyRepository(session)
eta = request.json['eta']
if eta is not None:
eta = datetime.fromisoformat(eta).date()
services.add_batch(
request.json['ref'], request.json['sku'], request.json['qty'], eta,
repo, session
)
return 'OK', 201| Вы думаете про себя, POST to _ /add_batch_? Это не очень RESTful! Вы совершенно правы. Мы, к счастью, небрежны, но если вы хотите сделать все более RESTy, возможно, POST to /batches,тогда сам щёлкни себя по носу! Поскольку Flask - тонкий адаптер, это будет несложно. See the next sidebar. |
И наши жестко закодированные SQL-запросы из conftest.py заменяются некоторыми вызовами API, что означает, что тесты API не имеют никаких зависимостей, кроме API, что тоже неплохо:
def post_to_add_batch(ref, sku, qty, eta):
url = config.get_api_url()
r = requests.post(
f'{url}/add_batch',
json={'ref': ref, 'sku': sku, 'qty': qty, 'eta': eta}
)
assert r.status_code == 201
@pytest.mark.usefixtures('postgres_db')
@pytest.mark.usefixtures('restart_api')
def test_happy_path_returns_201_and_allocated_batch():
sku, othersku = random_sku(), random_sku('other')
earlybatch = random_batchref(1)
laterbatch = random_batchref(2)
otherbatch = random_batchref(3)
post_to_add_batch(laterbatch, sku, 100, '2011-01-02')
post_to_add_batch(earlybatch, sku, 100, '2011-01-01')
post_to_add_batch(otherbatch, othersku, 100, None)
data = {'orderid': random_orderid(), 'sku': sku, 'qty': 3}
url = config.get_api_url()
r = requests.post(f'{url}/allocate', json=data)
assert r.status_code == 201
assert r.json()['batchref'] == earlybatch6.7. Заключение
Как только у вас появится уровень сервиса, вы действительно можете переместить большую часть тестового покрытия в модульные тесты и разработать здоровую пирамиду тестов.
В этом вам помогут несколько вещей:
-
Выражайте уровень обслуживания в терминах примитивов, а не объектов предметной области.
-
В идеальном мире у вас будут все сервисы, которые вам нужны, чтобы иметь возможность полностью протестировать уровень сервиса, а не взламывать состояние через репозитории или базу данных. Это также окупается в ваших сквозных тестах.
Переходим к следующей главе!
7. Паттерн Unit of Work(Единица работы)
В этой главе мы познакомимся с заключительной частью головоломки, которая связывает воедино паттерны уровня Репозитория и Уровня Сервиса: паттерн Unit of Work.
Если шаблон хранилища-это наша абстракция по отношению к идее постоянного хранения, то шаблон "Единицы Работы" (UoW) - это наша абстракция по отношению к идее атомарных операций. Это позволит нам окончательно и полностью отделить наш уровень обслуживания от уровня данных.
Без UoW: API напрямую общается с тремя уровнями показывает, что в настоящее время много взаимодействий происходит между уровнями нашей инфраструктуры: API обращается напрямую к уровню базы данных, чтобы начать сеанс, он обращается к уровню репозитория для инициализации SQLAlchemyRepository, и он связывается с уровнем сервиса, чтобы выделить позиции.
|
Код для этой главы находится в ветке chapter_06_uow on GitHub: git clone https://github.com/cosmicpython/code.git cd code git checkout chapter_06_uow # or to code along, checkout Chapter 4: git checkout chapter_04_service_layer |
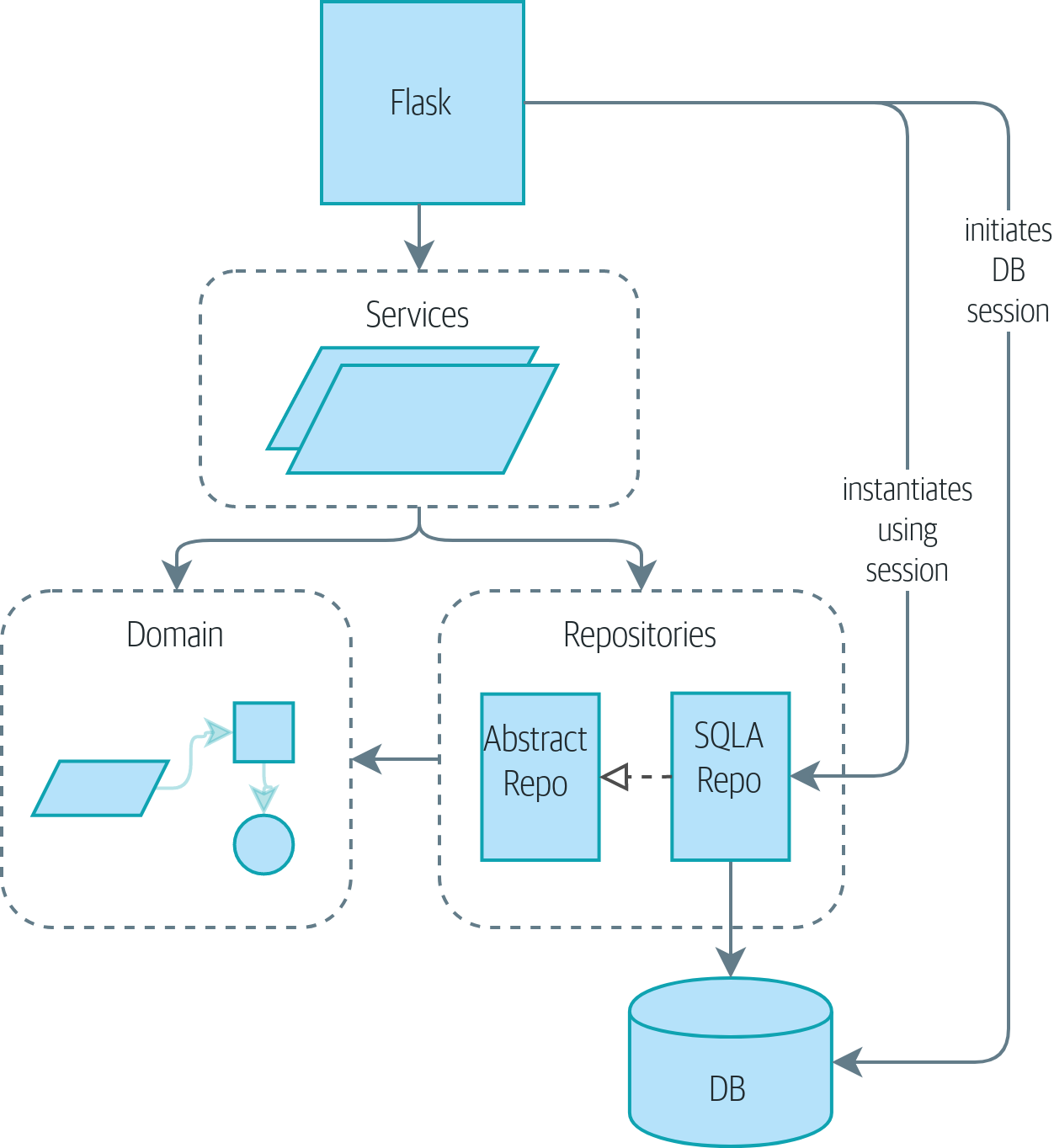
С помощью UoW: UoW теперь управляет состоянием базы данных показывает наше целевое состояние. API Flask теперь делает только две вещи: он инициализирует единицу работы и вызывает службу. Сервис сотрудничает с UoW (нам нравится думать о UoW как о части сервисного уровня), но ни сама сервисная функция, ни Flask теперь не нуждаются в непосредственном общении с базой данных.
И мы сделаем все это с помощью прекрасного синтаксиса Python - диспетчера контекста.

7.1. Unit of Work взаимодействует с репозиторием
Давайте посмотрим, как работает единица работы (или UoW, что мы произносим как «you-wow»). Вот как будет выглядеть сервисный слой, когда мы закончим:
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork
) -> str:
line = OrderLine(orderid, sku, qty)
with uow: (1)
batches = uow.batches.list() (2)
...
batchref = model.allocate(line, batches)
uow.commit() (3)| 1 | Мы запустим UoW в качестве менеджера контекста. |
| 2 | uow.batches это пакетный репо, поэтому UoW предоставляет нам доступ к нашему постоянному хранилищу.
|
| 3 | Когда мы закончили, мы фиксируем или откатываем нашу работу, используя UoW. |
UoW действует как единственная точка входа в наше постоянное хранилище и отслеживает, какие объекты были загружены, и последнее состояние.[29]
Это дает нам три полезных преимущества:
-
Стабильный моментальный снимок базы данных для работы, поэтому объекты, которые мы используем, не меняются на полпути операции.
-
Способ сохранить все наши изменения сразу, чтобы, если что-то пойдет не так, мы не оказались в непоследовательном состоянии.
-
Простой API для наших проблем персистентности и удобное место для получения репозитория
7.2. Тест-драйв UoW с интеграционными тестами
Here are our integration tests for the UOW:
def test_uow_can_retrieve_a_batch_and_allocate_to_it(session_factory):
session = session_factory()
insert_batch(session, 'batch1', 'HIPSTER-WORKBENCH', 100, None)
session.commit()
uow = unit_of_work.SqlAlchemyUnitOfWork(session_factory) (1)
with uow:
batch = uow.batches.get(reference='batch1') (2)
line = model.OrderLine('o1', 'HIPSTER-WORKBENCH', 10)
batch.allocate(line)
uow.commit() (3)
batchref = get_allocated_batch_ref(session, 'o1', 'HIPSTER-WORKBENCH')
assert batchref == 'batch1'| 1 | Мы инициализируем UoW, используя нашу настраиваемую фабрику сеансов, и возвращаем объект uow для использования его в нашем блоке with. |
| 2 | UoW дает нам доступ к репозиторию batch через uow.batches. |
| 3 | Мы вызываем для него commit(), когда закончим. |
Для любопытных хелперы insert_batch и get_allocated_batch_ref выглядят так:
def insert_batch(session, ref, sku, qty, eta):
session.execute(
'INSERT INTO batches (reference, sku, _purchased_quantity, eta)'
' VALUES (:ref, :sku, :qty, :eta)',
dict(ref=ref, sku=sku, qty=qty, eta=eta)
)
def get_allocated_batch_ref(session, orderid, sku):
[[orderlineid]] = session.execute(
'SELECT id FROM order_lines WHERE orderid=:orderid AND sku=:sku',
dict(orderid=orderid, sku=sku)
)
[[batchref]] = session.execute(
'SELECT b.reference FROM allocations JOIN batches AS b ON batch_id = b.id'
' WHERE orderline_id=:orderlineid',
dict(orderlineid=orderlineid)
)
return batchref7.3. Unit of Work и её менеджер контекста
В наших тестах мы неявно определили интерфейс для того, что должен делать UoW. Давайте сделаем это явным с помощью абстрактного базового класса:
class AbstractUnitOfWork(abc.ABC):
batches: repository.AbstractRepository (1)
def __exit__(self, *args): (2)
self.rollback() (4)
@abc.abstractmethod
def commit(self): (3)
raise NotImplementedError
@abc.abstractmethod
def rollback(self): (4)
raise NotImplementedError| 1 | UoW предоставляет атрибут под названием .batches, который дает нам доступ к репозиторию пакетов. |
| 2 | Если вы никогда не видели контекстного менеджера, __enter__ и __exit__ это два волшебных метода, которые выполняются, когда мы входим в блок with и когда выходим из него, соответственно. Это наши фазы setup и teardown.
|
| 3 | Мы вызовем этот метод, чтобы явно зафиксировать нашу работу, когда будем готовы. |
| 4 | Если мы не фиксируем, или если мы выходим из диспетчера контекста, вызывая ошибку, мы выполняем
«откат» rollback. (Откат не возымеет никакого эффекта, если была вызвана функция commit(). Читайте дальше для более подробного обсуждения этого вопроса.)
|
7.3.1. Реальная Unit of Work Использует Сеансы SQLAlchemy
Главное, что добавляет наша конкретная реализация, - это сеанс базы данных:
DEFAULT_SESSION_FACTORY = sessionmaker(bind=create_engine( (1)
config.get_postgres_uri(),
))
class SqlAlchemyUnitOfWork(AbstractUnitOfWork):
def __init__(self, session_factory=DEFAULT_SESSION_FACTORY):
self.session_factory = session_factory (1)
def __enter__(self):
self.session = self.session_factory() # type: Session (2)
self.batches = repository.SqlAlchemyRepository(self.session) (2)
return super().__enter__()
def __exit__(self, *args):
super().__exit__(*args)
self.session.close() (3)
def commit(self): (4)
self.session.commit()
def rollback(self): (4)
self.session.rollback()| 1 | Модуль определяет фабрику сеансов по умолчанию, которая будет подключаться к Postgres, но мы позволяем переопределить это в наших интеграционных тестах, чтобы вместо этого мы могли использовать SQLite. |
| 2 | Метод __enter__ отвечает за запуск сеанса базы данных и создание экземпляра реального репозитория, который может использовать этот сеанс.
|
| 3 | Закрываем сессию при выходе. |
| 4 | Наконец, мы предоставляем конкретные методы commit() и rollback(), которые используют наш сеанс базы данных.
|
7.3.2. Иммитация Unit of Work для теста
Вот как мы используем фиктивный UoW в наших тестах уровня сервиса:
class FakeUnitOfWork(unit_of_work.AbstractUnitOfWork):
def __init__(self):
self.batches = FakeRepository([]) (1)
self.committed = False (2)
def commit(self):
self.committed = True (2)
def rollback(self):
pass
def test_add_batch():
uow = FakeUnitOfWork() (3)
services.add_batch("b1", "CRUNCHY-ARMCHAIR", 100, None, uow) (3)
assert uow.batches.get("b1") is not None
assert uow.committed
def test_allocate_returns_allocation():
uow = FakeUnitOfWork() (3)
services.add_batch("batch1", "COMPLICATED-LAMP", 100, None, uow) (3)
result = services.allocate("o1", "COMPLICATED-LAMP", 10, uow) (3)
assert result == "batch1"
...| 1 | FakeUnitOfWork и FakeRepository тесно связаны, так же как реальные классы UnitofWork и Repository. Это прекрасно, потому что мы признаем, что объекты являются соавторами. |
| 2 | Обратите внимание на сходство с фальшивой функцией commit() из FakeSession (от которой теперь мы можем избавиться). Но это существенное улучшение, потому что мы сейчас подделываем код, который мы написали, а не сторонний код. Как гласит народная мудрость, "Не твоё — не трогай". |
| 3 | В наших тестах мы можем создать экземпляр UoW и передать его на наш уровень обслуживания, а не передавать репозиторий и сеанс. Это значительно изящнее. |
7.4. Использование UoW в сервисном слое
Вот как выглядит наш новый уровень обслуживания:
def add_batch(
ref: str, sku: str, qty: int, eta: Optional[date],
uow: unit_of_work.AbstractUnitOfWork (1)
):
with uow:
uow.batches.add(model.Batch(ref, sku, qty, eta))
uow.commit()
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork (1)
) -> str:
line = OrderLine(orderid, sku, qty)
with uow:
batches = uow.batches.list()
if not is_valid_sku(line.sku, batches):
raise InvalidSku(f'Invalid sku {line.sku}')
batchref = model.allocate(line, batches)
uow.commit()
return batchref| 1 | Наш уровень обслуживания теперь имеет только одну зависимость, опять же от abstract UoW. |
7.5. Явные тесты для режима Commit/Rollback
Чтобы убедиться, что поведение commit/rollback фиксации/отката работает, мы написали несколько тестов:
def test_rolls_back_uncommitted_work_by_default(session_factory):
uow = unit_of_work.SqlAlchemyUnitOfWork(session_factory)
with uow:
insert_batch(uow.session, 'batch1', 'MEDIUM-PLINTH', 100, None)
new_session = session_factory()
rows = list(new_session.execute('SELECT * FROM "batches"'))
assert rows == []
def test_rolls_back_on_error(session_factory):
class MyException(Exception):
pass
uow = unit_of_work.SqlAlchemyUnitOfWork(session_factory)
with pytest.raises(MyException):
with uow:
insert_batch(uow.session, 'batch1', 'LARGE-FORK', 100, None)
raise MyException()
new_session = session_factory()
rows = list(new_session.execute('SELECT * FROM "batches"'))
assert rows == []| Мы не показывали его здесь, но, возможно, стоит протестировать некоторые из более "неясных" действий базы данных, таких как транзакции, против "реальной" базы данных—то есть того же самого движка. На данный момент нам сходит с рук использование SQLite вместо Postgres, но в Агрегаты и границы консистентности мы переключим некоторые тесты на использование реальной базы данных. Очень удобно, что наш класс UoW делает это легко! |
7.6. Явные и неявные коммиты
Теперь мы вкратце остановимся на различных способах реализации паттерна UoW.
Мы могли бы представить себе несколько иную версию UoW, которая фиксируется по умолчанию и откатывается только в том случае, если замечает исключение:
class AbstractUnitOfWork(abc.ABC):
def __enter__(self):
return self
def __exit__(self, exn_type, exn_value, traceback):
if exn_type is None:
self.commit() (1)
else:
self.rollback() (2)| 1 | Должны ли мы иметь на счастливом пути неявную фиксацию? |
| 2 | И откатиться только при исключении? |
Это позволило бы нам сохранить строку кода и удалить явную фиксацию из нашего клиентского кода:
def add_batch(ref: str, sku: str, qty: int, eta: Optional[date], uow):
with uow:
uow.batches.add(model.Batch(ref, sku, qty, eta))
# uow.commit()Это субъективное мнение, но мы, как правило, предпочитаем требовать явной фиксации, так что нам приходится выбирать, когда сбросить состояние.
Хотя мы используем дополнительную строку кода, это делает программное обеспечение безопасным по умолчанию. Поведение по умолчанию - "ничего не менять". В свою очередь, это делает наш код более простым для рассуждения, потому что есть только один путь кода, который ведет к изменениям в системе: полный успех и явная фиксация. Любой другой путь кода, любое исключение, любой ранний выход из области действия UoW приводит к безопасному состоянию.
Точно так же мы предпочитаем откат по умолчанию, потому что это легче понять; это откат к последней фиксации, поэтому пользователь либо выполнил задание, или мы сдуем их изменения. Сурово, но просто.
7.7. Примеры: Использование UoW для группировки нескольких операций в атомарную единицу
Ниже приведены некоторые примеры используемых схем работы. Это может привести к более простому рассуждению о том, как блоки кода работают совместно.
7.7.1. Пример 1: Перераспределение
Предположим, что мы хотим отменить распределение, а затем передислоцировать заказ:
def reallocate(line: OrderLine, uow: AbstractUnitOfWork) -> str:
with uow:
batch = uow.batches.get(sku=line.sku)
if batch is None:
raise InvalidSku(f'Invalid sku {line.sku}')
batch.deallocate(line) (1)
allocate(line) (2)
uow.commit()| 1 | Если deallocate() не работает, очевидно мы не хотим вызывать allocate(). |
| 2 | Если allocate() терпит неудачу, вероятно мы, так же не хотим фиксить deallocate() |
7.7.2. Пример 2: Изменить размер партии
Наша судоходная компания звонит нам, чтобы сообщить, что одна из дверей контейнера открылась, и половина наших диванов упала в Индийский океан. Ой!
def change_batch_quantity(batchref: str, new_qty: int, uow: AbstractUnitOfWork):
with uow:
batch = uow.batches.get(reference=batchref)
batch.change_purchased_quantity(new_qty)
while batch.available_quantity < 0:
line = batch.deallocate_one() (1)
uow.commit()| 1 | Здесь нам может понадобиться разобраться с любым количеством строк. Если мы получим неудачу на каком-то этапе, мы, вероятно, не захотим вносить никаких изменений. |
7.8. Уборка интеграционных тестов
Теперь у нас есть три набора тестов, все из которых, по сути, направлены на базу данных: test_orm.py, test_repository.py, и test_uow.py. Может, выкинем что-нибудь?
└── tests
├── conftest.py
├── e2e
│ └── test_api.py
├── integration
│ ├── test_orm.py
│ ├── test_repository.py
│ └── test_uow.py
├── pytest.ini
└── unit
├── test_allocate.py
├── test_batches.py
└── test_services.pyВы всегда можете отказаться от тестов, если считаете, что они не принесут пользы в долгосрочной перспективе. Мы бы сказали, что test_orm.py был в первую очередь инструментом для изучения SQLAlchemy, поэтому в дальнейшем он не понадобится, особенно если основные вещи, которые он делает, описаны в test_repository.py. Этот последний тест вы можете оставить, но мы, безусловно, видим аргумент в пользу того, чтобы просто держать все на максимально возможном уровне абстракции (так же, как мы делали это в юнит-тестах).
| Это еще один пример урока из TDD на Высокой и Низкой передаче: по мере того как мы строим лучшие абстракции, мы можем перемещать наши тесты, чтобы работать с ними, что оставляет нам свободу изменять лежащие в их основе детали. |
7.9. Заключение
Надеюсь, мы убедили вас, что шаблон «Единица работы» полезен и что диспетчер контекста - действительно хороший питонический способ визуальной группировки кода в блоки, которые мы хотим реализовать атомарно.
Этот шаблон настолько полезен, что SQLAlchemy уже использует UoW в форме объекта Session. Объект Session в SQLAlchemy - это способ, которым ваше приложение загружает данные из базы данных.
Каждый раз, когда вы загружаете новую сущность из базы данных, сеанс начинает отслеживать изменения в сущности, и когда сеанс сбрасывается, все ваши изменения сохраняются вместе. Зачем нам пытаться абстрагировать сеанс SQLAlchemy, если он уже реализует нужный нам паттерн?
Паттерн Единица Работы: компромиссы обсуждает некоторые компромиссы.
| Плюсы | Минусы |
|---|---|
|
|
Во-первых, Session API богат и поддерживает операции, которые нам не нужны или не нужны в нашем домене. Наш UnitOfWork упрощает сеанс до его основного ядра: его можно запустить, зафиксировать или выбросить.
Во-вторых, мы используем UnitOfWork для доступа к нашим объектам Repository. Это добавит удобства в использовании разработчиками, и это то, то мы не смогли бы сделать с помощью простого SQLAlchemy Session.
Наконец, мы снова мотивированы принципом инверсии зависимостей: наш уровень сервиса зависит от тонкой абстракции, и мы прикрепляем конкретную реализацию к внешнему краю системы. Это хорошо согласуется с собственной рекомендацией SQLAlchemy:
Держите жизненный цикл сеанса (и, как правило, транзакции) отдельным и внешним. Наиболее комплексный подход, рекомендуемый для более существенных приложений, будет стараться держать детали сеанса, транзакции и управления исключениями как можно дальше от деталей программы, выполняющей свою работу.
8. Агрегаты и границы консистентности
В этой главе мы бы хотели вернуться к нашей доменной модели, чтобы поговорить об инвариантах и ограничениях, а также посмотреть, как наши доменные объекты могут поддерживать свою собственную внутреннюю согласованность, как концептуально, так и в постоянном хранении. Мы обсудим концепцию границ консистентности и покажем, как ее постановка может помочь нам построить высокопроизводительное программное обеспечение без ущерба для удобства обслуживания.
Добавление Product aggregate показывает предварительный образ того, куда мы движемся: мы введем новый объект модели под названием Product для упаковки нескольких пакетов batches, и вместо этого сделаем старую доменную службу allocate() доступной в качестве метода в Product.
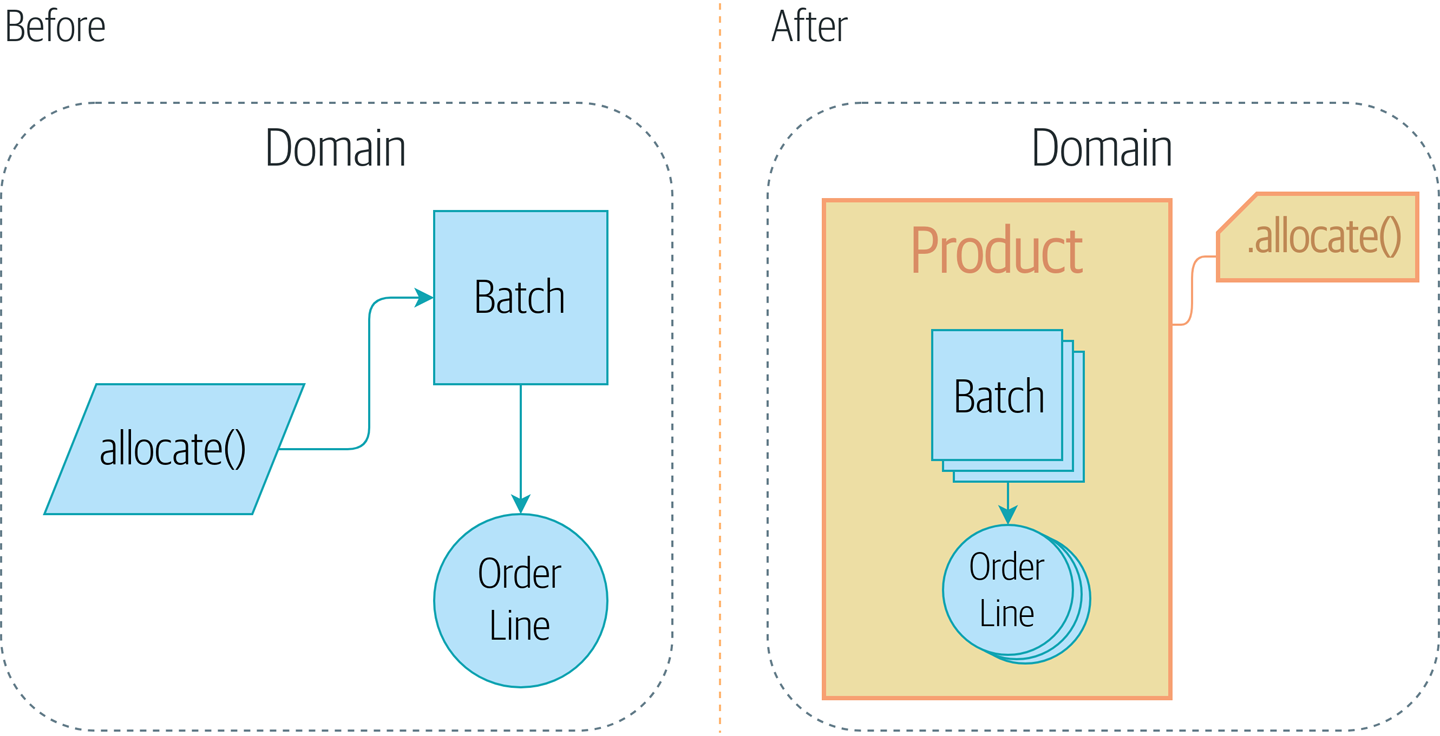
Почему? Давай выясним.
|
Код этой главы находится в ветке chapter_07_aggregate on GitHub: git clone https://github.com/cosmicpython/code.git cd code git checkout chapter_07_aggregate # или, чтобы кодировать вместе, проверьте предыдущую главу: git checkout chapter_06_uow |
8.1. Почему бы просто не запустить все в электронной таблице?
В любом случае, в чем смысл доменной модели? Какую фундаментальную проблему мы пытаемся решить?
Не могли бы мы просто запустить все в электронную таблицу? Многие из наших пользователей были бы в восторге от этого. Бизнес-пользователи любят электронные таблицы, потому что они простые, привычные и в то же время невероятно мощные.
На самом деле, огромное количество бизнес-процессов работают путем ручной отправки электронных таблиц туда и обратно по электронной почте. Эта архитектура «CSV поверх SMTP» имеет низкую начальную сложность, но имеет тенденцию не очень хорошо масштабироваться, потому что трудно применять логику и поддерживать согласованность.
Кому разрешено просматривать это конкретное поле? Кому разрешено обновлять? Что происходит, когда мы пытаемся заказать -350 стульев, или 10 000 000 столов? Может ли работник иметь отрицательную зарплату?
Это ограничения системы. Большая часть логики предметной области, которую мы пишем, существует для обеспечения соблюдения этих ограничений, чтобы поддерживать инварианты системы. Инварианты — это то, что должно быть истинным всякий раз, когда мы заканчиваем операцию.
8.2. Инварианты, Ограничения и Консистентность
Эти два слова в некоторой степени взаимозаменяемы, но constraint Ограничения — это правило, ограничивающее возможные состояния, в которые может попасть наша модель, в то время как invariant определяется немного более точно как условие, которое всегда истинно.
Если бы мы писали систему бронирования отелей, у нас могло бы возникнуть ограничение, что двойное бронирование не допускается. Это подтверждает инвариант, что номер не может быть забронирован более чем на одну ночь.
Конечно, иногда нам может понадобиться временно нарушить правила. Возможно, нам нужно перетасовать номера из-за VIP-бронирования. Пока мы перемещаем заказы в памяти, мы можем быть дважды забронированы, но наша модель предметной области должна гарантировать, что, когда мы закончим, мы окажемся в конечном согласованном состоянии, где инварианты будут выполнены. Если мы не можем найти способ разместить всех наших гостей, мы должны поднять ошибку и отказаться от завершения операции.
Давайте рассмотрим несколько конкретных примеров из наших бизнес-требований; мы начнем с этого:
Строка заказа может быть выделена только для одной партии одновременно.
Это бизнес - правило, которое накладывает инвариант. Инвариант заключается в том, что строка заказа распределяется либо на ноль, либо на одну партию, но никогда не более чем на одну. Нам нужно убедиться, что наш код никогда случайно не вызывает Batch.allocate() в двух разных пакетах для одной и той же строки, и в настоящее время ничто явно не мешает нам это сделать.
8.2.1. Инварианты, Параллельность, и Блокировки locks
Давайте рассмотрим еще одно из наших бизнес-правил:
Мы не можем выделить партию, если доступное количество меньше количества строки заказа.
Ограничением здесь является то, что мы не можем выделить больше запасов, чем имеется в наличии для партии, поэтому мы никогда не перепродаем запасы, например, выделяя двух клиентов на одну и ту же физическую подушку. Каждый раз, когда мы обновляем состояние системы, наш код должен гарантировать, что мы не сломаем инвариант, а именно, что доступное количество должно быть больше или равно нулю.
В однопоточном, однопользовательском приложении нам относительно легко поддерживать этот инвариант. Мы можем просто выделить запас по одной строке за раз и вызвать ошибку, если запаса нет.
Это становится намного сложнее, когда мы вводим идею concurrency. Внезапно мы можем распределять запасы для нескольких строк заказа одновременно. Мы могли бы даже выделять строки заказа одновременно с обработкой изменений в пакетах сами для себя.
Обычно мы решаем эту проблему, применяя блокировку locks к нашим таблицам базы данных. Это предотвращает одновременное выполнение двух операций в одной строке или одной таблице.
Когда мы начинаем думать о масштабировании нашего приложения, мы понимаем, что наша модель распределения строк по всем доступным пакетам может не масштабироваться. Если мы обрабатываем десятки тысяч заказов в час и сотни тысяч строк заказов, мы не можем держать блокировку над всей таблицей batches партии для каждого из них — мы получим тупики или проблемы с производительностью, по крайней мере.
8.3. Что такое Агрегат?
Итак, если мы не можем блокировать всю базу данных каждый раз, когда хотим выделить строку заказа, что мы должны делать вместо этого? Мы хотим защитить инварианты нашей системы, но при этом обеспечить максимальную степень параллелизма. Сохранение наших инвариантов неизбежно означает предотвращение одновременной записи; если несколько пользователей могут выделить "DEADLY-SPOON" одновременно, мы рискуем перераспределить ее.
С другой стороны, нет причин, по которым мы не можем выделить DEADLY-SPOON одновременно с FLIMSY-DESK. Безопасно выделять два продукта одновременно, потому что нет инварианта, покрывающего оба. Нам не нужно, чтобы они были консистентны друг другу.
Шаблон Aggregate является шаблоном дизайна от сообщества DDD, который помогает нам решить эту проблему. aggregate - это просто объект домена, который содержит другие объекты домена и позволяет нам рассматривать всю коллекцию как единое целое.
Единственный способ модифицировать объекты внутри агрегата - это загрузить его целиком, а также вызвать методы внутри самомого агрегата.
По мере усложнения модели и увеличения числа объектов сущностей и значений, ссылающихся друг на друга в запутанном графе, становится трудно отслеживать, кто и что может изменять. Особенно когда у нас есть collections в модели, как у нас это принято (наши пакеты-это коллекция), это хорошая идея назначить некоторые сущности в качестве единственной точки входа для изменения связанных с ними объектов. Это делает систему концептуально проще и легче обоснуемой, если вы назначаете некоторые объекты ответственными за консистентность над другими.
Например, если мы создаем Интернет-магазин, Корзина может стать хорошим Агрегатом: это коллекция предметов, которые мы можем рассматривать как единое целое. Важно отметить, что мы хотим загрузить всю корзину как одну большую каплю из нашего хранилища данных. Мы не хотим, чтобы два запроса изменяли корзину одновременно, иначе мы рискуем получить странные ошибки параллелизма. Вместо этого мы хотим, чтобы каждое изменение корзины выполнялось в одной транзакции базы данных.
Мы не хотим изменять несколько корзин в транзакции, потому что нет смысла менять корзины нескольких клиентов одновременно. Каждая корзина представляет собой единственную границу соответствия, отвечающую за поддержание своих собственных инвариантов.
АГРЕГАТ - это кластер связанных объектов, который мы рассматриваем как единое целое с целью изменения данных.
Domain-Driven Design blue book
Согласно Эвансу, наш агрегат имеет корневую сущность (корзину), которая инкапсулирует доступ к элементам. Каждый товар имеет свою индивидуальность, но другие части системы всегда будут относиться к Корзине только как к неделимому целому.
Точно так же, как мы иногда используем _leading_underscores для обозначения методов или функций как "частных", вы можете думать о агрегатах как о "публичных" классах нашей модели, а об остальных сущностях и объектах значений как о "частных"."
|
8.4. Выбор агрегата
Какой агрегат мы должны использовать для нашей системы? Выбор несколько произвольный, но он важен. Агрегат будет границей, где мы будем следить за тем, чтобы каждая операция заканчивалась в последовательном состоянии. Это помогает нам рассуждать о нашем программном обеспечении и предотвращать тайные расовые проблемы. Мы хотим нарисовать границу вокруг небольшого количества объектов - чем меньше, тем лучше, для производительности - которые должны быть совместимы друг с другом, и мы должны дать этой границе хорошее имя.
Объект, которым мы манипулируем под капотом, - это Batch.. Что мы называем коллекцией партий? Как нам разделить все партии в системе на дискретные острова консистентности?
Мы можем использовать Shipment отгрузку в качестве границы. Каждая отгрузка содержит несколько партий, и все они отправляются на наш склад одновременно. Или, возможно, мы могли бы использовать Warehouse "Склад" в качестве нашей границы: каждый склад содержит много партий, и подсчет всех запасов одновременно может иметь смысл.
Но ни одна из этих концепций нас не удовлетворяет. Мы должны быть в состоянии выделить DEADLLY-SPOONs и FLIMSY-DESK одновременно, даже если они находятся на одном и том же складе или в одной и той же отгрузке. Эти понятия имеют неправильную гранулярность.
Когда мы выделяем линию заказа, нас интересуют только те партии, которые имеют тот же SKU, что и линия заказа. Может сработать какая-нибудь концепция вроде GlobalSkuStock: сбор всех партий для данного SKU.
Однако, это громоздкое имя, поэтому после некоторого пролива велосипедов через SkuStock, Stock, ProductStock и так далее, мы решили просто назвать его Product — в конце концов, это была первая концепция, с которой мы столкнулись при изучении языка домена еще в Domain Modeling.
Итак, план таков: когда мы хотим выделить строку заказа вместо Раньше: распределение по всем пакетам, использующим доменную службу, где мы ищем все объекты Batch в мире и передаем их службе домена allocate().. .
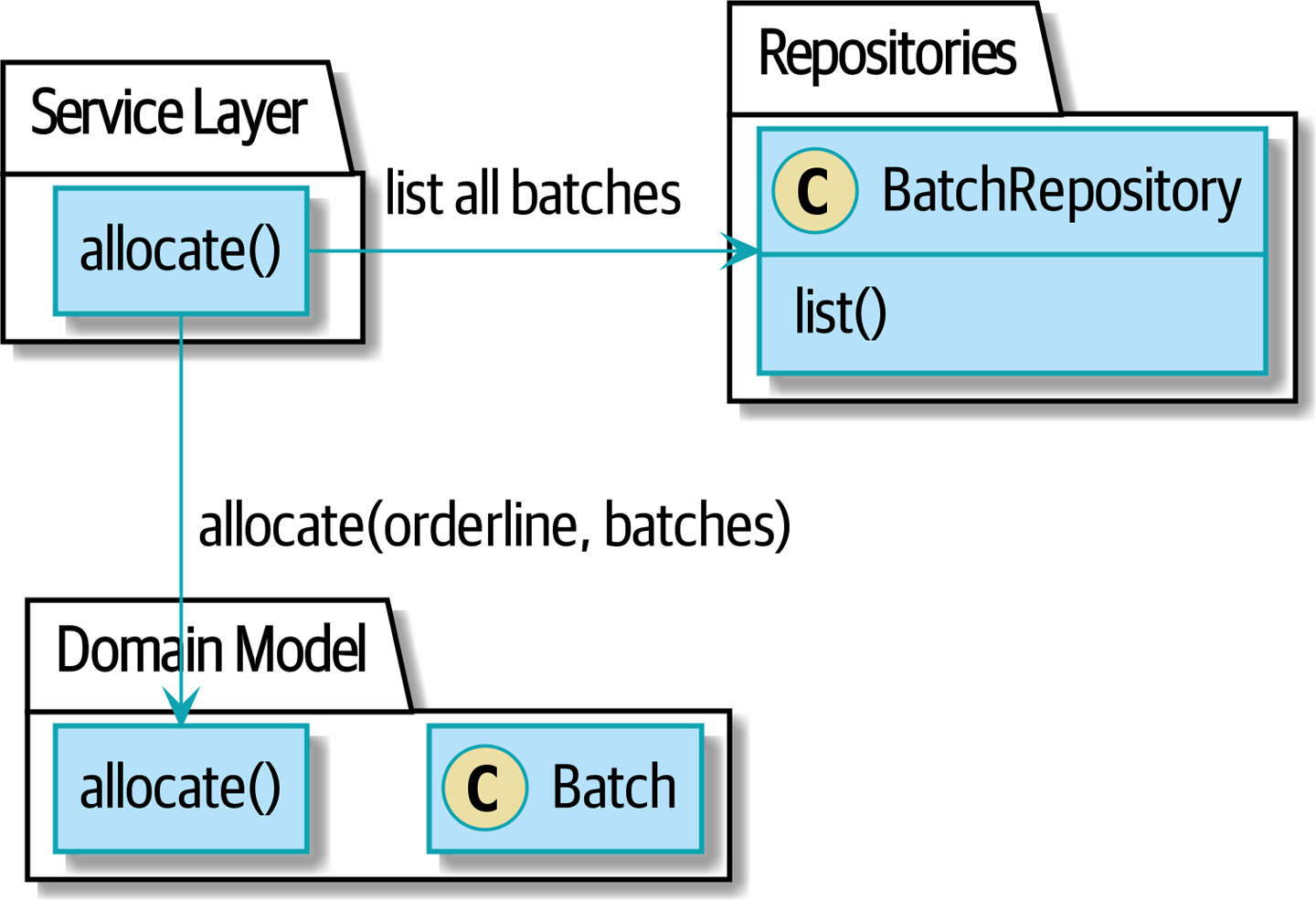
[plantuml, apwp_0702, config=plantuml.cfg]
@startuml
scale 4
hide empty members
package "Service Layer" as services {
class "allocate()" as allocate {
}
hide allocate circle
hide allocate members
}
package "Domain Model" as domain_model {
class Batch {
}
class "allocate()" as allocate_domain_service {
}
hide allocate_domain_service circle
hide allocate_domain_service members
}
package Repositories {
class BatchRepository {
list()
}
}
allocate -> BatchRepository: list all batches
allocate --> allocate_domain_service: allocate(orderline, batches)
@enduml
… мы переместимся в мир После: просим Product распределить продукт по его партиям, в котором есть новый объект Product для конкретного SKU нашей строки заказа который теперь будет отвечать за все партии для этого SKU, и вместо этого мы можем вызвать метод .allocate().
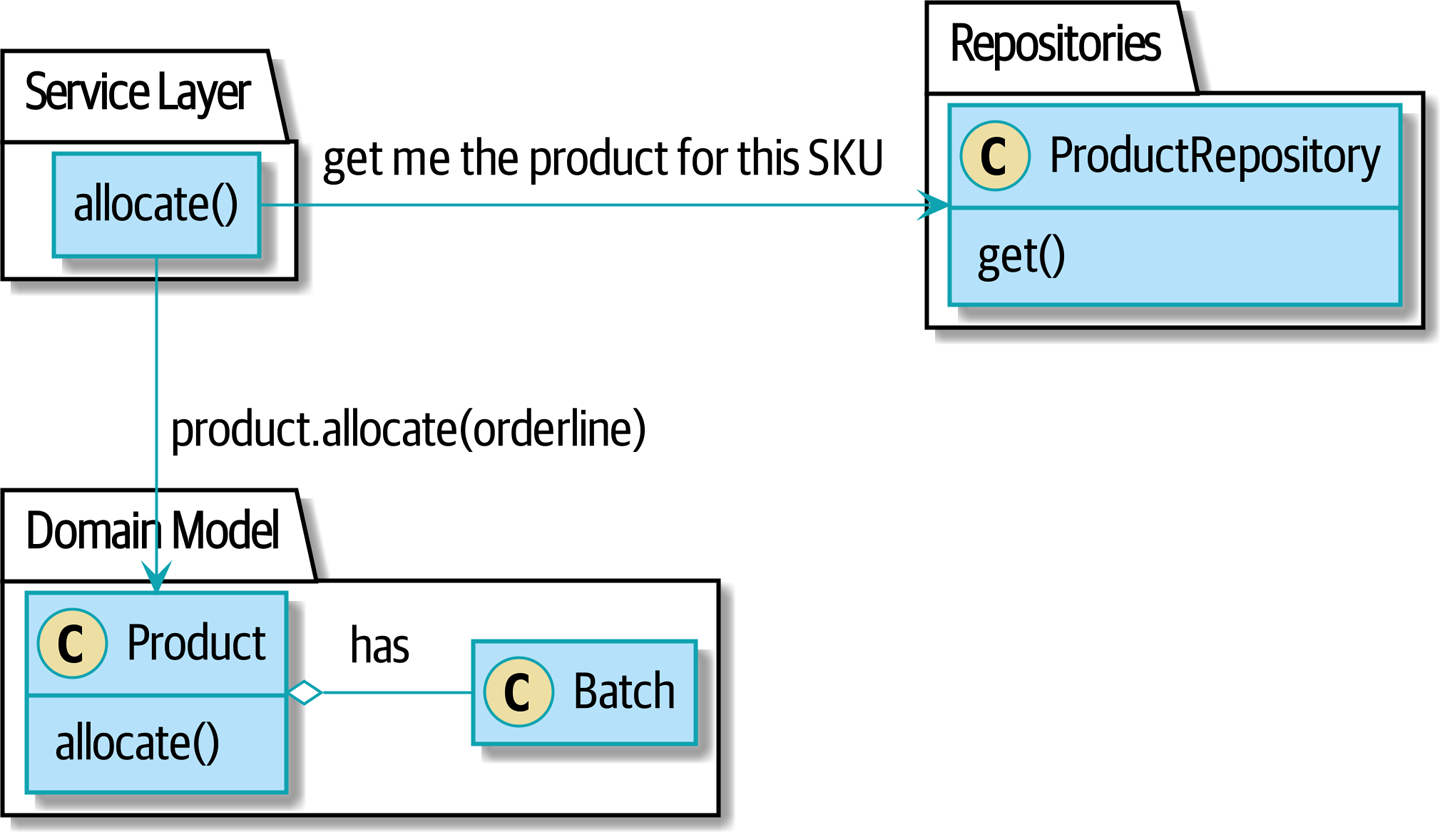
[plantuml, apwp_0703, config=plantuml.cfg]
@startuml
scale 4
hide empty members
package "Service Layer" as services {
class "allocate()" as allocate {
}
}
hide allocate circle
hide allocate members
package "Domain Model" as domain_model {
class Product {
allocate()
}
class Batch {
}
}
package Repositories {
class ProductRepository {
get()
}
}
allocate -> ProductRepository: get me the product for this SKU
allocate --> Product: product.allocate(orderline)
Product o- Batch: has
@enduml
Посмотрим, как это выглядит в виде кода:
class Product:
def __init__(self, sku: str, batches: List[Batch]):
self.sku = sku (1)
self.batches = batches (2)
def allocate(self, line: OrderLine) -> str: (3)
try:
batch = next(
b for b in sorted(self.batches) if b.can_allocate(line)
)
batch.allocate(line)
return batch.reference
except StopIteration:
raise OutOfStock(f'Out of stock for sku {line.sku}')| 1 | Основной идентификатор Product - это sku. |
| 2 | Наш класс Product содержит ссылку на коллекцию batches для этого SKU.
|
| 3 | Наконец, мы можем переместить доменную службу allocate() в метод агрегата 'Product`. |
Этот Product может выглядеть не так, как вы ожидаете от модели Product. Ни цены, ни описания, ни габаритов. Нашу службу размещения не волнует ни одна из этих вещей. В этом сила ограниченных контекстов; концепция продукта в одном приложении может сильно отличаться от другого. См. Дополнительную информацию на следующей боковой панели.
|
8.5. Один Агрегат = Один Репозиторий
Как только вы определяете определенные сущности как агрегаты, мы должны применить правило, что они являются единственными сущностями, которые являются общедоступными для внешнего мира. Другими словами, единственными репозиториями, которые нам разрешены, должны быть репозитории, возвращающие агрегаты.
| Правило, согласно которому хранилища должны возвращать только агрегаты, является основным местом, где мы обеспечиваем соблюдение соглашения о том, что агрегаты - это единственный путь в нашу модель домена. Берегитесь сломать его! |
В нашем случае мы переключимся с BatchRepository на ProductRepository:
class AbstractUnitOfWork(abc.ABC):
products: repository.AbstractProductRepository
...
class AbstractProductRepository(abc.ABC):
@abc.abstractmethod
def add(self, product):
...
@abc.abstractmethod
def get(self, sku) -> model.Product:
...
Уровень ORM потребует некоторых доработок, чтобы нужные партии автоматически загружались и ассоциировались с объектами Product. Хорошо то, что паттерн Repository позволяет нам пока не беспокоиться об этом. Мы можем просто использовать наш FakeRepository и затем передать новую модель в наш сервисный слой, чтобы посмотреть, как она выглядит с Product в качестве основной точки входа:
def add_batch(
ref: str, sku: str, qty: int, eta: Optional[date],
uow: unit_of_work.AbstractUnitOfWork
):
with uow:
product = uow.products.get(sku=sku)
if product is None:
product = model.Product(sku, batches=[])
uow.products.add(product)
product.batches.append(model.Batch(ref, sku, qty, eta))
uow.commit()
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork
) -> str:
line = OrderLine(orderid, sku, qty)
with uow:
product = uow.products.get(sku=line.sku)
if product is None:
raise InvalidSku(f'Invalid sku {line.sku}')
batchref = product.allocate(line)
uow.commit()
return batchref8.6. Что насчет производительности?
Мы уже несколько раз упоминали, что моделируем используя агрегаты, потому что хотим иметь высокопроизводительное программное обеспечение, но здесь мы загружаем все партии, когда нам нужна только одна. Можно было бы ожидать, что это неэффективно, но есть несколько причин, по которым это здесь приемлимо.
Во-первых, мы специально моделируем наши данные так, чтобы мы могли сделать один запрос к базе данных для чтения и одно обновление для сохранения наших изменений. Это, как правило, работает гораздо лучше, чем системы, которые выдают много специальных запросов. В системах, которые не моделированы таким образом, мы часто обнаруживаем, что транзакции постепенно становятся длиннее и сложнее по мере развития программного обеспечения.
Во-вторых, наши структуры данных минимальны и состоят из нескольких строк и целых чисел на строку. Мы можем легко загружать десятки или даже сотни партий за несколько миллисекунд.
В-третьих, мы ожидаем, что одновременно будет производиться только 20 или около того партий каждого продукта. Как только партия израсходована, мы можем исключить ее из наших расчетов. Это означает, что количество данных, которые мы получаем, не должно выходить из-под контроля с течением времени.
Если бы мы ожидали, что у нас будут тысячи активных партий продукта, у нас было бы несколько вариантов. Например, мы можем использовать ленивую загрузку для партий в продукте. С точки зрения нашего кода ничего не изменится, но в фоновом режиме SQLAlchemy будет просматривать данные для нас. Это привело бы к большему количеству запросов, каждый из которых получал бы меньшее количество строк. Поскольку нам нужно найти только одну партию с достаточной емкостью для нашего заказа, это может сработать.
Если бы все остальное не помогло, мы бы просто поискали другой агрегат. Возможно, мы могли бы разделить партии по регионам или по складам. Возможно, мы могли бы перестроить нашу стратегию доступа к данным на основе концепции отгрузки. Шаблон Aggregate разработан для того, чтобы помочь справиться с некоторыми техническими ограничениями, связанными с согласованностью и производительностью. Не существует одного правильного агрегата, и мы должны чувствовать себя комфортно, меняя свои взгляды, если обнаружим, что наши границы вызывают проблемы с производительностью.
8.7. Оптимистический параллелизм с номерами версий
У нас есть наш новый агрегат, и мы решили концептуальную проблему выбора объекта, который будет отвечать за границы консистенции. Давайте теперь потратим немного времени на обсуждение того, как обеспечить целостность данных на уровне базы данных.
| В этом разделе много деталей реализации; например, некоторые из них специфичны для Postgres. Но в более общем смысле мы показываем один из способов управления проблемами параллелизма, но это всего лишь один из подходов. Реальные требования в этой области сильно варьируются от проекта к проекту. Не стоит ожидать, что вы сможете скопировать и вставить код отсюда в производство. |
Мы не хотим держать блокировку на всей таблице batches, но как мы реализуем блокировку только строк для определенного SKU?
Один из ответов - иметь единственный атрибут в модели Product, который действует как маркер завершения всего изменения состояния, и использовать его как единственный ресурс, за который могут бороться параллельные воркеры. Если две транзакции одновременно читают состояние мира для batches и обе хотят обновить таблицы allocations, мы заставим обе транзакции также попытаться обновить version_number в таблице products, таким образом, чтобы только одна из них могла выиграть, а мир бы остался целостным.
Последовательная диаграмма: две транзакции пытаются выполнить одновременное обновление на Product иллюстрирует две параллельные транзакции, выполняющие операции чтения одновременно, так что они видят Product, например, с version=3. Они оба вызывают Product.allocate() для того, чтобы изменить состояние. Но мы установили правила целостности базы данных таким образом, что только одному из них разрешено commit-ить новый Product с version=4, а другое обновление будет отклонено.
Номера версий - это лишь один из способов реализации оптимистической блокировки. Вы можете добиться того же, установив уровень изоляции транзакций Postgres на SERIALIZABLE, но это часто оборачивается серьезными издержками производительности. Номера версий также делают неявные понятия явными.
|
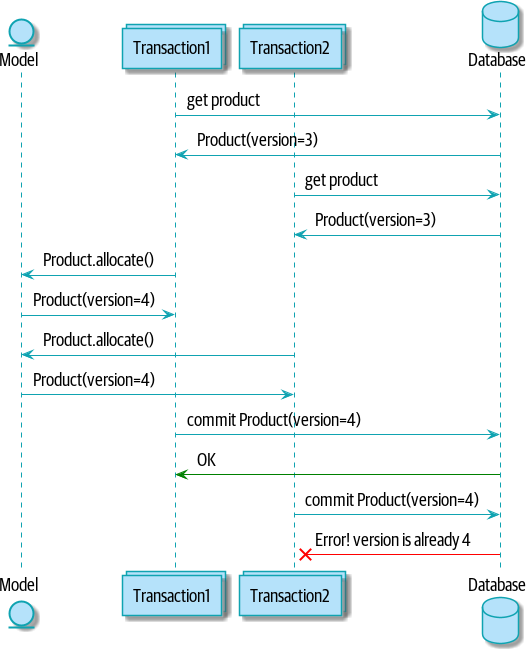
Product[plantuml, apwp_0704, config=plantuml.cfg] @startuml scale 4 entity Model collections Transaction1 collections Transaction2 database Database Transaction1 -> Database: get product Database -> Transaction1: Product(version=3) Transaction2 -> Database: get product Database -> Transaction2: Product(version=3) Transaction1 -> Model: Product.allocate() Model -> Transaction1: Product(version=4) Transaction2 -> Model: Product.allocate() Model -> Transaction2: Product(version=4) Transaction1 -> Database: commit Product(version=4) Database -[#green]> Transaction1: OK Transaction2 -> Database: commit Product(version=4) Database -[#red]>x Transaction2: Error! version is already 4 @enduml
8.7.1. Варианты реализации для номеров версий
Существует три варианта реализации номеров версий:
-
version_numberживет в домене; мы добавляем его в конструкторProduct, аProduct.allocate()отвечает за его увеличение. -
Это может сделать сервисный уровень! Номер версии не является строго вопросом домена, поэтому вместо этого наш сервисный уровень может считать, что текущий номер версии прикреплен к
Productхранилищем, и сервисный уровень увеличит его перед выполнениемcommit(). -
Поскольку это, вероятно, инфраструктурная проблема, UoW и репозиторий могли бы сделать это по волшебству. Хранилище имеет доступ к номерам версий для любых продуктов, которые оно извлекает, и когда UoW выполняет фиксацию, оно может увеличить номер версии для всех продуктов, о которых оно знает, предполагая, что они изменились.
Вариант 3 не идеален, потому что нет реального способа сделать это, не предполагая, что все продукты изменились, поэтому мы будем увеличивать номера версий, когда это не нужно.сноска:[Возможно, мы могли бы использовать какую-то магию ORM/SQLAlchemy, чтобы сообщить нам, когда объект грязный, но как это будет работать в общем случае - например, для CsvRepository?].
Вариант 2 подразумевает смешение ответственности за изменение состояния между сервисным уровнем и уровнем домена, поэтому он также слегка чумазый.
Так что, в конце концов, даже если номера версий не обязательно должны относиться к домену, вы можете решить, что наиболее чистым компромиссом будет поместить их в домен:
class Product:
def __init__(self, sku: str, batches: List[Batch], version_number: int = 0): (1)
self.sku = sku
self.batches = batches
self.version_number = version_number (1)
def allocate(self, line: OrderLine) -> str:
try:
batch = next(
b for b in sorted(self.batches) if b.can_allocate(line)
)
batch.allocate(line)
self.version_number += 1 (1)
return batch.reference
except StopIteration:
raise OutOfStock(f'Нет в наличии для sku {line.sku}')| 1 | Вот оно! |
Если вы ломаете голову над вопросом о номере версии, возможно, стоит вспомнить, что номер не важен. Важно то, что строка базы данных Product изменяется всякий раз, когда мы вносим изменения в агрегат Product. Номер версии - это простой, понятный человеку способ моделирования всякой разной хрени, которая изменяется при каждой записи, но он также может быть случайным UUID каждый раз.
|
8.8. Тестирование на соответствие нашим правилам целостности данных
Теперь убедимся, что мы можем получить желаемое поведение: если у нас есть две одновременные попытки выполнить распределение для одного и того же Product, одна из них должна потерпеть неудачу, потому что они не могут оба обновить номер версии.
Во-первых, давайте смоделируем "медленную" транзакцию с использованием функции, которая выполняет распределение, а затем впадает в спячку:[30]
def try_to_allocate(orderid, sku, exceptions):
line = model.OrderLine(orderid, sku, 10)
try:
with unit_of_work.SqlAlchemyUnitOfWork() as uow:
product = uow.products.get(sku=sku)
product.allocate(line)
time.sleep(0.2)
uow.commit()
except Exception as e:
print(traceback.format_exc())
exceptions.append(e)Затем мы заставляем наш тест вызывать это медленное распределение дважды, одновременно, используя потоки:
def test_concurrent_updates_to_version_are_not_allowed(postgres_session_factory):
sku, batch = random_sku(), random_batchref()
session = postgres_session_factory()
insert_batch(session, batch, sku, 100, eta=None, product_version=1)
session.commit()
order1, order2 = random_orderid(1), random_orderid(2)
exceptions = [] # type: List[Exception]
try_to_allocate_order1 = lambda: try_to_allocate(order1, sku, exceptions)
try_to_allocate_order2 = lambda: try_to_allocate(order2, sku, exceptions)
thread1 = threading.Thread(target=try_to_allocate_order1) (1)
thread2 = threading.Thread(target=try_to_allocate_order2) (1)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
[[version]] = session.execute(
"SELECT version_number FROM products WHERE sku=:sku",
dict(sku=sku),
)
assert version == 2 (2)
[exception] = exceptions
assert 'could not serialize access due to concurrent update' in str(exception) (3)
orders = list(session.execute(
"SELECT orderid FROM allocations"
" JOIN batches ON allocations.batch_id = batches.id"
" JOIN order_lines ON allocations.orderline_id = order_lines.id"
" WHERE order_lines.sku=:sku",
dict(sku=sku),
))
assert len(orders) == 1 (4)
with unit_of_work.SqlAlchemyUnitOfWork() as uow:
uow.session.execute('select 1')| 1 | Мы запускаем два потока, которые надежно обеспечат нужное нам поведение параллелизма: read1, read2, write1, write2. |
| 2 | Мы утверждаем, что номер версии был увеличен только один раз. |
| 3 | При желании мы можем проверить конкретное исключение. |
| 4 | И мы дважды проверяем, что прошло только одно распределение. |
8.8.1. Обеспечение правил параллелизма с помощью транзакций базы данных Isolation Levels
Чтобы тест прошел как есть, мы можем установить уровень изоляции транзакции для нашей сессии:
DEFAULT_SESSION_FACTORY = sessionmaker(bind=create_engine(
config.get_postgres_uri(),
isolation_level="REPEATABLE READ",
))| Уровни изоляции транзакций - сложная штука, поэтому стоит потратить время на понимание https://oreil.ly/5vxJA [документация Postgres].[31] |
8.8.2. Пример пессимистического управления параллелизмом: SELECT FOR UPDATE
К этому можно подойти разными способами, но мы покажем один из них. SELECT FOR UPDATE приводит к другому поведению; двум параллельным транзакциям не будет разрешено выполнять чтение одних и тех же строк в одно и то же время:
SELECT FOR UPDATE это способ выбора строки или строк для использования в качестве блокировки (хотя эти строки не обязательно должны быть теми, которые вы обновляете). Если две транзакции одновременно попытаются SELECT FOR UPDATE-ть строки, одна из них выиграет, а другая будет ждать, пока блокировка не будет освобождена. Таким образом, это пример пессимистического управления параллелизмом.
Вот как можно использовать SQLAlchemy DSL для указания FOR UPDATE во время запроса:
def get(self, sku):
return self.session.query(model.Product) \
.filter_by(sku=sku) \
.with_for_update() \
.first()Это приведет к изменению шаблона параллелизма с
read1, read2, write1, write2(fail)
to
read1, write1, read2, write2(succeed)
Можно встретить термин, который определяет это режимом сбоя "read-modify-write". Прочитай "PostgreSQL Anti-Patterns: Read-Modify-Write Cycles" для хорошего, но быстрого ознакомления.
У нас действительно нет времени обсуждать все компромиссы между "ПОВТОРЯЕМЫМ ЧТЕНИЕМ" и "ВЫБОРОМ ДЛЯ ОБНОВЛЕНИЯ" или оптимистичной и пессимистичной блокировкой в целом. Но если у вас есть тест, подобный тому, который мы показали, вы можете указать желаемое поведение и посмотреть, как оно изменится. Вы также можете использовать тест в качестве основы для проведения некоторых экспериментов по производительности.
8.9. Подведение итогов
Конкретные варианты управления параллелизмом сильно различаются в зависимости от бизнес-обстоятельств и выбора технологии хранения, но мы хотели бы вернуться в этой главе к концептуальной идее агрегата: мы явно моделируем объект как основную точку входа в некоторое подмножество нашей модели и как ответственную за соблюдение инвариантов и бизнес-правил, применимых ко всем этим объектам.
Выбор правильного агрегата является ключевым, и это решение вы можете пересмотреть со временем. Вы можете прочитать больше об этом в нескольких книгах DDD. Мы также рекомендуем эти три онлайн-статьи по эффективной конструкции агрегата автор: Vaughn Vernon (автор "красной книги" ).
Aggregates: компромиссы есть некоторые мысли о компромиссах реализации агрегированного шаблона.
| Плюсы | Минусы |
|---|---|
|
|
8.10. Part I Recap
Помните Диаграмма компонентов для нашего приложения в конце части I, диаграмму, которую мы показывали в начале [части 1], чтобы просмотреть, куда мы направляемся?
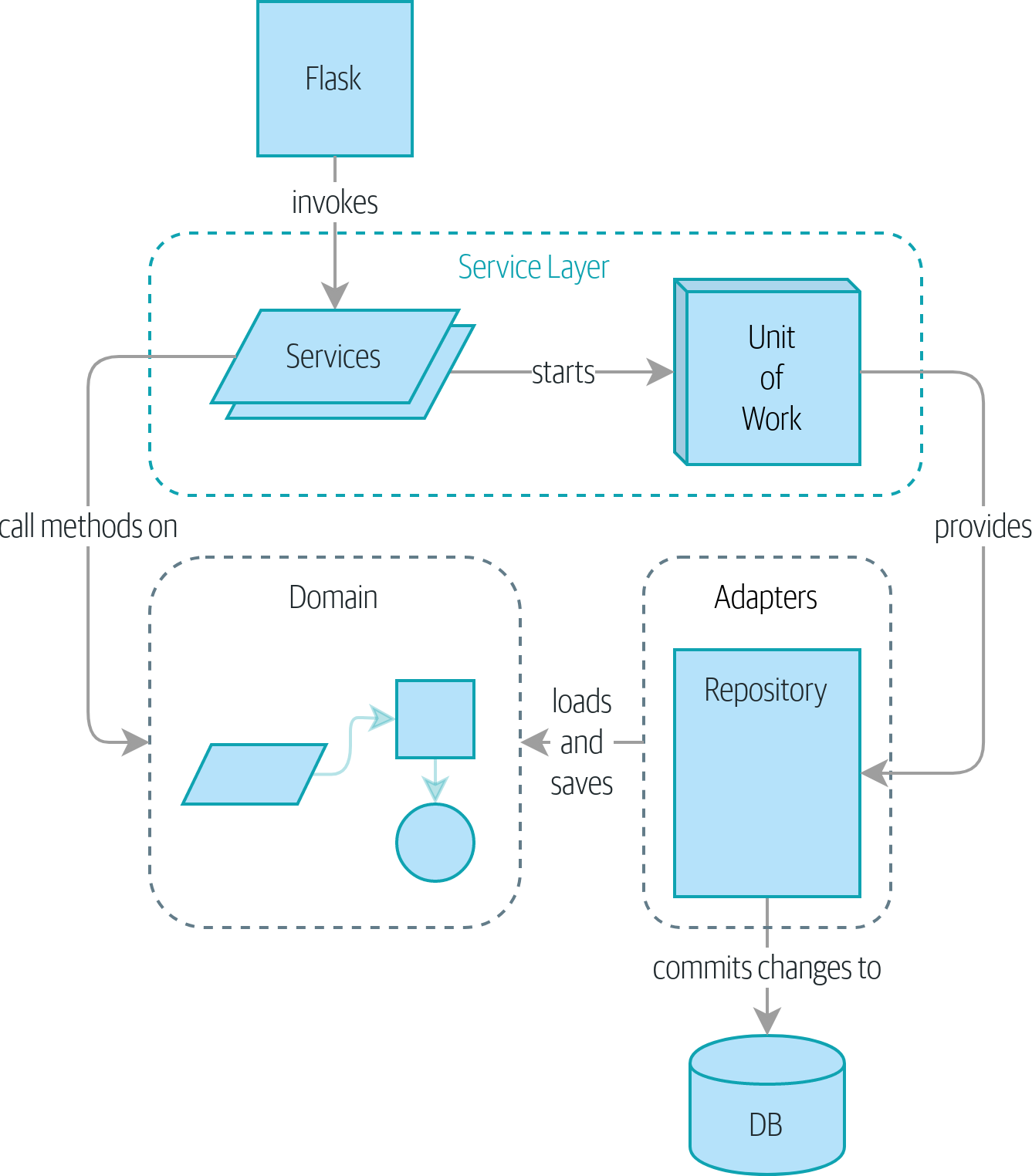
Это конец первой части. Чего мы добились? Мы уже знаем, как построить модель поля, которая будет проверена группой старших модулей. Наши тесты - живые документы: они описывают поведение системы с помощью читаемого кода - правила, которые мы согласовали с деловыми кругами. Когда наши бизнес - потребности меняются, мы уверены, что наши тесты помогут нам доказать новые возможности, и когда новые разработчики присоединятся к проекту, они смогут прочитать наши тесты, чтобы понять, как все работает.
Мы отделили инфраструктурные части нашей системы, такие как база данных и обработчики API, чтобы мы могли подключить их к внешней части нашего приложения. Это помогает нам хорошо организовать нашу кодовую базу и не дает нам создать большой ком грязи.
Применяя принцип инверсии зависимостей и используя шаблоны, вдохновленные портами и адаптерами, такие как репозиторий и единица работы, мы сделали возможным выполнять TDD как на высокой, так и на низкой передаче и поддерживать здоровую тестовую пирамиду. Мы можем тестировать нашу систему от края до края, и потребность в интеграции и сквозных тестах сведена к минимуму.
Наконец, мы говорили об идее границ согласованности. Мы не хотим блокировать всю нашу систему всякий раз, когда вносим изменения, поэтому мы должны выбирать, какие части согласуются друг с другом.
Для небольшой системы это все, что вам нужно, чтобы пойти и поиграть с идеями доменного дизайна. Теперь у вас есть инструменты для создания моделей домена, не зависящих от базы данных, которые представляют общий язык ваших бизнес-экспертов. Ура!
| Рискуя затронуть эту тему, мы изо всех сил старались указать на то, что каждый паттерн имеет свою цену. Каждый уровень косвенности имеет свою цену с точки зрения сложности и дублирования в нашем коде и будет сбивать с толку программистов, которые никогда раньше не видели этих шаблонов. Если ваше приложение по сути является простой оболочкой CRUD вокруг базы данных и вряд ли будет чем-то большим в обозримом будущем, вам не нужны эти шаблоны. Двигайтесь дальше и используйте Django, и избавьте себя от многих хлопот. |
В части II мы уменьшим масштаб и поговорим о более широкой теме: если агрегаты являются нашей границей, и мы можем обновлять только по одному за раз, как мы моделируем процессы, которые пересекают границы согласованности?
Событийно-Ориентированная архитектура
Мне жаль, что я давным-давно придумал термин "объекты" для этой темы, потому что он заставляет многих людей сосредоточиться на менее значимой идее.
Главная идея-это "messaging обмен сообщениями"….Ключ к созданию больших и растущих систем гораздо больше заключается в том, чтобы спроектировать, как его модули взаимодействуют, а не в том, какими должны быть их внутренние свойства и поведение.
Все это очень хорошо, когда мы можем написать одну доменную модель для управления одним участком бизнес-процесса, но что происходит, когда нам нужно написать несколько моделей? В реальном мире наши приложения находятся внутри организации и должны обмениваться информацией с другими частями системы. Возможно, вы помните нашу контекстную диаграмму, показанную в Но как именно все эти системы будут общаться друг с другом?.
Столкнувшись с этим требованием, многие команды обращаются к микросервисам, интегрированным через HTTP API. Но если они не будут осторожны, то в конечном итоге создадут самый хаотичный беспорядок из всех: распределенный БОЛЬШОЙ ШАР ГРЯЗИ.
В части II мы покажем, как методы из [части 1] могут быть распространены на распределенные системы. Мы уменьшим масштаб, чтобы посмотреть, как мы можем составить систему из множества небольших компонентов, которые взаимодействуют посредством асинхронной передачи сообщений.
Мы увидим, как наш Уровень обслуживания и шаблоны единиц работы позволяют нам перенастроить наше приложение для работы в качестве асинхронного процессора сообщений и как системы, управляемые событиями, помогают нам отделить агрегаты и приложения друг от друга.
Мы рассмотрим следующие шаблоны и техники:
- События домена
-
Триггерные рабочие процессы, которые пересекают границы консистенции.
- Шина сообщений
-
Обеспечивает унифицированный способ вызова случаев использования из любой конечной точки.
- CQRS
-
Разделяет операций чтения и записи позволяет избежать неудобных компромиссов в событийно-управляемой архитектуре и повысить производительность и масштабируемость.
Плюс, мы добавим каркас для инъекций зависимостей. Это не имеет ничего общего с архитектурой, основанной на событиях как таковой, но она убирает очень много свободных концовок.
9. События и шина сообщений
Итак, мы потратили кучу времени и энергии на простую проблему, которую мы могли бы легко решить с помощью Django. Возможно, вы задаётесь вопросом, действительно ли повышенная тестируемость и выразительность стоят всех усилий?!
Однако на практике мы обнаруживаем, что не очевидные функции создают беспорядок в наших кодовых базах: это нечто липкое и тупое скопившееся по краю. Это отчеты, разрешения и рабочие процессы, которые затрагивают миллион объектов.
Нашим примером будет типичное требование к уведомлению: когда мы не можем разместить заказ, потому что его нет в наличии, мы должны предупредить отдел сбыта. Они пойдут и решат проблему, закупив побольше запасов, и все будет хорошо.
В случае первой версии, наш владелец только должен отправить предупреждение по электронной почте.
Давайте посмотрим, как выдержит наша архитектура, когда нам нужно подключить некоторые прозаичные вещи, которые составляют так много наших систем.
Мы начнём с самого простого, самого быстрого решения и дальше поговорим о том, почему именно такое решение приводит нас к Большому Комку грязи.
Затем мы покажем, как использовать шаблон Domain Events для отделения побочных эффектов от наших вариантов использования, и как использовать простой шаблон Message Bus для запуска поведения на основе этих событий. Мы покажем несколько вариантов для создания этих событий и того, как передать их в шину сообщений, и, наконец, мы покажем, как можно изменить шаблон Unit of Work, чтобы элегантно соединить их вместе, как показано в <<message_bus_diagram> >.
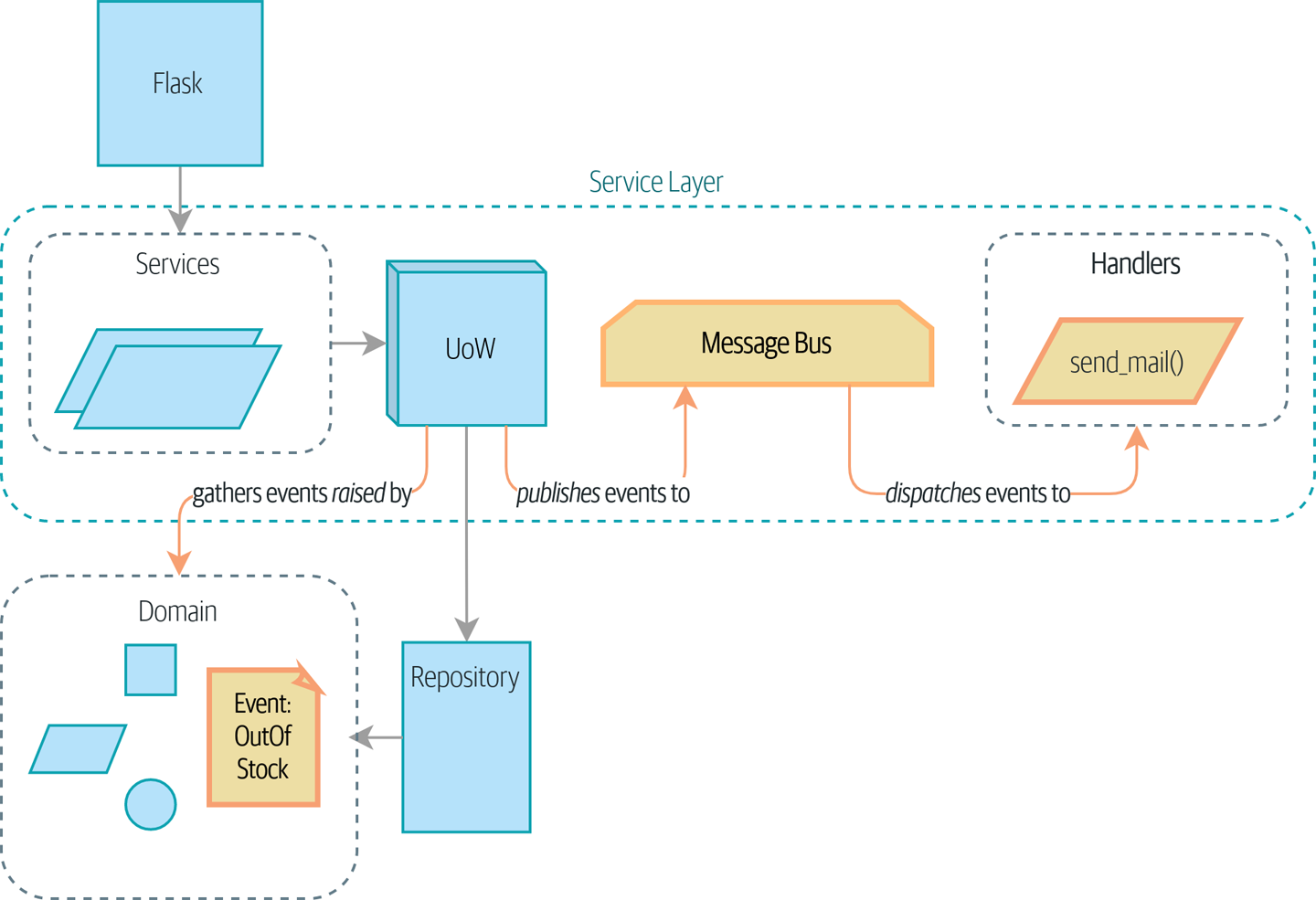
|
Код этой главы находится в ветке chapter_08_events_and_message_bus на GitHub: git clone https://github.com/cosmicpython/code.git cd code git checkout chapter_08_events_and_message_bus # или, чтобы дальше кодировать вместе, проверьте предыдущую главу: git checkout chapter_07_aggregate |
9.1. Как избежать беспорядка
Так. Уведомления по электронной почте, когда у нас заканчивается товар. Когда у нас появляются новые требования, вроде тех, которые в действительности не имеют ничего общего с основным доменом, очень легко начать сбрасывать эти вещи в наши веб-контроллеры.
9.1.1. Во-первых, давайте не будем путать наши веб-контроллеры
В качестве одноразового взлома, это может быть допустимо:
@app.route("/allocate", methods=['POST'])
def allocate_endpoint():
line = model.OrderLine(
request.json['orderid'],
request.json['sku'],
request.json['qty'],
)
try:
uow = unit_of_work.SqlAlchemyUnitOfWork()
batchref = services.allocate(line, uow)
except (model.OutOfStock, services.InvalidSku) as e:
send_mail(
'out of stock',
'stock_admin@made.com',
f'{line.orderid} - {line.sku}'
)
return jsonify({'message': str(e)}), 400
return jsonify({'batchref': batchref}), 201…но легко понять, как мы можем быстро попасть в переделку, если так всё сделать. Отправка электронной почты не является задачей нашего HTTP-уровня, и мы хотели бы иметь возможность протестировать эту новую функцию.
9.1.2. И давайте не будем портить нашу модель
Предполагая, что мы не хотим помещать этот код в наши веб-контроллеры, потому что мы хотим, чтобы они были как можно более тонкими, мы можем посмотреть на то, чтобы поместить его прямо в источник, в модель:
def allocate(self, line: OrderLine) -> str:
try:
batch = next(
b for b in sorted(self.batches) if b.can_allocate(line)
)
#...
except StopIteration:
email.send_mail('stock@made.com', f'Out of stock for {line.sku}')
raise OutOfStock(f'Out of stock for sku {line.sku}')Но это еще хуже! Мы не хотим, чтобы наша модель имела какие-либо зависимости от инфраструктурных проблем, таких как email.send_mail.
Эта штука с отправкой электронной почты нежелательна сгусток, испортивший приятный чистый поток нашей системы. Мы хотели бы, чтобы наша модель предметной области была ориентирована на правило "Вы не можете выделить больше материала, чем на самом деле доступно."
9.1.3. Или уровень обслуживания!
Требование "Попробуйте распределить некоторый запас и отправить электронное письмо, если это не удастся" является примером оркестровки рабочего процесса: это набор шагов, которые система должна выполнить, чтобы достичь цели.
Мы написали сервисный уровень для управления оркестровкой для нас, но даже здесь эта функция кажется неуместной:
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork
) -> str:
line = OrderLine(orderid, sku, qty)
with uow:
product = uow.products.get(sku=line.sku)
if product is None:
raise InvalidSku(f'Invalid sku {line.sku}')
try:
batchref = product.allocate(line)
uow.commit()
return batchref
except model.OutOfStock:
email.send_mail('stock@made.com', f'Out of stock for {line.sku}')
raiseПоймать исключение и сделать ререйз? Могло быть и хуже, но это определенно нас огорчает. Почему так сложно найти подходящий дом для этого кода?
9.2. Single Responsibility Principle
На самом деле, это нарушение принципа единственной ответственности (SRP) .footnote: [Этот принцип — S в SOLID.] Наш пример использования — распределение. Наша конечная точка, служебная функция и методы домена называются [.keep-together] allocate, а не allocate_and_send_mail_if_out_of_stock.
| Эмпирическое правило: если вы не можете описать, что делает ваша функция, не используя такие слова, как "тогда" или "и", вы можете нарушить SRP. |
Согласно одной из формулировок SRP, у каждого класса должна быть только одна причина для изменения. Когда мы переключаемся с электронной почты на SMS, нам не нужно обновлять нашу функцию allocate(), потому что это явно отдельная ответственность.
Чтобы решить эту проблему, мы разделим оркестровку на отдельные этапы, чтобы различные проблемы не перепутались.[32] Задача модели домена состоит в том, чтобы знать, что у нас нет запасов, но ответственность за отправку предупреждения лежит на другом месте. Мы должны иметь возможность включать или выключать эту функцию или переключаться на SMS-уведомления вместо этого, не меняя правила нашей доменной модели.
Мы также хотели бы сохранить уровень сервиса свободным от деталей реализации. Мы хотим применить принцип инверсии зависимостей к уведомлениям, чтобы наш уровень обслуживания зависел от абстракции, точно так же, как мы избегаем зависимости от базы данных, используя единицу работы.
9.3. Все на борт автобуса Сообщений!
Шаблоны, которые мы собираемся здесь представить, - это Domain Events События домена и Message Bus Шина сообщений. Мы можем реализовать их несколькими способами, поэтому мы покажем пару, прежде чем остановимся на том, который нам больше всего нравится.
9.3.1. Модель Записывает События
Во-первых, вместо того, чтобы беспокоиться об электронных письмах, наша модель будет отвечать за регистрацию events (событий) - факты о том, что произошло. Мы будем использовать шину сообщений, чтобы отвечать на события и вызывать новую операцию.
9.3.2. События (events) - это простые классы данных
event-это своего рода value object. События не имеют никакого поведения, потому что они являются чистыми структурами данных. Мы всегда называем события на языке домена и думаем о них как о части нашей модели домена.
Мы могли бы хранить их в model.py, но мы также можем хранить их в отдельном файле. (возможно, сейчас самое подходящее время подумать о рефакторинге каталога с именем domain, чтобы у нас был domain/model.py и domain/events.py):
from dataclasses import dataclass
class Event: (1)
pass
@dataclass
class OutOfStock(Event): (2)
sku: str| 1 | Как только у нас будет несколько событий, нам будет полезно иметь родительский класс, который может хранить общие атрибуты. Это также полезно для подсказок типа в нашей шине сообщений, как вы вскоре увидите. |
| 2 | dataclasses отлично подходят и для доменных событий. |
9.3.3. Модель вызывает события
Когда наша модель домена фиксирует факт, который произошел, мы говорим, что это raises (поднимает) событие.
Вот как это будет выглядеть со стороны; если мы попросим "Product" распределить ( allocate ), но он не сможет, он должен raise (поднять) событие:
def test_records_out_of_stock_event_if_cannot_allocate():
batch = Batch('batch1', 'SMALL-FORK', 10, eta=today)
product = Product(sku="SMALL-FORK", batches=[batch])
product.allocate(OrderLine('order1', 'SMALL-FORK', 10))
allocation = product.allocate(OrderLine('order2', 'SMALL-FORK', 1))
assert product.events[-1] == events.OutOfStock(sku="SMALL-FORK") (1)
assert allocation is None| 1 | Наш агрегат предоставит новый атрибут под названием .events, который будет содержать список фактов о том, что произошло, в форме объектов Event. |
Вот как выглядит модель изнутри:
class Product:
def __init__(self, sku: str, batches: List[Batch], version_number: int = 0):
self.sku = sku
self.batches = batches
self.version_number = version_number
self.events = [] # type: List[events.Event] (1)
def allocate(self, line: OrderLine) -> str:
try:
#...
except StopIteration:
self.events.append(events.OutOfStock(line.sku)) (2)
# raise OutOfStock(f'Out of stock for sku {line.sku}') (3)
return None| 1 | Вот наш новый атрибут .events. |
| 2 | Вместо того, чтобы напрямую вызывать какой-либо код отправки электронной почты, мы записываем эти события в том месте, где они происходят, используя только язык домена. |
| 3 | Мы также собираемся прекратить создавать исключение для случая отсутствия на складе. Событие выполнит ту работу, которую выполняло исключение. |
| На самом деле мы "принюхиваемся" к коду, который мы рассматривали до сих пор, а именно к тому, что обсуждается в использование исключений для потока управления. В общем случае, если вы реализуете доменные события, не создавайте исключений для описания одной и той же концепции домена. Как вы увидите позже, когда мы будем обрабатывать события в шаблоне Unit of Work, это сбивает с толку, когда приходится рассуждать о совместном использовании событий и исключений. |
9.3.4. Шина сообщений сопоставляет События(Events) с Обработчиками(Handlers)
Шина сообщений в основном говорит: "Когда я вижу это событие, я должен вызвать следующую функцию обработчика". Другими словами, это простая система подписки на публикации. Обработчики подписаны (subscribed) на получение событий, которые мы размещаем в шине. Это звучит сложнее, чем есть на самом деле, и мы обычно реализуем это с помощью dict:
def handle(event: events.Event):
for handler in HANDLERS[type(event)]:
handler(event)
def send_out_of_stock_notification(event: events.OutOfStock):
email.send_mail(
'stock@made.com',
f'Out of stock for {event.sku}',
)
HANDLERS = {
events.OutOfStock: [send_out_of_stock_notification],
} # type: Dict[Type[events.Event], List[Callable]]| Обратите внимание, что реализованная шина сообщений не дает нам параллелизма, потому что одновременно будет работать только один обработчик. Наша цель состоит не в том, чтобы поддерживать параллельные потоки, а в том, чтобы концептуально разделить задачи и сделать каждый UoW как можно меньше. Это помогает нам понять кодовую базу, потому что "рецепт" для запуска каждого варианта использования написан в одном месте. См. следующую боковую панель. |
9.4. Вариант 1. Уровень сервиса Принимает События из Модели и Помещает их в Шину сообщений
Наша доменная модель вызывает события, и наша шина сообщений будет вызывать правые обработчики всякий раз, когда происходит событие. Теперь все, что нам нужно, — это соединить их. Нам нужно что-то, чтобы перехватить события из модели и передать их в шину сообщений — этап publishing.
Самый простой способ сделать это — добавить код в наш сервисный слой:
from . import messagebus
...
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork
) -> str:
line = OrderLine(orderid, sku, qty)
with uow:
product = uow.products.get(sku=line.sku)
if product is None:
raise InvalidSku(f'Invalid sku {line.sku}')
try: (1)
batchref = product.allocate(line)
uow.commit()
return batchref
finally: (1)
messagebus.handle(product.events) (2)| 1 | Мы сохраняем try/finally из нашей уродливой более ранней реализации (мы еще не избавились от всех исключений, просто OutOfStock). |
| 2 | Но теперь, вместо того чтобы напрямую зависеть от инфраструктуры электронной почты, уровень сервиса отвечает только за передачу событий от модели до шины сообщений. |
Это уже позволяет избежать некоторого уродства, которое мы имели в нашей наивной реализации, и у нас есть несколько систем, работающих подобно этой, в которых уровень обслуживания явно собирает события из агрегатов и передает их в шину сообщений.
9.5. Вариант 2: Уровень Сервиса Создает Свои Собственные События
Другой вариант, который мы использовали, - это сделать так, чтобы уровень сервиса отвечал за создание и инициирование событий напрямую, а не за их создание моделью предметной области:
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork
) -> str:
line = OrderLine(orderid, sku, qty)
with uow:
product = uow.products.get(sku=line.sku)
if product is None:
raise InvalidSku(f'Invalid sku {line.sku}')
batchref = product.allocate(line)
uow.commit() (1)
if batchref is None:
messagebus.handle(events.OutOfStock(line.sku))
return batchref| 1 | Как и раньше, мы коммитим событие, даже если ничего не можем зарезервировать, потому что код таким образом проще и легче понимать: мы всегда фиксируем, если что-то не идет не так. Фиксация, когда мы ничего не изменили, безопасна и сохраняет код незагроможденным. |
Опять же, у нас есть приложения в производстве (production), которые реализуют шаблон таким образом. То, что работает для вас, будет зависеть от конкретных компромиссов, с которыми вы столкнётесь, но мы хотели бы показать вам, что мы считаем наиболее элегантным решением, в котором мы помещаем единицу работы, отвечающую за сбор и обработку событий.
9.6. Вариант 3: UoW публикует события в шине сообщений
У UoW уже есть блок try/finally, и он знает обо всех агрегатах, находящихся в данный момент в игре, потому что он предоставляет доступ к репозиторию. Так что это хорошее место для обнаружения событий и передачи их в шину сообщений:
class AbstractUnitOfWork(abc.ABC):
...
def commit(self):
self._commit() (1)
self.publish_events() (2)
def publish_events(self): (2)
for product in self.products.seen: (3)
while product.events:
event = product.events.pop(0)
messagebus.handle(event)
@abc.abstractmethod
def _commit(self):
raise NotImplementedError
...
class SqlAlchemyUnitOfWork(AbstractUnitOfWork):
...
def _commit(self): (1)
self.session.commit()| 1 | Мы изменим наш метод фиксации, чтобы запросить частный метод ._commit() из подклассов. |
| 2 | После фиксации мы прогоняем все объекты, которые воспринял наш репозиторий, и передаем их события в шину сообщений. |
| 3 | Это зависит от репозитория, отслеживающего агрегаты, которые были загружены с использованием нового атрибута, .seen, как вы увидите в следующем листинге.
|
| Вам интересно, что произойдет, если один из обработчиков выйдет из строя? Мы подробно обсудим обработку ошибок в Команды и Обработчики команд. |
class AbstractRepository(abc.ABC):
def __init__(self):
self.seen = set() # type: Set[model.Product] (1)
def add(self, product: model.Product): (2)
self._add(product)
self.seen.add(product)
def get(self, sku) -> model.Product: (3)
product = self._get(sku)
if product:
self.seen.add(product)
return product
@abc.abstractmethod
def _add(self, product: model.Product): (2)
raise NotImplementedError
@abc.abstractmethod (3)
def _get(self, sku) -> model.Product:
raise NotImplementedError
class SqlAlchemyRepository(AbstractRepository):
def __init__(self, session):
super().__init__()
self.session = session
def _add(self, product): (2)
self.session.add(product)
def _get(self, sku): (3)
return self.session.query(model.Product).filter_by(sku=sku).first()| 1 | Чтобы UoW мог публиковать новые события, он должен иметь возможность запрашивать репозиторий, для каких объектов Product использовались во время этого сеанса. Мы используем set под названием` .seen` для их хранения. Это означает, что наши реализации должны вызывать super().__ init __() .
|
| 2 | Родительский метод add() добавляет элементы в .seen и теперь требует jn подклассов реализацию ._add(). |
| 3 | Аналогично, .get() делегирует функцию ._get (), которая должна быть реализована подклассами, чтобы захватить видимые объекты. |
Использование методов ._underscorey() и подклассов определенно не является единственным способом реализации этих шаблонов. Попробуйте воспользоваться "Упражнения для читателя" в этой главе и поэкспериментируйте с некоторыми альтернативами.
|
После того, как UoW и репозиторий будут сотрудничать таким образом, чтобы автоматически отслеживать живые объекты и обрабатывать их события, уровень сервиса может быть полностью свободен от проблем с обработкой событий:
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork
) -> str:
line = OrderLine(orderid, sku, qty)
with uow:
product = uow.products.get(sku=line.sku)
if product is None:
raise InvalidSku(f'Invalid sku {line.sku}')
batchref = product.allocate(line)
uow.commit()
return batchref
Мы также должны помнить, что надо изменить фейки в сервисном слое и заставить их вызывать super() в нужных местах, а также реализовать методы c двойным подчёркиванием ("str","repr"), но изменения минимальны:
class FakeRepository(repository.AbstractRepository):
def __init__(self, products):
super().__init__()
self._products = set(products)
def _add(self, product):
self._products.add(product)
def _get(self, sku):
return next((p for p in self._products if p.sku == sku), None)
...
class FakeUnitOfWork(unit_of_work.AbstractUnitOfWork):
...
def _commit(self):
self.committed = TrueВозможно, вы начинаете беспокоиться о том, что поддержание этих фейков будет бременем для обслуживания. Нет никаких сомнений, что это работа, но по нашему опыту это не так уж много работы. Как только ваш проект запущен и работает, интерфейс для вашего репозитория и абстракций UoW действительно не сильно меняется. И если вы используете ABC, это поможет вам вспомнить, когда что-то выходит из синхронизации.
9.7. Подведение итогов
События домена дают нам возможность управлять рабочими процессами в нашей системе. Мы часто обнаруживаем, слушая наших экспертов в предметной области, что они выражают требования причинным или временным образом - например, «Когда мы пытаемся распределить запасы, но их нет в наличии, мы должны отправить электронное письмо отделу снабжения».
Волшебные слова "When X, then Y" часто говорят нам о событии, которое мы можем сделать конкретным в нашей системе. Рассматривая события как first-class вещи в нашей модели, мы делаем наш код более тестируемым и наблюдаемым, а также изолируем проблемы.
И Domain events: компромиссы показывает компромиссы, как мы их видим.
| Плюсы | Минусы |
|---|---|
|
|
Однако события полезны не только для отправки электронной почты. В Агрегаты и границы консистентности мы потратили много времени, убеждая вас, что вы должны определить агрегаты или границы, где мы гарантируем согласованность. Люди часто спрашивают: "Что мне делать, если мне нужно изменить несколько агрегатов в рамках запроса?" Теперь у нас есть инструменты, необходимые для ответа на этот вопрос.
Если у нас есть две вещи, которые могут быть транзакционно изолированы (например, заказ и product), то мы можем сделать их eventually consistent (в конечном итоге согласованными) с помощью событий. Когда заказ отменяется, мы должны найти продукты, которые были ему назначены, и удалить allocations.
В Едем в город на Мессагобусе мы рассмотрим эту идею более подробно при построении более сложного рабочего процесса с нашей новой шиной сообщений.
10. Едем в город на Мессагобусе
В этой главе мы начнем делать события более фундаментальными для внутренней структуры нашего приложения. Мы перейдем из текущего состояния в Раньше: шина сообщений являлась необязательным дополнением, где события являются необязательным побочным эффектом …

…к ситуации в Шина сообщений теперь является основной точкой входа на уровень сервиса., где всё идет по шине сообщений, а наше приложение было принципиально преобразовано в процессор сообщений.
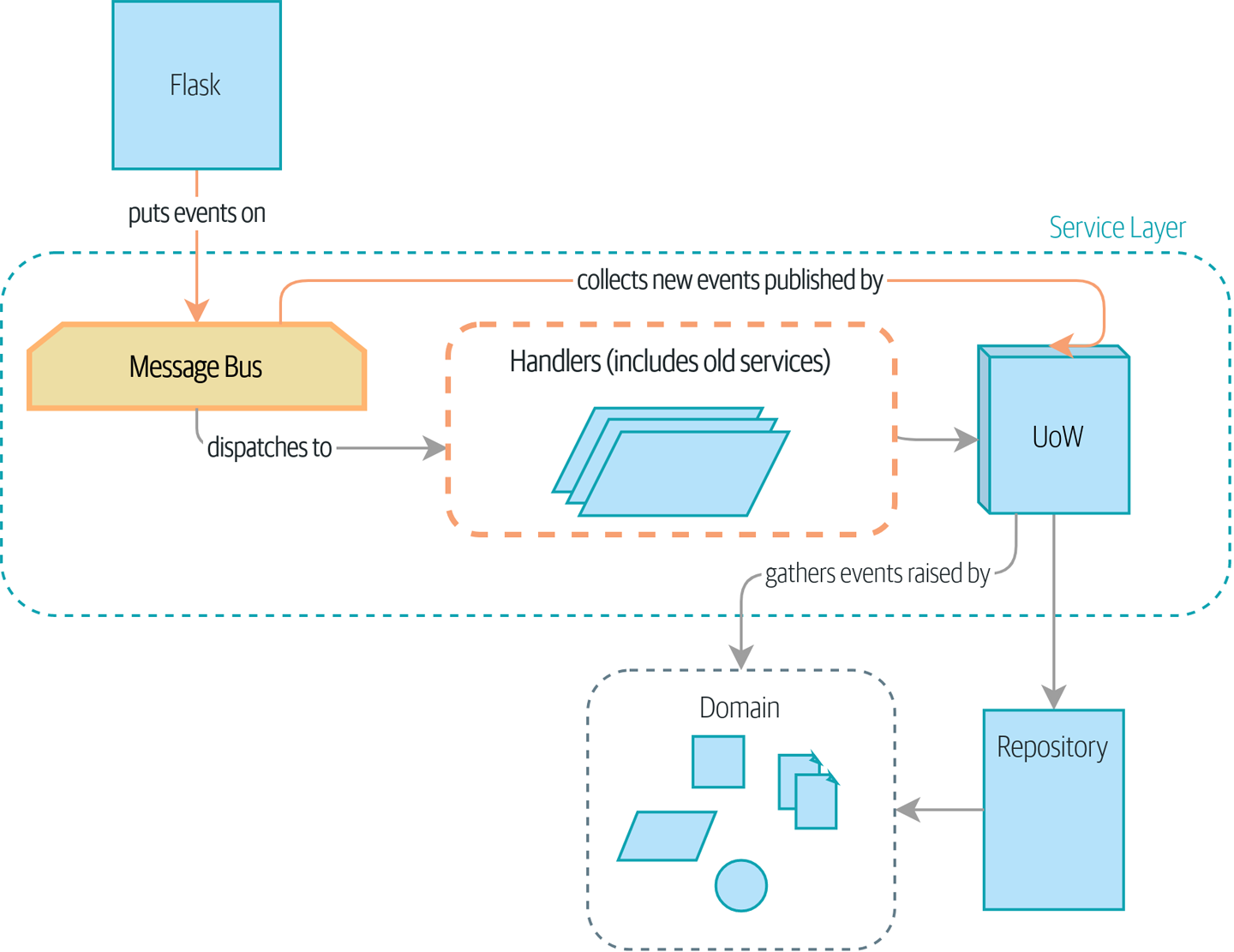
|
Код для этой главы находится в ветке chapter_09_all_messagebus. на GitHub: git clone https://github.com/cosmicpython/code.git cd code git checkout chapter_09_all_messagebus # или, чтобы кодировать вместе, проверьте предыдущую главу: git checkout chapter_08_events_and_message_bus |
10.1. Новое требование приводит нас к новой архитектуре
Рич Хикки говорит о situated software, то есть о программном обеспечении, которое работает в течение длительных периодов времени, управляя реальным процессом. Примеры включают системы управления складом, логистические планировщики и системы расчета заработной платы.
Такое программное обеспечение сложно написать, потому что в реальном мире физических объектов и ненадежных людей постоянно происходят неожиданные вещи. Например:
-
Во время инвентаризации мы обнаруживаем, что три <код>ПРУЖИННЫЙ МАТРАСбыли повреждены водой из-за протекающей крыши.
-
У груза
RELIABLE-FORKs отсутствует необходимая документация и он застрял на таможне, где находится уже в течение нескольких недель. ТриRELIABLE-FORKs впоследствии не проходят проверку безопасности и уничтожаются. -
Глобальная нехватка блесток означает, что мы не сможем изготовить следующую партию
SPARKLY-BOOKCASE.
В таких ситуациях мы узнаем о необходимости изменения количества партий, когда они уже находятся в системе. Может быть, кто-то ошибся номером в декларации, а может быть, какие-то диваны упали с грузовика. После разговора с представителями компании[33] мы моделируем ситуацию, как на Изменение количества партии означает освобождение и перераспределение (deallocate and reallocate).

[ditaa, apwp_0903]
+----------+ /----\ +------------+ +--------------------+
| Batch |--> |RULE| --> | Deallocate | ----> | AllocationRequired |
| Quantity | \----/ +------------+-+ +--------------------+-+
| Changed | | Deallocate | ----> | AllocationRequired |
+----------+ +------------+-+ +--------------------+-+
| Deallocate | ----> | AllocationRequired |
+------------+ +--------------------+
Событие, которое мы назовем BatchQuantityChanged, должно привести нас к изменению количества в партии, да, но также и к применению бизнес правила: если новое количество опускается до меньшего, чем уже распределённое общее количество, нам нужно dealocate освободить места в этих заказы из этой партии. Затем каждый из них потребует нового распределения, которое мы можем зафиксировать как событие под названием AllocationRequired Требуемое распределение.
Возможно, вы уже ожидаете, что наша внутренняя шина сообщений и события помогут реализовать это требование. Мы могли бы определить службу под названием change_batch_quantity, которая знает, как корректировать количество партий, а также как deallocate (освобождать) любые избыточные строки заказа, а затем каждое освобождение может генерировать событие AllocationRequired, которое может быть перенаправлено существующей службе allocate (распределения) в отдельные транзакции. И снова наша шина сообщений помогает нам обеспечивать соблюдение принципа единой ответственности и позволяет нам делать выбор в отношении транзакций и целостности данных.
10.1.1. Представим себе изменение архитектуры: всё будет event handler Обработчик событий
Но прежде чем запрыгнуть в это, подумай, куда мы направляемся. Существует два вида потоков через нашу систему:
-
Вызовы API, которые обрабатываются функцией уровня сервиса
-
Внутренние события (которые могут быть вызваны как побочный эффект функции уровня сервиса) и их обработчики (которые, в свою очередь, вызывают функции уровня сервиса)
Разве не было бы проще, если бы все было обработчиком событий? Если мы переосмыслим наши вызовы API как захват событий, функции уровня сервиса также могут быть обработчиками событий, и нам больше не нужно проводить различие между внутренними и внешними обработчиками событий:
-
services.allocate()может быть обработчиком событияAllocationRequiredи может выдавать событияAllocatedв качестве его выходных данных. -
services.add_batch()может быть обработчиком событияBatchCreated.[34]
Наше новое требование будет соответствовать той же схеме:
-
Событие под названием
BatchQuantityChangedможет вызывать обработчик под названиемchange_batch_quantity(). -
И новые события
AllocationRequired, которые он может вызвать, также могут быть переданы в `services.allocate() `, поэтому нет концептуальной разницы между совершенно новым распределением, исходящим от API, и перераспределением, которое запускается изнутри deallocate.
Все это звучит как-то чересчур? Давайте работать над всем этим постепенно. Мы будем следовать за рабочим процессом Подготовительный рефакторинг, он же гласит "Сделайте изменение легким; затем сделайте легкое изменение":
-
Мы рефакторингуем наш уровень обслуживания в обработчики событий. Мы можем привыкнуть к идее о том, что события-это способ описания входов в систему. В частности, существующая функция
services.allocate()станет обработчиком события под названиемAllocationRequired. -
Мы создаем сквозной тест,который помещает события
BatchQuantityChangedв систему и принимает выходящие событияAllocated. -
Наша реализация концептуально будет очень простой: новый обработчик событий
BatchQuantityChanged, реализация которого будет выдавать событияAllocationRequired, которые, в свою очередь, будут обрабатываться точно таким же обработчиком распределений, который использует API.
По пути мы сделаем небольшую настройку шины сообщений и UoW, перенеся ответственность за размещение (put) новых событий на шине сообщений в саму шину сообщений.
10.2. Рефакторинг сервисных функций для обработчиков сообщений
Мы начинаем с определения двух событий, которые фиксируют наши текущие входные данные API - AllocationRequired и BatchCreated:
@dataclass
class BatchCreated(Event):
ref: str
sku: str
qty: int
eta: Optional[date] = None
...
@dataclass
class AllocationRequired(Event):
orderid: str
sku: str
qty: intЗатем мы переименовываем services.py в handlers.py; мы добавляем обработчик текущих сообщений для send_out_of_stock_notification; и самое главное, мы меняем все обработчики так, чтобы у них были одинаковые входные данные, событие и UoW:
def add_batch(
event: events.BatchCreated, uow: unit_of_work.AbstractUnitOfWork
):
with uow:
product = uow.products.get(sku=event.sku)
...
def allocate(
event: events.AllocationRequired, uow: unit_of_work.AbstractUnitOfWork
) -> str:
line = OrderLine(event.orderid, event.sku, event.qty)
...
def send_out_of_stock_notification(
event: events.OutOfStock, uow: unit_of_work.AbstractUnitOfWork,
):
email.send(
'stock@made.com',
f'Out of stock for {event.sku}',
)Это изменение станет более ясным если помотреть на различие:
def add_batch(
- ref: str, sku: str, qty: int, eta: Optional[date],
- uow: unit_of_work.AbstractUnitOfWork
+ event: events.BatchCreated, uow: unit_of_work.AbstractUnitOfWork
):
with uow:
- product = uow.products.get(sku=sku)
+ product = uow.products.get(sku=event.sku)
...
def allocate(
- orderid: str, sku: str, qty: int,
- uow: unit_of_work.AbstractUnitOfWork
+ event: events.AllocationRequired, uow: unit_of_work.AbstractUnitOfWork
) -> str:
- line = OrderLine(orderid, sku, qty)
+ line = OrderLine(event.orderid, event.sku, event.qty)
...
+
+def send_out_of_stock_notification(
+ event: events.OutOfStock, uow: unit_of_work.AbstractUnitOfWork,
+):
+ email.send(
...Попутно мы сделали API нашего сервисного уровня более структурированным и последовательным. Это было рассеяние примитивов, и теперь используются четко определенные объекты (см. Следующую главу).
10.2.1. The Message Bus Now Collects Events from the UoW
Наши обработчики событий теперь нуждаются в UoW. Кроме того, поскольку наша шина сообщений становится всё более центральной для нашего приложения, имеет смысл явно возложить на неё ответственность за сбор и обработку новых событий. До сих пор существовала некоторая циклическая зависимость между UoW и шиной сообщений, так что это сделает её односторонней. Вместо того, чтобы иметь события UoW push на шине сообщений, мы будем иметь события message bus pull из UoW.
def handle(event: events.Event, uow: unit_of_work.AbstractUnitOfWork): (1)
queue = [event] (2)
while queue:
event = queue.pop(0) (3)
for handler in HANDLERS[type(event)]: (3)
handler(event, uow=uow) (4)
queue.extend(uow.collect_new_events()) (5)| 1 | Шина сообщений теперь проходит UoW при каждом запуске. |
| 2 | Когда мы начинаем обрабатывать наше первое событие, мы запускаем очередь. |
| 3 | Мы извлекаем события из передней части очереди и вызываем их обработчики (HANDLERS dict не изменился; он по-прежнему сопоставляет типы событий с функциями обработчиков). |
| 4 | Шина сообщений передает UoW каждому обработчику. |
| 5 | После завершения каждого обработчика мы собираем все новые сгенерированные события и добавляем их в очередь. |
В unit_of_work.py 'publish_events()` становится менее активным методом, collect_new_events():
-from . import messagebus (1)
-
class AbstractUnitOfWork(abc.ABC):
@@ -23,13 +21,11 @@ class AbstractUnitOfWork(abc.ABC):
def commit(self):
self._commit()
- self.publish_events() (2)
- def publish_events(self):
+ def collect_new_events(self):
for product in self.products.seen:
while product.events:
- event = product.events.pop(0)
- messagebus.handle(event)
+ yield product.events.pop(0) (3)| 1 | Модуль unit_of_work теперь больше не зависит от messagebus. |
| 2 | Мы больше не выполняем publish_events автоматически при фиксации. Вместо этого шина сообщений отслеживает очередь событий. |
| 3 | И UoW больше не размещает активные события в шину сообщений; он просто делает их доступными. |
10.2.2. Наши тесты тоже написаны в терминах событий
Наши тесты теперь работают, создавая события и помещая их в шину сообщений, а не вызывая функции сервисного уровня напрямую:
class TestAddBatch:
def test_for_new_product(self):
uow = FakeUnitOfWork()
- services.add_batch("b1", "CRUNCHY-ARMCHAIR", 100, None, uow)
+ messagebus.handle(
+ events.BatchCreated("b1", "CRUNCHY-ARMCHAIR", 100, None), uow
+ )
assert uow.products.get("CRUNCHY-ARMCHAIR") is not None
assert uow.committed
...
class TestAllocate:
def test_returns_allocation(self):
uow = FakeUnitOfWork()
- services.add_batch("batch1", "COMPLICATED-LAMP", 100, None, uow)
- result = services.allocate("o1", "COMPLICATED-LAMP", 10, uow)
+ messagebus.handle(
+ events.BatchCreated("batch1", "COMPLICATED-LAMP", 100, None), uow
+ )
+ result = messagebus.handle(
+ events.AllocationRequired("o1", "COMPLICATED-LAMP", 10), uow
+ )
assert result == "batch1"10.2.3. Временный Наглый Взлом: шина сообщений должна возвращать результаты
Наш API и наш уровень сервиса в настоящее время хотят узнать выделенную ссылку на пакет, когда они вызывают наш обработчик allocate(). Это означает, что нам нужно временно взломать нашу шину сообщений, чтобы она возвращала события:
def handle(event: events.Event, uow: unit_of_work.AbstractUnitOfWork):
+ results = []
queue = [event]
while queue:
event = queue.pop(0)
for handler in HANDLERS[type(event)]:
- handler(event, uow=uow)
+ results.append(handler(event, uow=uow))
queue.extend(uow.collect_new_events())
+ return resultsЭто потому, что мы смешиваем обязанности чтения и записи в нашей системе. Мы вернемся, чтобы исправить эту неприятность в Command-Query Responsibility Segregation (CQRS)[1].
10.2.4. Изменение нашего API для работы с событиями
@app.route("/allocate", methods=['POST'])
def allocate_endpoint():
try:
- batchref = services.allocate(
- request.json['orderid'], (1)
- request.json['sku'],
- request.json['qty'],
- unit_of_work.SqlAlchemyUnitOfWork(),
+ event = events.AllocationRequired( (2)
+ request.json['orderid'], request.json['sku'], request.json['qty'],
)
+ results = messagebus.handle(event, unit_of_work.SqlAlchemyUnitOfWork()) (3)
+ batchref = results.pop(0)
except InvalidSku as e:| 1 | Вместо вызова уровня сервиса с кучей примитивов, извлеченных из запроса JSON … |
| 2 | Создаем событие. |
| 3 | Затем передаем его в шину сообщений. |
И мы должны вернуться к полностью функциональному приложению, но теперь полностью управляемому событиями:
-
То, что раньше было функциями сервисного уровня, теперь стало обработчиками событий.
-
Это делает их такими же, как функции, которые мы вызываем для обработки внутренних событий, вызванных нашей моделью предметной области.
-
Мы используем события в качестве структуры данных для сбора входных данных в систему, а также для передачи внутренних рабочих пакетов.
-
Теперь все приложение лучше всего описать как процессор сообщений или, если хотите, процессор событий. Мы поговорим об этом различии в следующей главеКоманды и Обработчики команд.
10.3. Реализация нашего нового требования (Requirement)
Мы закончили с фазой рефакторинга. Давайте посмотрим, действительно ли мы "сделали изменение легким." Давайте реализуем наше новое требование, показанное в Диаграмма последовательности для потока перераспределения: мы получим в качестве входных данных некоторые новые события BatchQuantityChanged и передадим их обработчику, который, в свою очередь, может выдать некоторые события AllocationRequired, а те, в свою очередь, вернутся к нашему существующему обработчику для перераспределения.
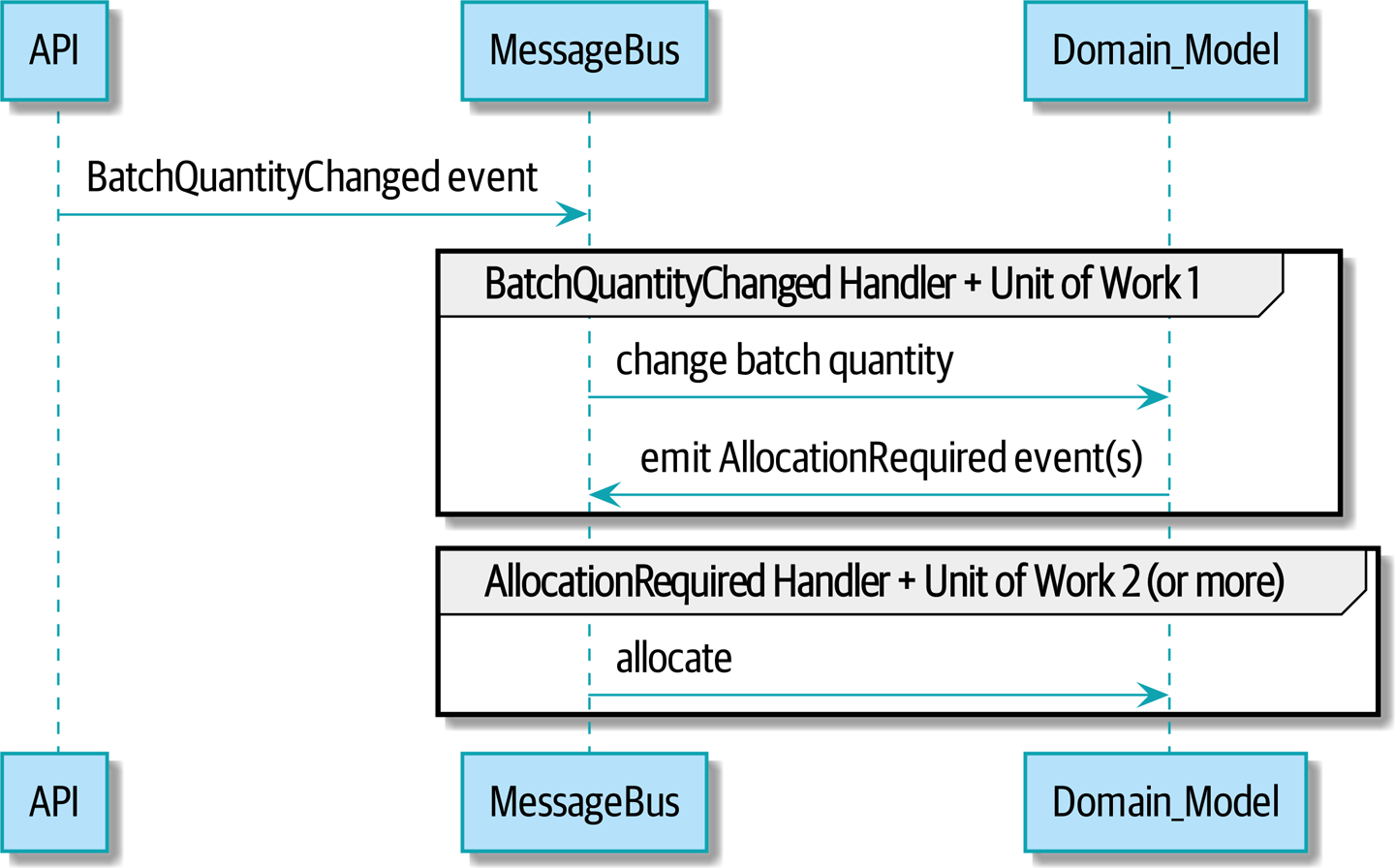
[plantuml, apwp_0904, config=plantuml.cfg]
@startuml
scale 4
API -> MessageBus : BatchQuantityChanged event
group BatchQuantityChanged Handler + Unit of Work 1
MessageBus -> Domain_Model : change batch quantity
Domain_Model -> MessageBus : emit AllocationRequired event(s)
end
group AllocationRequired Handler + Unit of Work 2 (or more)
MessageBus -> Domain_Model : allocate
end
@enduml
| Когда вы разделяете вещи таким образом на две единицы работы, то у вас получаются две транзакции базы данных, поэтому вы открываете себя для проблем целостности: что-то может произойти, и это означает, что первая транзакция завершается, а вторая-нет. Вам нужно будет подумать о том, приемлемо ли это, и нужно ли вам замечать, когда это происходит, и что-то с этим делать. См. Footguns для более подробного обсуждения. |
10.3.1. Наше новое событие
Событие, которое говорит нам, что количество партии изменилось, простое; ему просто нужна ссылка на партию и новое количество:
@dataclass
class BatchQuantityChanged(Event):
ref: str
qty: int10.4. Test-Driving нового Handler
Следуя урокам, извлеченным из Наш первый Use Case или пример использования: Flask API и Service Layer, мы можем работать на «высокой передаче» и писать наши модульные тесты на максимально возможном уровне абстракции с точки зрения событий. Вот как они могут выглядеть:
class TestChangeBatchQuantity:
def test_changes_available_quantity(self):
uow = FakeUnitOfWork()
messagebus.handle(
events.BatchCreated("batch1", "ADORABLE-SETTEE", 100, None), uow
)
[batch] = uow.products.get(sku="ADORABLE-SETTEE").batches
assert batch.available_quantity == 100 (1)
messagebus.handle(events.BatchQuantityChanged("batch1", 50), uow)
assert batch.available_quantity == 50 (1)
def test_reallocates_if_necessary(self):
uow = FakeUnitOfWork()
event_history = [
events.BatchCreated("batch1", "INDIFFERENT-TABLE", 50, None),
events.BatchCreated("batch2", "INDIFFERENT-TABLE", 50, date.today()),
events.AllocationRequired("order1", "INDIFFERENT-TABLE", 20),
events.AllocationRequired("order2", "INDIFFERENT-TABLE", 20),
]
for e in event_history:
messagebus.handle(e, uow)
[batch1, batch2] = uow.products.get(sku="INDIFFERENT-TABLE").batches
assert batch1.available_quantity == 10
assert batch2.available_quantity == 50
messagebus.handle(events.BatchQuantityChanged("batch1", 25), uow)
# order1 or order2 will be deallocated, so we'll have 25 - 20
assert batch1.available_quantity == 5 (2)
# and 20 will be reallocated to the next batch
assert batch2.available_quantity == 30 (2)| 1 | Простой случай будет тривиально легко реализовать; мы просто модифицируем количество. |
| 2 | Но если мы попытаемся изменить количество на меньшее, чем было выделено, нам нужно будет исключить по крайней мере один заказ, и перераспределить его на новую ожидаемую партию. |
10.4.1. Реализация
Наш новый обработчик очень прост:
def change_batch_quantity(
event: events.BatchQuantityChanged, uow: unit_of_work.AbstractUnitOfWork
):
with uow:
product = uow.products.get_by_batchref(batchref=event.ref)
product.change_batch_quantity(ref=event.ref, qty=event.qty)
uow.commit()Мы понимаем, что нам понадобится новый тип запроса в нашем репозитории:
class AbstractRepository(abc.ABC):
...
def get(self, sku) -> model.Product:
...
def get_by_batchref(self, batchref) -> model.Product:
product = self._get_by_batchref(batchref)
if product:
self.seen.add(product)
return product
@abc.abstractmethod
def _add(self, product: model.Product):
raise NotImplementedError
@abc.abstractmethod
def _get(self, sku) -> model.Product:
raise NotImplementedError
@abc.abstractmethod
def _get_by_batchref(self, batchref) -> model.Product:
raise NotImplementedError
...
class SqlAlchemyRepository(AbstractRepository):
...
def _get(self, sku):
return self.session.query(model.Product).filter_by(sku=sku).first()
def _get_by_batchref(self, batchref):
return self.session.query(model.Product).join(model.Batch).filter(
orm.batches.c.reference == batchref,
).first()И в нашем FakeRepository:
class FakeRepository(repository.AbstractRepository):
...
def _get(self, sku):
return next((p for p in self._products if p.sku == sku), None)
def _get_by_batchref(self, batchref):
return next((
p for p in self._products for b in p.batches
if b.reference == batchref
), None)
Мы добавляем запрос в наш репозиторий, чтобы упростить реализацию этого варианта использования. Пока наш запрос возвращает единственную совокупность, мы не нарушаем никаких правил. Если вы обнаружите, что пишете сложные запросы к своим репозиториям, возможно, вам захочется рассмотреть другой дизайн. Такие методы, как get_most_popular_products или find_products_by_order_id, в частности, определенно вызовут щекотку в области нашего шестого чувства. В Event-Driven Architecture: Использование событий для интеграции микросервисов и epilogue есть несколько советов по управлению сложными запросами.
|
10.4.2. Новый метод модели предметной области
Мы добавляем в модель новый метод, который выполняет изменение количества и освобождение(ий) встроенным и публикует новое событие. Мы также модифицируем существующую функцию выделения для публикации события:
class Product:
...
def change_batch_quantity(self, ref: str, qty: int):
batch = next(b for b in self.batches if b.reference == ref)
batch._purchased_quantity = qty
while batch.available_quantity < 0:
line = batch.deallocate_one()
self.events.append(
events.AllocationRequired(line.orderid, line.sku, line.qty)
)
...
class Batch:
...
def deallocate_one(self) -> OrderLine:
return self._allocations.pop()Подключаем наш новый обработчик:
HANDLERS = {
events.BatchCreated: [handlers.add_batch],
events.BatchQuantityChanged: [handlers.change_batch_quantity],
events.AllocationRequired: [handlers.allocate],
events.OutOfStock: [handlers.send_out_of_stock_notification],
} # type: Dict[Type[events.Event], List[Callable]]И наше новое требование полностью выполнено.
10.5. Опционально: Модульное тестирование Event Handlers изолированно с Fake Message Bus
Наш основной тест для рабочего процесса перераспределения-это edge-to-edge (см. Пример кода в Test-Driving нового Handler). Он использует реальную шину сообщений и тестирует весь поток, где обработчик событий BatchQuantityChanged запускает освобождение и выдает новые события AllocationRequired, которые, в свою очередь, обрабатываются их собственными обработчиками. Один тест охватывает цепочку из нескольких событий и обработчиков.
В зависимости от сложности цепочки событий вы можете решить, что хотите протестировать некоторые обработчики отдельно друг от друга. Вы можете сделать это с помощью "поддельной" шины сообщений.
В нашем случае мы фактически вмешиваемся, изменяя метод publish_events() в FakeUnitOfWork и отделяя его от реальной шины сообщений, вместо этого заставляя его записывать события, которые он видит:
class FakeUnitOfWorkWithFakeMessageBus(FakeUnitOfWork):
def __init__(self):
super().__init__()
self.events_published = [] # type: List[events.Event]
def publish_events(self):
for product in self.products.seen:
while product.events:
self.events_published.append(product.events.pop(0))
Теперь, когда мы вызываем messagebus.handle() используя FakeUnitOfWorkWithFakeMessageBus, он запускает только обработчик этого события. Таким образом, мы можем написать более изолированный модульный тест: вместо проверки всех побочных эффектов мы просто проверяем, что BatchQuantityChanged приводит к AllocationRequired, если количество падает ниже уже выделенного общего количества:
def test_reallocates_if_necessary_isolated():
uow = FakeUnitOfWorkWithFakeMessageBus()
# test setup as before
event_history = [
events.BatchCreated("batch1", "INDIFFERENT-TABLE", 50, None),
events.BatchCreated("batch2", "INDIFFERENT-TABLE", 50, date.today()),
events.AllocationRequired("order1", "INDIFFERENT-TABLE", 20),
events.AllocationRequired("order2", "INDIFFERENT-TABLE", 20),
]
for e in event_history:
messagebus.handle(e, uow)
[batch1, batch2] = uow.products.get(sku="INDIFFERENT-TABLE").batches
assert batch1.available_quantity == 10
assert batch2.available_quantity == 50
messagebus.handle(events.BatchQuantityChanged("batch1", 25), uow)
# assert on new events emitted rather than downstream side-effects
[reallocation_event] = uow.events_published
assert isinstance(reallocation_event, events.AllocationRequired)
assert reallocation_event.orderid in {'order1', 'order2'}
assert reallocation_event.sku == 'INDIFFERENT-TABLE'Хотите вы этого или нет, зависит от сложности вашей цепочки событий. Мы говорим: начните с сквозного тестирования и прибегайте к нему только в случае необходимости.
10.6. Подведём итоги
Давайте оглянемся на то, чего мы достигли, и подумаем, "А нафига?".
10.6.1. Чего мы достигли?
События (Events) - это простые классы данных, которые определяют структуры данных для входных данных. и внутренние сообщения в нашей системе. Это довольно мощно с точки зрения DDD, поскольку события часто очень хорошо переводятся на деловой язык (look up event storming if you haven’t already).
Обработчики (Handlers) - это то, как мы реагируем на события. Они могут обратиться к нашей модели или обратиться к внешним службам. Мы можем определить несколько обработчиков для одного события, если захотим. Обработчики также могут вызывать другие события. Это позволяет нам быть очень детальными в отношении того, что делает обработчик, и действительно придерживаться SRP.
10.6.2. Почему мы достигли цели?
Наша основная цель в отношении этих структурных моделей заключается в том, чтобы сложность нашего приложения росла медленнее, чем его размер. Когда мы идем ва-банк на шине сообщений, то как всегда, платим цену с точки зрения архитектурной сложности (См. Все приложение - это шина сообщений: компромиссы), но мы приобретаем себе паттерн, который может обрабатывать сколь угодно сложные требования, не нуждаясь в дальнейших концептуальных или архитектурных изменениях в том, как мы делаем вещи.
Здесь мы добавили довольно сложный вариант использования (изменить количество, освободить место, начать новую транзакцию, перераспределить место, опубликовать внешнее уведомление), но в архитектурном плане сложность не требует затрат. Мы добавили новые события, новые обработчики и новый внешний адаптер (для электронной почты), все из которых являются существующими категориями объектов в нашей архитектуре, которые понятны нам и это легко объяснимы новичкам. Каждая из наших подвижных частей выполняет одну задачу, они четко связаны друг с другом, и нет никаких неожиданных побочных эффектов.
| Плюсы | Минусы |
|---|---|
|
|
Теперь вам может быть интересно, откуда берутся эти события BatchQuantityChanged? Ответ станет понятен через пару глав. Но сначала давайте поговорим о событиях в сравнении с командами events versus commands.
11. Команды и Обработчики команд
В предыдущей главе мы говорили об использовании событий как способа представления входных данных для нашей системы, и превратили наше приложение в машину обработки сообщений.
Для этого мы преобразовали все наши use-case функции в обработчики событий. Когда API получает POST для создания нового пакета (batch), он выстраивает новое событие 'BatchCreated' и обрабатывает его так, как если бы это было внутреннее событие. Это может показаться нелогичным. В конце концов, пакет еще не создан; вот почему мы вызвали API. Мы собираемся исправить эту концептуальную бородавку, введя команды и показав, как они могут обрабатываться одной и той же шиной сообщений, но с легка другими правилами.
|
Код для этой главы находится в chapter_10_commands branch on GitHub: git clone https://github.com/cosmicpython/code.git cd code git checkout chapter_10_commands # или, чтобы кодировать вместе, проверьте предыдущую главу: git checkout chapter_09_all_messagebus |
11.1. Commands и Events
Как и события, commands-это тип message—instructions, посылаемые одной частью системы другой. Мы обычно представляем команды с тупыми структурами данных и можем обрабатывать их почти так же, как события.
Однако различия между командами(commands) и событиями(events) очень важны.
Команды посылаются одним актором другому конкретному актору в надежде, что в результате произойдет то или иное событие. Когда мы отправляем форму обработчику API, мы посылаем команду. Мы называем команды глаголами повелительного наклонения, такими как "выделить запас" (allocate stock) или "задержать отгрузку"(delay shipment).
Команды захватывают намерение. Они выражают наше желание, чтобы система что-то сделала. В результате, когда они потерпят неудачу, отправитель должен получить информацию об ошибке.
События транслируются актором всем заинтересованным слушателям (listeners). Когда мы публикуем 'BatchQuantityChanged', мы не знаем, кто его возьмет. Мы называем события глагольными фразами прошедшего времени, такими как "заказ распределен на складе"(order allocated to stock) или "отгрузка задержана" (shipment delayed).
Мы часто используем события для распространения знаний об успешных командах.
События фиксируют факты о том, что происходило в прошлом. Поскольку мы не знаем, кто обрабатывает событие, отправителей не должно волновать, удовлетворены ли получатели или нет. События против команд резюмирует различия.
| Событие | Команда | |
|---|---|---|
Название |
Прошедшее время |
Повелительное наклонение |
Обработка ошибок |
Частная неудача |
Шумный Сбой |
Отправлено для |
Всех слушателей |
Единственного получателя |
Какие команды есть у нас сейчас в нашей системе?
class Command:
pass
@dataclass
class Allocate(Command): (1)
orderid: str
sku: str
qty: int
@dataclass
class CreateBatch(Command): (2)
ref: str
sku: str
qty: int
eta: Optional[date] = None
@dataclass
class ChangeBatchQuantity(Command): (3)
ref: str
qty: int| 1 | commands.Allocate заменит events.AllocationRequired. |
| 2 | commands.CreateBatch заменит events.BatchCreated. |
| 3 | commands.ChangeBatchQuantity заменит events.BatchQuantityChanged. |
11.2. Различия в обработке исключений
Просто изменение имен и форм глаголов-это очень хорошо, но это не изменит поведение нашей системы. Мы хотим относиться к событиям и командам одинаково, но не совсем одинаково. Давайте посмотрим, как меняется наша шина сообщений:
Message = Union[commands.Command, events.Event]
def handle(message: Message, uow: unit_of_work.AbstractUnitOfWork): (1)
results = []
queue = [message]
while queue:
message = queue.pop(0)
if isinstance(message, events.Event):
handle_event(message, queue, uow) (2)
elif isinstance(message, commands.Command):
cmd_result = handle_command(message, queue, uow) (2)
results.append(cmd_result)
else:
raise Exception(f'{message} was not an Event or Command')
return results| 1 | У него все еще есть главная точка входа handle(), которая принимает message, который может быть командой или событием. |
| 2 | Мы отправляем события и команды двум различным вспомогательным функциям, показанным далее. |
Вот как мы справляемся с событиями:
def handle_event(
event: events.Event,
queue: List[Message],
uow: unit_of_work.AbstractUnitOfWork
):
for handler in EVENT_HANDLERS[type(event)]: (1)
try:
logger.debug('обработка события %s с помощью обработчика %s', event, handler)
handler(event, uow=uow)
queue.extend(uow.collect_new_events())
except Exception:
logger.exception('Exception handling event %s', event)
continue (2)| 1 | События передаются диспетчеру, который может делегировать их нескольким обработчикам на одно событие. |
| 2 | Он ловит и регистрирует ошибки, но не позволяет им прерывать обработку сообщений. |
А вот команду мы делаем так:
def handle_command(
command: commands.Command,
queue: List[Message],
uow: unit_of_work.AbstractUnitOfWork
):
logger.debug('handling command %s', command)
try:
handler = COMMAND_HANDLERS[type(command)] (1)
result = handler(command, uow=uow)
queue.extend(uow.collect_new_events())
return result (3)
except Exception:
logger.exception('Exception handling command %s', command)
raise (2)| 1 | Диспетчер команд ожидает только одного обработчика для каждой команды. |
| 2 | Если возникают какие-либо ошибки, они быстро терпят неудачу и будут пузыриться. |
| 3 | возвращаемый результат является только временным; как уже упоминалось в Временный Наглый Взлом: шина сообщений должна возвращать результаты, это временный хак, позволяющий шине сообщений возвращать пакетную ссылку для использования API. Мы исправим это в Command-Query Responsibility Segregation (CQRS)[1]. |
Мы также меняем отдельные HANDLERS на словарь для разных команд и событий. Команды могут иметь только один обработчик, согласно нашему соглашению:
EVENT_HANDLERS = {
events.OutOfStock: [handlers.send_out_of_stock_notification],
} # type: Dict[Type[events.Event], List[Callable]]
COMMAND_HANDLERS = {
commands.Allocate: handlers.allocate,
commands.CreateBatch: handlers.add_batch,
commands.ChangeBatchQuantity: handlers.change_batch_quantity,
} # type: Dict[Type[commands.Command], Callable]11.3. Обсуждение: Events, Commands, и Error Handling
Многие разработчики испытывают дискомфорт в этот момент и спрашивают: "Что произойдёт, когда событие не получиться обработать?
Как мне понять, что система находится в консистентном состоянии?" Если нам удастся обработать половину событий во время messagebus.handle прежде чем ошибка нехватки памяти убьет наш процесс, как мы можем сгладить проблемы, вызванные потерянными сообщениями?
Начнем с наихудшего случая: мы не справляемся с событием, и система остается в противоречивом состоянии. Какая ошибка могла бы вызвать это? Часто в наших системах мы можем оказаться в несогласованном состоянии, когда завершена только половина операции.
Например, представим, что мы выделили три единицы DESIRABLE_BEANBAG для какого то заказа клиента, но почему-то не смогли уменьшить количество оставшихся запасов. Это привело бы к несогласованному состоянию: три единицы запаса одновременно распределены и доступны, в зависимости от того, с какой стороны на это посмотреть. Позже мы могли бы выделить те же самые BEANBAG-и другому клиенту, что вызвало бы головную боль у службы поддержки клиентов.
Однако в нашей службе распределения мы уже предприняли шаги для предотвращения такой ситуации. Мы тщательно определили aggregates, которые действуют как границы согласованности, и ввели UoW, который управляет атомарным успехом или неудачей обновления агрегата.
For example, when we allocate stock to an order, our consistency boundary is the Product aggregate. This means that we can’t accidentally overallocate: either a particular order line is allocated to the product, or it is not—there’s no room for inconsistent states.
Например, когда мы распределяем запасы по заказу, нашей границей согласованности является агрегат Product. Это означает, что мы не можем случайно распределить: либо конкретная строка заказа выделяется продукту, либо нет — другого не дано, ибо нет места для несогласованных состояний.
По определению, мы не требуем, чтобы два агрегата были немедленно согласованы, поэтому, если мы не сможем обработать событие и обновить только один агрегат, наша система все равно может быть в конечном итоге согласована. Мы не должны нарушать никаких ограничений системы.
Разбирая этот пример, мы можем лучше понять причину разделения сообщений на команды и события. Когда пользователь хочет заставить систему что-то сделать, мы представляем его запрос как команду. Эта команда должна изменить один aggregate и либо преуспеть, либо потерпеть неудачу в целом. Любая другая бухгалтерия, очистка и уведомление, которые нам нужно сделать, могут происходить через event. Мы не требуем, чтобы обработчики событий были успешными, чтобы команда была успешной.
Давайте рассмотрим другой пример (из другого, воображаемого проекта), чтобы понять, почему нет.
Представьте себе, что мы создаем интернет-магазин, который продает дорогие предметы роскоши. Наш отдел маркетинга желает вознаграждать клиентов за повторные визиты. Мы будем отмечать клиентов как VIP-персон после того, как они совершат свою третью покупку, и это даст им право на приоритетное обслуживание и специальные предложения. Наши критерии принятия этой истории гласят следующее:
Учитывать клиента с двумя заказами в истории и когда клиент размещает третий заказ, то он должен быть помечен как VIP.
Когда клиент впервые становится VIP-персоной, мы должны отправить ему электронное письмо с поздравлением
Используя методы, которые мы уже обсуждали в этой книге, мы решаем, что хотим создать новый агрегат History, который записывает заказы и может вызывать события домена при выполнении правил. Мы будем структурировать код следующим образом:
class History: # Aggregate
def __init__(self, customer_id: int):
self.orders = set() # Set[HistoryEntry]
self.customer_id = customer_id
def record_order(self, order_id: str, order_amount: int): (1)
entry = HistoryEntry(order_id, order_amount)
if entry in self.orders:
return
self.orders.add(entry)
if len(self.orders) == 3:
self.events.append(
CustomerBecameVIP(self.customer_id)
)
def create_order_from_basket(uow, cmd: CreateOrder): (2)
with uow:
order = Order.from_basket(cmd.customer_id, cmd.basket_items)
uow.orders.add(order)
uow.commit() # raises OrderCreated
def update_customer_history(uow, event: OrderCreated): (3)
with uow:
history = uow.order_history.get(event.customer_id)
history.record_order(event.order_id, event.order_amount)
uow.commit() # raises CustomerBecameVIP
def congratulate_vip_customer(uow, event: CustomerBecameVip): (4)
with uow:
customer = uow.customers.get(event.customer_id)
email.send(
customer.email_address,
f'Congratulations {customer.first_name}!'
)| 1 | Агрегат History фиксирует правила, указывающие, когда клиент становится VIP-персоной. Это особенно станет заметным, когда в будущем правила станут более сложными для внесения изменениий. |
| 2 | Наш первый хандлер создает заказ для клиента и вызывает доменное событие OrderCreated. |
| 3 | Второй обновляет объект History, чтобы записать, что заказ был created. |
| 4 | Наконец, мы отправляем электронное письмо клиенту, когда он становится VIP-персоной. |
Используя этот код, мы можем получить некоторое представление об обработке ошибок в системе, управляемой событиями.
В нашей текущей реализации события агрегата, которые сохраняют наше состояние в базе данных, вызываем после. Что если бы мы подняли эти события, прежде чем сохранились, и зафиксировали все наши изменения одновременно? Таким образом, мы можем быть уверены, что вся работа завершена. Разве это не безопаснее?
Однако что происходит, если почтовый сервер немного перегружен? Если вся работа должна быть завершена одновременно, занятый почтовый сервер может помешать нам принимать оплату за заказы.
Что произойдет, если в реализации агрегата History есть ошибка?
Неужели мы откажемся от ваших денег только потому, что не можем признать вас VIP-персоной?
Разделив эти пересекающиеся задачи, мы тем самым изолировали выходы из строя, что повышает общую надежность системы. Единственная часть этого кода, которую необходимо выполнить, - это обработчик команды, создания заказа. Это единственная часть, которая заботит покупателя, и это та часть, которую наши участники проекта должны расставить по приоритетам.
Обратите внимание, как мы намеренно выровняли наши транзакционные границы с началом и концом бизнес-процессов. Имена, которые мы используем в коде, соответствуют жаргону, используемому нашими заинтересованными сторонами в бизнесе, а обработчики, которые мы написали, соответствуют шагам наших критериев выбора естественного языка. Такое соответствие имен и структур помогает нам рассуждать о наших системах по мере того, как они становятся все больше и сложнее.
11.4. Синхронное восстановление после ошибок
Hopefully we’ve convinced you that it’s OK for events to fail independently from the commands that raised them. What should we do, then, to make sure we can recover from errors when they inevitably occur? Надеюсь, мы были достаточно убедительны показывая, что события могут завершиться неудачей независимо от команд, которые их вызвали. Что же нам тогда делать, чтобы убедиться, что мы можем оправиться от ошибок, когда они неизбежно произойдут?
Первое, что нам нужно, - это знать, когда произошла ошибка, и для этого мы обычно полагаемся на лог-файлы.
Давайте еще раз рассмотрим метод handle_event из нашей шины сообщений:
def handle_event(
event: events.Event,
queue: List[Message],
uow: unit_of_work.AbstractUnitOfWork
):
for handler in EVENT_HANDLERS[type(event)]:
try:
logger.debug('handling event %s with handler %s', event, handler)
handler(event, uow=uow)
queue.extend(uow.collect_new_events())
except Exception:
logger.exception('Exception handling event %s', event)
continueКогда мы обрабатываем сообщение в нашей системе, первое, что мы делаем, - это записываем строку лога, для фиксации того, что мы собираемся сделать. Для нашего варианта использования CustomerBecameVIP журналы могут выглядеть следующим образом:
Handling event CustomerBecameVIP(customer_id=12345) with handler <function congratulate_vip_customer at 0x10ebc9a60>
Because we’ve chosen to use dataclasses for our message types, we get a neatly printed summary of the incoming data that we can copy and paste into a Python shell to re-create the object. Поскольку мы решили использовать классы данных (dataclasses) для наших типов сообщений (message types), мы получаем аккуратно напечатанную сводку входящих данных, которую мы можем скопировать и вставить в оболочку Python для повторного создания объекта.
Когда возникает ошибка, мы можем использовать зарегистрированные данные, чтобы либо воспроизвести проблему в модульном тесте, либо воспроизвести сообщение в системе.
Ручной повтор хорошо работает в тех случаях, когда нам нужно исправить ошибку, прежде чем мы сможем повторно обработать событие, но наши системы всегда будут подвержены фоновым помехам переходного уровня. Это включает в себя такие вещи, как сбои сети, взаимоблокировки таблиц и кратковременные паузы, вызванные развертываниями.
В большинстве этих случаев мы можем элегантно восстановиться, попробовав еще раз. Как гласит пословица: "Если сначала у вас ничего не получится, повторите операцию с экспоненциально увеличивающимся периодом ожидания."
from tenacity import Retrying, RetryError, stop_after_attempt, wait_exponential (1)
...
def handle_event(
event: events.Event,
queue: List[Message],
uow: unit_of_work.AbstractUnitOfWork
):
for handler in EVENT_HANDLERS[type(event)]:
try:
for attempt in Retrying( (2)
stop=stop_after_attempt(3),
wait=wait_exponential()
):
with attempt:
logger.debug('handling event %s with handler %s', event, handler)
handler(event, uow=uow)
queue.extend(uow.collect_new_events())
except RetryError as retry_failure:
logger.error(
'Failed to handle event %s times, giving up!',
retry_failure.last_attempt.attempt_number
)
continue| 1 | Tenacity-это библиотека Python, которая реализует общие шаблоны для повторных попыток. |
| 2 | Здесь мы настраиваем нашу шину сообщений для повторения операций до трех раз с экспоненциально увеличивающейся паузой между попытками. |
Повторные вызовы операций, которые могут потерпеть неудачу, - это, вероятно, единственный лучший способ повысить устойчивость нашего программного обеспечения. Опять же, шаблоны Unit of Work и Command Handler означают, что каждая попытка начинается с согласованного состояния и не оставит выполнение заданий наполовину законченными.
В какой-то момент, независимо от tenacity, нам придется отказаться от попыток обработать сообщение.
Строить надежные системы с распределенными сообщениями непросто, и нам приходится пропускать некоторые сложные моменты. Поэтому, будет полезно изучить дополнительные справочные материалы в epilogue.
|
11.5. Подведение итогов
В этой книге мы решили представить концепцию событий до концепции команд, но другие руководства часто делают это наоборот. Сделать явными запросы, на которые наша система может ответить, дав им имя и их собственную структуру данных, - это довольно фундаментальная вещь. Иногда вы заметите, как используется шаблон Command Handler для описания того, что мы делаем с Events, Commands, и Message Bus.
Разделение команд и событий: компромиссы обсуждает некоторые моменты, о которых вам следует подумать, прежде чем запрыгивать на борт.
| Плюсы | Минусы |
|---|---|
|
|
В Event-Driven Architecture: Использование событий для интеграции микросервисов мы поговорим об использовании событий в качестве шаблона интеграции.
12. Event-Driven Architecture: Использование событий для интеграции микросервисов
В предыдущей главе мы как то промолчали о том, как мы получим события «измененного количества партий», или, по сути, как мы можем уведомить внешний мир о перераспределении.
У нас есть микросервис с веб-API, но как насчет других способов общения с другими системами? Как мы узнаем, если, скажем, отгрузка задерживается или количество изменяется? Как мы сообщим складской системе, что заказ распределен и должен быть отправлен клиенту?
В этой главе мы хотели бы показать, как метафора events может быть расширена, чтобы охватить способ обработки входящих и исходящих сообщений из системы. Внутренне ядро нашего приложения теперь процессор сообщений. Давайте проследим за тем, чтобы он также стал обработчиком внешних сообщений. Как показано в Наше приложение является процессором сообщений, наше приложение будет получать события из внешних источников через внешнюю шину сообщений (в качестве примера мы будем использовать очереди Redis pub/sub) и публиковать свои выходные данные в виде событий там же.
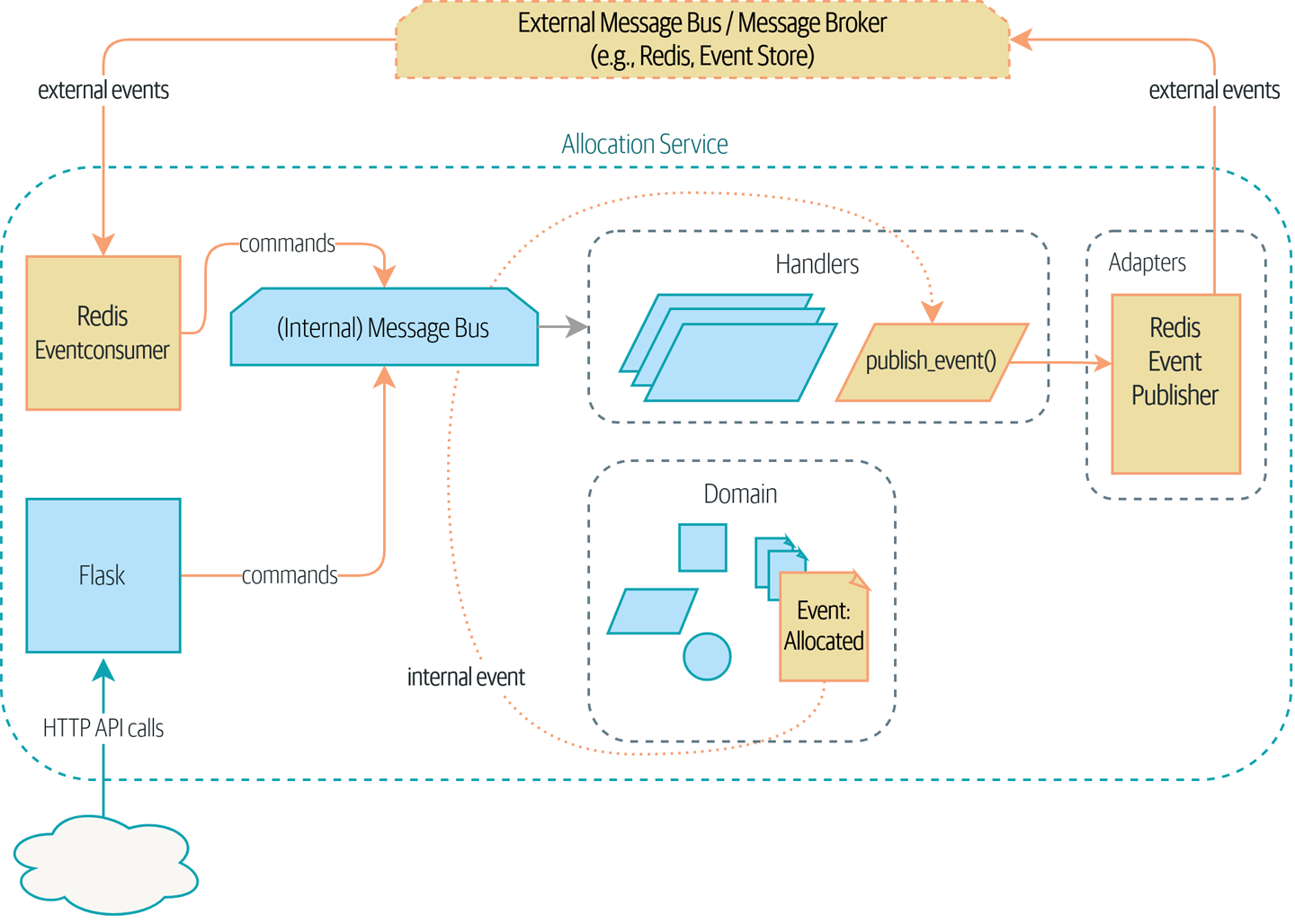
|
Код для этой главы находится в ветви chapter_11_external_events on GitHub: git clone https://github.com/cosmicpython/code.git cd code git checkout chapter_11_external_events # или, чтобы кодить вместе, проверьте предыдущую главу: git checkout chapter_10_commands |
12.1. Distributed Ball of Mud, и мыслим в существительных
Прежде чем мы двинем дальше, давайте поговорим об альтернативах. Мы регулярно общаемся с инженерами, которые пытаются создать архитектуру микросервисов. Часто они мигрируют из существующего приложения, и их первый инстинкт состоит в том, чтобы разделить свою систему на существительные.
Какие существительные мы уже ввели в нашу систему? Ну, у нас есть партии(batches) товара(stock), заказов(orders), продуктов(products) и клиентов(customers). Таким образом, наивная попытка разрушить систему могла бы выглядеть следующим образом Context diagram with noun-based services (обратите внимание, что мы назвали нашу систему в честь существительного Партии(Batches), а не Распределение(Allocation)).
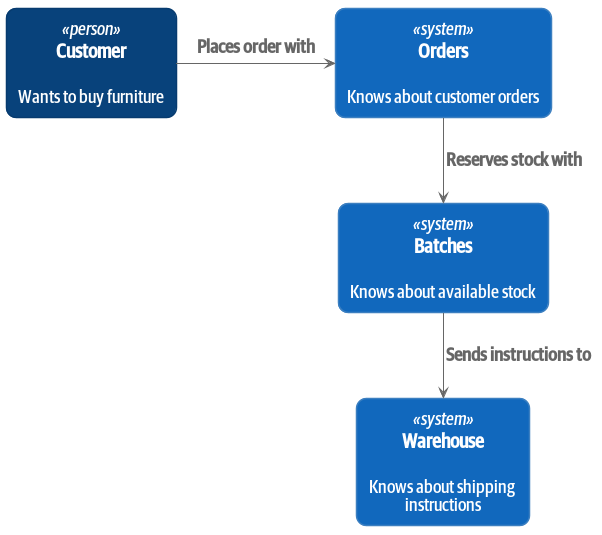
[plantuml, apwp_1102, config=plantuml.cfg] @startuml Batches Context Diagram !include images/C4_Context.puml System(batches, "Batches", "Knows about available stock""Знает об имеющихся запасах") Person(customer, "Customer", "Wants to buy furniture""Хочет купить мебель") System(orders, "Orders", "Knows about customer orders""Знает о заказах клиентов") System(warehouse, "Warehouse", "Knows about shipping instructions""Знает об инструкциях по доставке") Rel_R(customer, orders, "Places order with""Размещает заказ с") Rel_D(orders, batches, "Reserves stock with""Резервирует запасы с") Rel_D(batches, warehouse, "Sends instructions to""Посылает инструкции") @enduml
Каждая "Штуковина" в нашей системе имеет связанную службу, которая предоставляет HTTP API.
Давайте рассмотрим пример happy-path в Поток Команд 1.: наши пользователи посещают веб - сайт и могут выбирать из продуктов, которые есть на складе. Когда они добавят товар в свою корзину, мы зарезервируем для них некоторый запас. Когда заказ завершен, мы подтверждаем бронирование, что заставляет нас отправлять инструкции по отправке на склад. Допустим, к примеру, если это третий заказ клиента, то надо обновить запись клиента, чтобы отметить его как VIP-персону.
[plantuml, apwp_1103, config=plantuml.cfg] @startuml scale 4 actor Customer entity Orders entity Batches entity Warehouse database CRM == Reservation(Бронирование) == Customer -> Orders: Add product to basket (Добавляет товар в корзину) Orders -> Batches: Reserve stock (Резервирует запас) == Purchase(Закупка) == Customer -> Orders: Place order(Размещает заказ) activate Orders Orders -> Batches: Confirm reservation(Подтверждает бронирование) Batches -> Warehouse: Dispatch goods(Отправляет товары) Orders -> CRM: Update customer record(Обновляет запись клиента) deactivate Orders @enduml
Мы можем рассматривать каждый из этих шагов как команду в нашей системе: ReserveStock, ConfirmReservation, DispatchGoods, MakeCustomerVIP, и так далее.
Этот стиль архитектуры, в котором мы создаем микросервисы для каждой таблицы базы данных и рассматриваем наши HTTP-API как интерфейсы CRUD для анемичных моделей, является наиболее распространенным первоначальным способом для людей подойти к сервис-ориентированному дизайну.
Это прекрасно работает для очень простых систем, но может быстро превратиться в distributed ball of mud(расползающийся ком грязи).
Чтобы понять почему, давайте рассмотрим другой случай. Иногда, когда товар поступает на склад, мы обнаруживаем, что товары были повреждены водой во время транспортировки. Мы не можем продавать поврежденные водой диваны, поэтому нам приходится выбрасывать их и запрашивать больше запасов у наших партнеров. Нам также необходимо обновить нашу модель запасов, и это может означать, что нам нужно перераспределить заказ клиента.
Куда ведет эта логика?
Ну, система складского учёта знает, что запас был поврежден, поэтому, возможно, она должна владеть этим процессом, как показано на рисунке. Поток команд 2.
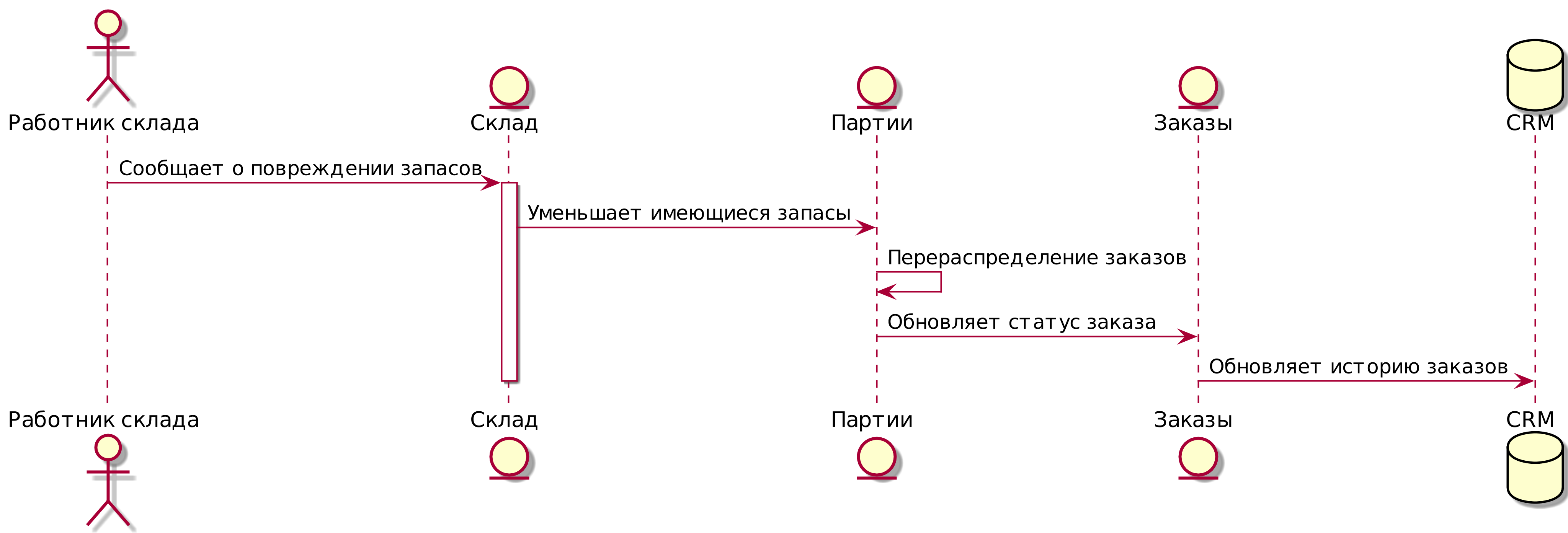
[plantuml, apwp_1104, config=plantuml.cfg] @startuml scale 4 actor w as "Warehouse worker" entity Warehouse entity Batches entity Orders database CRM w -> Warehouse: Report stock damage activate Warehouse Warehouse -> Batches: Decrease available stock Batches -> Batches: Reallocate orders Batches -> Orders: Update order status Orders -> CRM: Update order history deactivate Warehouse @enduml
Это тоже работает, но теперь наш график зависимостей в беспорядке. Для распределения запасов служба заказов(Orders service) управляет системой Партий(Batches system), которая управляет Складом(Warehouse); но для решения проблем на складе наша складская система(Warehouse system) управляет партиями(Batches), которые управляют Заказами(Orders).
Умножьте это на все другие рабочие процессы, которые нам нужно обеспечить, и вы увидите, как быстро запутываются службы.
12.2. Обработка ошибок в распределенных системах
"Вещи ломаются" - это универсальный закон разработки программного обеспечения. Что происходит в нашей системе, когда один из наших запросов терпит неудачу? Предположим, что сетевая ошибка происходит сразу после того, как мы принимаем заказ пользователя на три MISBEGOTTEN-RUG, как показано на рисунке
Поток команд с ошибкой.
У нас есть два варианта: мы можем разместить заказ в любом случае и оставить его нераспределенным(unallocated), или мы можем отказаться принять заказ, потому что распределение не может быть гарантировано. Резко всплывший сбой в работе нашей службы обработки партий оказывает критическое влияние на надежность нашей службы заказов.
Когда две хреновины должны быть изменены вместе, мы говорим, что они связанны coupled. Мы можем рассматривать этот каскад сбоев как своего рода временную связанность temporal coupling: все части системы должны работать одновременно, чтобы обеспечить работоспособность каждой в отдельности. По мере того как система становится больше, вероятность того, что какая-то часть деградирует, экспоненциально возрастает.
[plantuml, apwp_1105, config=plantuml.cfg] @startuml scale 4 actor Customer entity Orders entity Batches Customer -> Orders: Place order(Разместить заказ) Orders -[#red]x Batches: Confirm reservation(Подтвердить бронирование) hnote right: network error(ошибка сети) Orders --> Customer: ??? @enduml
12.3. Альтернатива: Временное Разъединение(Декаплинг) С Использованием Асинхронного Обмена Сообщениями
Как нам получить соответствующую связь? Мы уже видели часть ответа, которая заключается в том, что мы должны думать в терминах глаголов, а не существительных. Наша модель предметной области посвящена моделированию бизнес-процесса. Это не статическая модель данных о чём то таком; это модель глагола.
Поэтому вместо того, чтобы думать о системе для заказов и системе для партий, мы думаем о системе для ordering и системе для allocating и так далее.
Когда мы разделим вещи таким образом, станет немного легче понять, какая система за что должна отвечать. Когда мы думаем о ordering, на самом деле мы хотим убедиться, что, когда мы размещаем заказ, заказ размещен. Все остальное может случиться позже, как только удачно случится это.
| Если это звучит знакомо, то так и должно быть! Разделение ответственности - это тот же процесс, через который мы прошли при разработке наших агрегатов и команд. |
Как и агрегаты, микросервисы должны быть консистентными границами. Между двумя службами мы можем принять возможную согласованность, и это означает, что нам не нужно полагаться на синхронные вызовы. Каждая служба принимает команды из внешнего мира и создает события для записи результата. Другие службы могут прослушивать(listen) эти события, чтобы инициировать следующие шаги в рабочем процессе.
Чтобы избежать неприятностей в виде Distributed Ball of Mud, вместо временно связанных вызовов HTTP API мы будем использовать асинхронный обмен сообщениями для интеграции наших систем.
Нам надо, чтобы наши сообщения BatchQuantityChanged поступали как внешние сообщения из вышестоящих систем, и мы хотим, чтобы наша система публиковала события Allocated для прослушивания нижестоящими системами.
Почему так лучше? Во-первых, поскольку все вещи могут выходить из строя независимо друг от друга, то легче справиться с ухудшением поведения: мы все еще можем принимать заказы, если у системы распределения плохой день.
Во-вторых, мы уменьшаем силу связи между нашими системами. Если нам нужно изменить порядок операций или ввести новые этапы в процесс, мы можем сделать это на месте.
12.4. Использование канала Redis Pub/Sub для интеграции
Давайте посмотрим конкретно, как все это будет работать. Нам понадобится какой-то способ получения событий из одной системы в другую, подобно нашей шине сообщений, но для сервисов. Этот элемент инфраструктуры часто называют message broker. Роль брокера сообщений заключается в том, чтобы принимать сообщения от издателей и доставлять их подписчикам.
На сайте MADE.com мы используем Event Store; Kafka или RabbitMQ являются достойными альтернативами. Легкое решение на основе Redis pub/sub channels также может прекрасно работать, и поскольку Redis гораздо более привычен для большинства программистов, мы решили использовать его в этой книге.
| Мы упускаем из виду сложность, связанную с выбором правильной платформы для обмена сообщениями. Необходимо продумать такие вопросы, как упорядочение сообщений, обработка отказов и идемпотентность. Несколько советов см. Footguns. |
Наш новый поток будет выглядеть следующим образом Диаграмма последовательности для потока перераспределения:
Redis предоставляет событие BatchQuantityChanged, которое запускает весь процесс, а наше событие Allocated снова публикуется в Redis в конце.
[plantuml, apwp_1106, config=plantuml.cfg]
@startuml
scale 4
Redis -> MessageBus : BatchQuantityChanged event
group BatchQuantityChanged Handler + Unit of Work 1
MessageBus -> Domain_Model : change batch quantity
Domain_Model -> MessageBus : emit Allocate command(s)
end
group Allocate Handler + Unit of Work 2 (or more)
MessageBus -> Domain_Model : allocate
Domain_Model -> MessageBus : emit Allocated event(s)
end
MessageBus -> Redis : publish to line_allocated channel
@enduml
12.5. Тест-Драйв всего этого с использованием Сквозного теста
Вот как мы можем начать со сквозного тестирования. Мы можем использовать наш существующий API для создания пакетов, а затем протестируем входящие и исходящие сообщения:
def test_change_batch_quantity_leading_to_reallocation():
# начать с двух партий и заказа, выделенного для одной из них (1)
orderid, sku = random_orderid(), random_sku()
earlier_batch, later_batch = random_batchref('old'), random_batchref('newer')
api_client.post_to_add_batch(earlier_batch, sku, qty=10, eta='2011-01-01') (2)
api_client.post_to_add_batch(later_batch, sku, qty=10, eta='2011-01-02')
response = api_client.post_to_allocate(orderid, sku, 10) (2)
assert response.json()['batchref'] == earlier_batch
subscription = redis_client.subscribe_to('line_allocated') (3)
# изменить количество выделенной партии так, чтобы оно было меньше нашего заказа (1)
redis_client.publish_message('change_batch_quantity', { (3)
'batchref': earlier_batch, 'qty': 5
})
# подождать, пока не появится сообщение о том, что заказ был перераспределен (1)
messages = []
for attempt in Retrying(stop=stop_after_delay(3), reraise=True): (4)
with attempt:
message = subscription.get_message(timeout=1)
if message:
messages.append(message)
print(messages)
data = json.loads(messages[-1]['data'])
assert data['orderid'] == orderid
assert data['batchref'] == later_batch| 1 | То, что происходит в этом месте, понятно из комментариев: мы хотим отправить в систему событие, которое вызывает перераспределение строки заказа, и мы видим, что это перераспределение также появляется как событие в Redis. |
| 2 | api_client - это маленький помощник, который мы отрефакторили для совместного использования двумя типами тестов; он оборачивает наши вызовы к requests.post. |
| 3 | redis_client - это еще один маленький помощник в тестировании, детали которого не имеют особого значения; его задача заключается в том, чтобы иметь возможность отправлять и получать сообщения из различных каналов Redis. Мы будем использовать канал под названием change_batch_quantity для отправки запроса на изменение количества для партии, и мы будем слушать другой канал под названием line_allocated для поиска ожидаемого перераспределения. |
| 4 | Из-за асинхронной природы тестируемой системы нам нужно снова использовать библиотеку tenacity, чтобы добавить цикл повтора - во-первых, потому что может пройти некоторое время, пока наше новое сообщение line_allocated придет, а также потому, что это будет не единственное сообщение на этом канале. |
12.5.1. Redis - еще один тонкий адаптер вокруг нашей шины сообщений
Наш слушатель(listener) Redis pub/sub (мы называем его потребитель событий) очень похож на Flask: он транслируется из внешнего мира в наши события:
r = redis.Redis(**config.get_redis_host_and_port())
def main():
orm.start_mappers()
pubsub = r.pubsub(ignore_subscribe_messages=True)
pubsub.subscribe('change_batch_quantity') (1)
for m in pubsub.listen():
handle_change_batch_quantity(m)
def handle_change_batch_quantity(m):
logging.debug('handling %s', m)
data = json.loads(m['data']) (2)
cmd = commands.ChangeBatchQuantity(ref=data['batchref'], qty=data['qty']) (2)
messagebus.handle(cmd, uow=unit_of_work.SqlAlchemyUnitOfWork())| 1 | main() подписывает нас на канал change_batch_quantity при загрузке. |
| 2 | Наша основная задача как точки входа в систему - десериализовать JSON, преобразовать его в Command и передать его сервисному уровню - так же, как это делает адаптер Flask. |
Мы также создаем новый адаптер для выполнения противоположной задачи - преобразования событий домена в публичные события:
r = redis.Redis(**config.get_redis_host_and_port())
def publish(channel, event: events.Event): (1)
logging.debug('publishing: channel=%s, event=%s', channel, event)
r.publish(channel, json.dumps(asdict(event)))| 1 | Здесь мы используем жестко заданный канал, но вы также можете хранить связку между classes/names событий и соответствующим каналом, позволяя одному или нескольким типам сообщений отправляться на разные каналы. |
12.5.2. Наше новое выездное мероприятие
Вот как будет выглядеть событие Allocated:
@dataclass
class Allocated(Event):
orderid: str
sku: str
qty: int
batchref: strВ нем содержится все, что нам нужно знать о распределении: сведения о строке заказа и о том, для какой партии он был выделен.
Мы добавляем его в метод allocate() нашей модели (предварительно добавив тест, естественно):
class Product:
...
def allocate(self, line: OrderLine) -> str:
...
batch.allocate(line)
self.version_number += 1
self.events.append(events.Allocated(
orderid=line.orderid, sku=line.sku, qty=line.qty,
batchref=batch.reference,
))
return batch.reference
Обработчик для ChangeBatchQuantity уже существует, поэтому все, что нам нужно добавить, это обработчик, который публикует исходящее событие:
HANDLERS = {
events.Allocated: [handlers.publish_allocated_event],
events.OutOfStock: [handlers.send_out_of_stock_notification],
} # type: Dict[Type[events.Event], List[Callable]]Для публикации события используется наша вспомогательная функция из обертки Redis:
def publish_allocated_event(
event: events.Allocated, uow: unit_of_work.AbstractUnitOfWork,
):
redis_eventpublisher.publish('line_allocated', event)12.6. Внутренние и внешние события
Хорошо, если различие между внутренними и внешними событиями будет четким. Некоторые события могут приходить извне, а некоторые события могут обновляться и публиковаться извне, но не все будут таковыми. Это особенно важно, если вы попадаете в event sourcing (хотя это очень подходящая тема для другой книги).
| Исходящие события — это одно из мест, где важно применять валидацию. См. Validation для ознакомления с некоторой философией валидации и примеры. |
12.7. Подведение итогов
События могут приходить _из_вне, но они также могут быть опубликованы извне - наш обработчик publish преобразует событие в сообщение на канале Redis. Мы используем события для общения с внешним миром. Такая временная развязка обеспечивает нам большую гибкость в интеграции приложений, но, как всегда, за это приходится платить.
Уведомление о событиях хорошо тем, что оно подразумевает низкий уровень связи и довольно просто настраивается. Однако это может стать проблематичным, если действительно существует логический поток, который проходит через различные уведомления о событиях... Такой поток может быть трудно увидеть, поскольку он не выражен явно в тексте программы.... Это может затруднить отладку и модификацию.
Martin Fowler, "What do you mean by 'Event-Driven'"
Интеграция микросервисов на основе событий: компромиссы показывает некоторые компромиссы, о которых стоит подумать.
| Плюсы | Минусы |
|---|---|
|
|
В более общем случае, если вы переходите от модели синхронного обмена сообщениями к асинхронному, вы также открываете целый ряд проблем, связанных с надежностью и эвентуальной консистентностью сообщений. Читать далее Footguns.
13. Command-Query Responsibility Segregation (CQRS)[1]
В этой главе мы начнем с довольно бесспорного понимания: чтение (queries) и запись (commands) различны, поэтому к ним следует относиться по-разному (или разделять их обязанности, если хотите). Затем мы собираемся продвинуть это понимание как можно дальше.
Если вы хоть немного похожи на Гарри, то поначалу все это покажется экстремальным, но, надеюсь, мы сможем доказать, что это не так уж страшно.
Отделение чтения от записи показывает, где мы можем оказаться.
|
Код для этой главы находится в ветке chapter_12_cqrs on GitHub. git clone https://github.com/cosmicpython/code.git cd code git checkout chapter_12_cqrs # или, чтобы кодить вместе, вспомните предыдущую главу: git checkout chapter_11_external_events |
Во-первых, хотя, зачем беспокоиться?
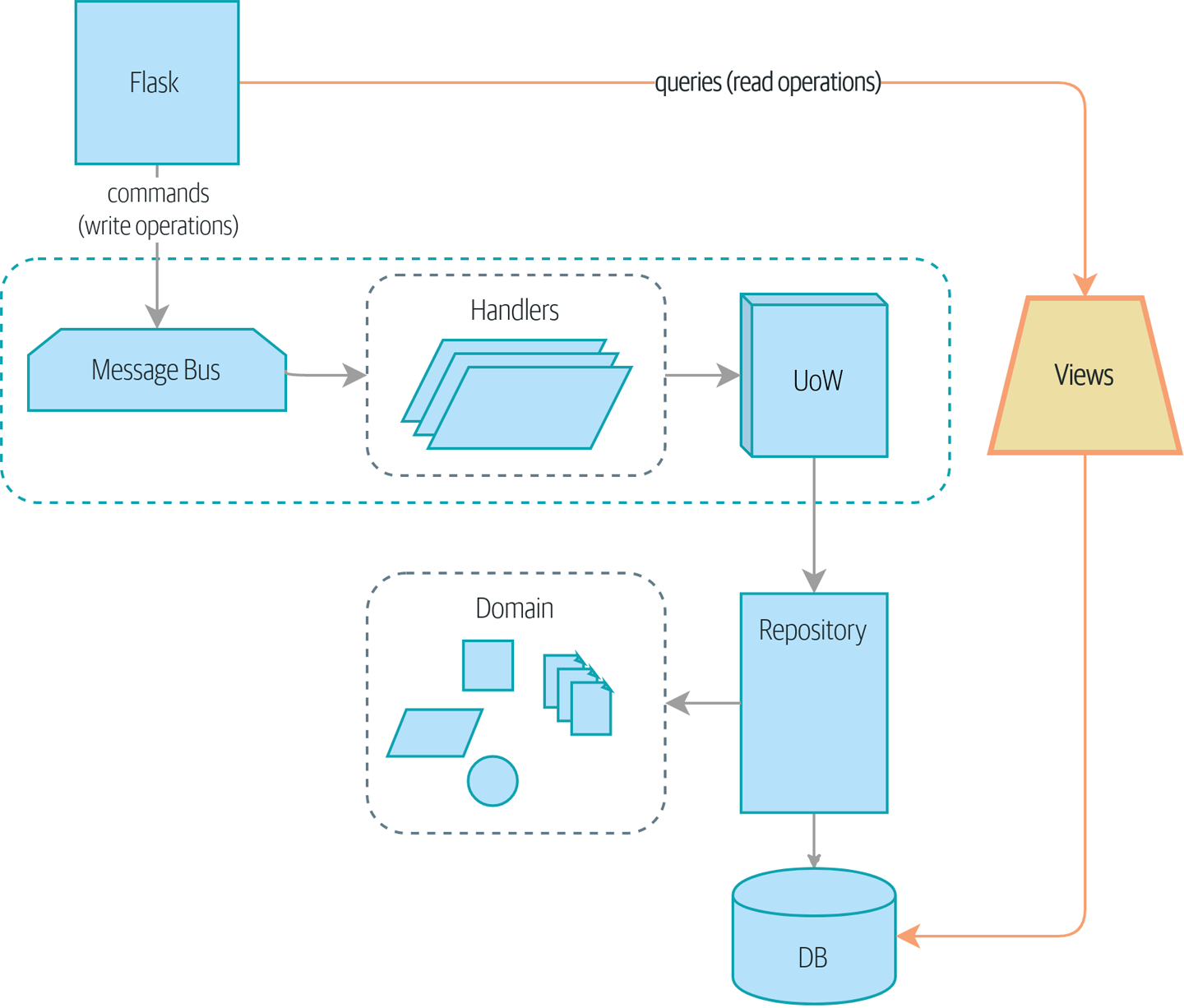
13.1. Domain Models предназначены для Writing
Мы потратили много времени в этой книге, рассказывая о том, как создавать программное обеспечение, обеспечивающее соблюдение правил нашего домена. Эти правила, или ограничения, будут разными для каждого приложения, и они составляют ключевое ядро наших систем.
В этой книге мы установили явные ограничения, такие как "Вы не можете выделить больше запасов, чем имеется в наличии". а также неявные ограничения типа "Каждая строка заказа распределяется на одну партию".
В начале книги мы записали эти правила в виде юнит-тестов:
def test_allocating_to_a_batch_reduces_the_available_quantity():
batch = Batch("batch-001", "SMALL-TABLE", qty=20, eta=date.today())
line = OrderLine('order-ref', "SMALL-TABLE", 2)
batch.allocate(line)
assert batch.available_quantity == 18
...
def test_cannot_allocate_if_available_smaller_than_required():
small_batch, large_line = make_batch_and_line("ELEGANT-LAMP", 2, 20)
assert small_batch.can_allocate(large_line) is FalseЧтобы правильно применять эти правила, нам нужно было обеспечить последовательность операций, поэтому мы ввели такие шаблоны, как Unit of Work и Aggregate, которые помогают нам фиксировать небольшие фрагменты работы.
Для передачи изменений между этими небольшими частями мы ввели шаблон Domain Events, чтобы мы могли писать правила типа "Когда запасы повреждены или потеряны, скорректируйте доступное количество в партии и при необходимости перераспределите заказы".
Вся эта сложность существует для того, чтобы мы могли применять правила при изменении состояния нашей системы. Мы создали гибкий набор инструментов для записи данных.
А как насчет чтения?
13.2. Большинство Пользователей не собираются покупать Вашу Мебель
На MADE.com действует система, очень похожая на службу распределения. В напряженный день мы можем обработать сто заказов в течение часа, и у нас есть большая сложная система распределения запасов по этим заказам.
Однако в тот же самый напряженный день у нас может быть сто просмотров товара в секунду. Каждый раз, когда кто-то заходит на страницу товара или страницу листинга товара, нам необходимо выяснить, есть ли этот товар на складе и сколько времени нам потребуется, чтобы его доставить.
Область domain та же самая — мы имеем дело с партиями запасов, датой их прибытия и количеством, которое еще доступно - но схема доступа совсем другая. Например, наши клиенты не заметят, если запрос устарел на несколько секунд, но если наша служба allocate работает непоследовательно, мы устроим бардак в их заказах. Мы можем воспользоваться этой разницей, сделав наши чтения эвентуально консистентными, чтобы они получше работали.
Мы можем думать об этих требованиях как о двух половинах системы: стороне чтения и стороне записи, показанных в Чтение против записи.
Для стороны записи наши причудливые архитектурные паттерны домена помогают нам развивать нашу систему с течением времени, но сложность, которую мы создали до сих пор, ничего не дает для чтения данных. service layer, unit of work и clever domain model - это просто раздутая структура.
| Сторона чтения | Сторона записи | |
|---|---|---|
Behavior(Поведение) |
Простое чтение |
Сложная бизнес-логика |
Cacheability(Кэшируемость) |
Сильно кэшируемый |
Не кэшируемый |
Consistency(Консистентность) |
Может быть устаревшим |
Должен быть транзакционно последовательным |
13.3. Post/Redirect/Get и CQS
Если вы занимаетесь веб-разработкой, вы наверняка знакомы с шаблоном Post/Redirect/Get. В этой технике конечная веб-точка принимает HTTP POST и отвечает перенаправлением для просмотра результата. Например, мы можем принять POST на /batches для создания новой партии и перенаправить пользователя на /batches/123 для просмотра только что созданной партии.
Этот подход устраняет проблемы, возникающие, когда пользователи обновляют страницу результатов в браузере или пытаются добавить страницу результатов в закладки. В случае обновления, это может привести к тому, что наши пользователи дважды отправят данные и, таким образом, купят два дивана, когда им нужен был только один. В случае с закладкой наши незадачливые клиенты получат неработающую страницу при попытке получить конечную точку POST.
Обе эти проблемы возникают потому, что мы возвращаем данные в ответ на операцию записи. Post/Redirect/Get обходит эту проблему стороной, разделяя фазы чтения и записи нашей операции.
Эта техника является простым примером разделения команд и запросов (CQS).[36] Мы следуем одному простому правилу: Функции должны либо изменять состояние, либо отвечать на вопросы, но никогда и то, и другое. Это делает программное обеспечение более легким для рассуждений: мы всегда должны иметь возможность спросить: "Включен ли свет?". не щелкая выключателем.
| При создании API мы можем применить ту же технику проектирования, возвращая файл 201 Created, или 202 Accepted, с заголовком Location, содержащим URI наших новых ресурсов. Здесь важен не код статуса, который мы используем. но логическое разделение работы на фазу записи и фазу запроса. |
Как вы увидите, мы можем использовать принцип CQS, чтобы сделать наши системы более быстрыми и масштабируемыми, но сначала давайте исправим нарушение CQS в нашем существующем коде. Давным-давно мы ввели конечную точку allocate, которая принимает заказ и вызывает наш сервисный уровень для выделения некоторого запаса. В конце вызова мы возвращаем 200 OK и идентификатор партии. Это привело к некоторым уродливым недостаткам дизайна, чтобы мы могли получить нужные нам данные. Давайте изменим его, чтобы он возвращал простое сообщение OK, и вместо этого предоставим новую конечную точку, доступную только для чтения, для получения состояния распределения(allocation):
@pytest.mark.usefixtures('postgres_db')
@pytest.mark.usefixtures('restart_api')
def test_happy_path_returns_202_and_batch_is_allocated():
orderid = random_orderid()
sku, othersku = random_sku(), random_sku('other')
earlybatch = random_batchref(1)
laterbatch = random_batchref(2)
otherbatch = random_batchref(3)
api_client.post_to_add_batch(laterbatch, sku, 100, '2011-01-02')
api_client.post_to_add_batch(earlybatch, sku, 100, '2011-01-01')
api_client.post_to_add_batch(otherbatch, othersku, 100, None)
r = api_client.post_to_allocate(orderid, sku, qty=3)
assert r.status_code == 202
r = api_client.get_allocation(orderid)
assert r.ok
assert r.json() == [
{'sku': sku, 'batchref': earlybatch},
]
@pytest.mark.usefixtures('postgres_db')
@pytest.mark.usefixtures('restart_api')
def test_unhappy_path_returns_400_and_error_message():
unknown_sku, orderid = random_sku(), random_orderid()
r = api_client.post_to_allocate(
orderid, unknown_sku, qty=20, expect_success=False,
)
assert r.status_code == 400
assert r.json()['message'] == f'Invalid sku {unknown_sku}'
r = api_client.get_allocation(orderid)
assert r.status_code == 404OK, как может выглядеть приложение Flask?
from allocation import views
...
@app.route("/allocations/<orderid>", methods=['GET'])
def allocations_view_endpoint(orderid):
uow = unit_of_work.SqlAlchemyUnitOfWork()
result = views.allocations(orderid, uow) (1)
if not result:
return 'not found', 404
return jsonify(result), 200| 1 | Отлично! views.py, вполне справедливо; мы можем держать там всякие разные штуки только для чтения, и это будет настоящий views.py, не такой, как у Django, что-то, что знает, как строить представления наших данных только для чтения… |
13.4. Держите свой обед, ребята
Хм, так что мы, вероятно, можем просто добавить метод списка в наш существующий объект репозитория:
from allocation.service_layer import unit_of_work
def allocations(orderid: str, uow: unit_of_work.SqlAlchemyUnitOfWork):
with uow:
results = list(uow.session.execute(
'SELECT ol.sku, b.reference'
' FROM allocations AS a'
' JOIN batches AS b ON a.batch_id = b.id'
' JOIN order_lines AS ol ON a.orderline_id = ol.id'
' WHERE ol.orderid = :orderid',
dict(orderid=orderid)
))
return [{'sku': sku, 'batchref': batchref} for sku, batchref in results]Простите? Необработанный SQL?
Если вы похожи на Гарри, впервые столкнувшегося с этой моделью, вам будет интересно, что же такое курил Боб. Сейчас мы вручную обрабатываем наш собственный SQL, и преобразуем строки базы данных непосредственно в dicts? После всех усилий, которые мы приложили для создания хорошей модели домена? А как насчет паттерна Repository? Разве это не должно быть нашей абстракцией вокруг базы данных? Почему бы нам не использовать его повторно?
Что ж, давайте сначала изучим эту, казалось бы, более простую альтернативу и посмотрим, как она выглядит на практике.
Мы по-прежнему будем хранить наше представление в отдельном модуле views.py; обеспечение четкого разграничения между чтением и записью в вашем приложении по-прежнему является хорошей идеей. Мы применяем разделение команд и запросов, и легко понять, какой код изменяет состояние (обработчики событий - event handlers), а какой просто получает состояние только для чтения (представления - views).
| Разделение представлений, доступных только для чтения, и обработчиков команд и событий, изменяющих состояние, вероятно, хорошая идея, даже если вы не хотите переходить на полноценный CQRS. |
13.5. Тестирование представлений CQRS
Прежде чем перейти к изучению различных вариантов, давайте поговорим о тестировании. Какой бы подход вы ни выбрали, вам наверняка понадобится хотя бы один интеграционный тест. Что-то вроде этого:
def test_allocations_view(sqlite_session_factory):
uow = unit_of_work.SqlAlchemyUnitOfWork(sqlite_session_factory)
messagebus.handle(commands.CreateBatch('sku1batch', 'sku1', 50, None), uow) (1)
messagebus.handle(commands.CreateBatch('sku2batch', 'sku2', 50, today), uow)
messagebus.handle(commands.Allocate('order1', 'sku1', 20), uow)
messagebus.handle(commands.Allocate('order1', 'sku2', 20), uow)
# добавляем ложную партию и заказываем, чтобы убедиться, что мы получаем правильные партии
messagebus.handle(commands.CreateBatch('sku1batch-later', 'sku1', 50, today), uow)
messagebus.handle(commands.Allocate('otherorder', 'sku1', 30), uow)
messagebus.handle(commands.Allocate('otherorder', 'sku2', 10), uow)
assert views.allocations('order1', uow) == [
{'sku': 'sku1', 'batchref': 'sku1batch'},
{'sku': 'sku2', 'batchref': 'sku2batch'},
]| 1 | Мы выполняем настройку интеграционного теста с помощью public entrypoint в наше приложение-message bus. Это позволяет отделить наши тесты от любых деталей реализации/инфраструктуры того, как вещи хранятся. |
13.6. "Obvious" Alternative 1: Using the Existing Repository
Как насчет добавления вспомогательного метода в repository products?
from allocation import unit_of_work
def allocations(orderid: str, uow: unit_of_work.AbstractUnitOfWork):
with uow:
products = uow.products.for_order(orderid=orderid) (1)
batches = [b for p in products for b in p.batches] (2)
return [
{'sku': b.sku, 'batchref': b.reference}
for b in batches
if orderid in b.orderids (3)
]| 1 | Наше хранилище возвращает объекты Product, и нам нужно найти все продукты для SKU в данном заказе, поэтому мы создадим новый вспомогательный метод .for_order() для хранилища. |
| 2 | Теперь у нас есть продукты, но на самом деле нам нужны ссылки на партии, поэтому мы получаем все возможные партии с помощью восприятия списка. |
| 3 | Мы фильтруем еще раз, чтобы получить только партии для нашего конкретного заказа. Это, в свою очередь, зависит от того, смогут ли наши объекты Batch сообщить нам, какие идентификаторы заказов они выделили. |
Последнее мы реализуем с помощью свойства .orderid:
class Batch:
...
@property
def orderids(self):
return {l.orderid for l in self._allocations}Вы можете заметить, что повторное использование существующих классов хранилища и доменной модели не так просто, как вы могли предположить. Нам пришлось добавить новые вспомогательные методы для обоих, и мы выполняем кучу циклов и фильтрации в Python, что является работой, которую гораздо эффективнее выполнять с помощью базы данных.
Так что да, с одной стороны, мы используем существующие абстракции, но с другой стороны, все это кажется довольно громоздким.
13.7. Ваша модель домена не оптимизирована для операций чтения
Здесь мы видим последствия того, что модель домена разработана в основном для операций записи, в то время как наши требования к чтению часто концептуально совершенно другие.
Это оправдание архитектора, поглаживающего окладистую бороду, касательно CQR. Как мы уже говорили, модель домена - это не модель данных, мы пытаемся отразить то, как работает бизнес: рабочий процесс, правила изменения состояния, обмен сообщениями; озабоченность тем, как система реагирует на внешние события и пользовательский ввод. Большая часть этих штуковин совершенно не важна для операций read-only.
| Это обоснование для CQR связано с обоснованием шаблона модели предметной области. Если вы создаете простое CRUD-приложение, чтение и запись будут тесно связаны между собой, поэтому вам не нужна модель домена или CQRS. Но чем сложнее ваш домен, тем больше вероятность, что вам понадобится и то, и другое. |
Говоря проще, ваши доменные классы будут иметь множество методов для изменения состояния, и ни один из них вам не понадобится для операций только для чтения.
По мере роста сложности вашей доменной модели вы будете делать всё больше и больше выборов в отношении того, как структурировать эту модель, что сделает её все более и более неудобной для использования в операциях чтения.
13.8. "Очевидная" Альтернатива 2: Использование ORM
Вас может посетить мысль: "Хорошо, если наш репозиторий такой косой, и работа с Products такая кривая, то я могу, по крайней мере, использовать мой ORM и работать с Batches.
Вот для чего это нужно!"
from allocation import unit_of_work, model
def allocations(orderid: str, uow: unit_of_work.AbstractUnitOfWork):
with uow:
batches = uow.session.query(model.Batch).join(
model.OrderLine, model.Batch._allocations
).filter(
model.OrderLine.orderid == orderid
)
return [
{'sku': b.sku, 'batchref': b.batchref}
for b in batches
]Но разве это действительно легче написать или понять, чем необработанную версию SQL из примера кода в Держите свой обед, ребята? Возможно, с виду все выглядит не так уж плохо, но скажем вам по секрету, что это заняло несколько попыток и много копаний в документации по SQLAlchemy. SQL - это просто SQL.
Но ORM также может привести к проблемам с производительностью.
13.9. SELECT N+1 и другие соображения по производительности
Так называемый SELECT N+1
problem is a common performance problem with ORMs: when retrieving a list of objects, your ORM will often perform an initial query to, say, get all the IDs of the objects it needs, and then issue individual queries for each object to retrieve their attributes. This is especially likely if there are any foreign-key relationships on your objects.
проблема является общей проблемой производительности ORM: при получении списка объектов ваш ORM часто будет выполнять начальный запрос, чтобы, скажем, получить все идентификаторы нужных ему объектов, а затем выдавать отдельные запросы для каждого объекта, чтобы получить их атрибуты. Это особенно вероятно, если в ваших объектах есть какие-либо связи с внешними ключами(foreign-key).
Справедливости ради следует сказать, что SQLAlchemy неплохо справляется с проблемой SELECT N+1. В предыдущем примере он не отображается, и вы можете явно запросить принудительную загрузку, чтобы избежать этого при работе с объединенными объектами.
|
Помимо SELECT N+1, у вас могут быть и другие причины для того, чтобы разделить способ сохранения изменений состояния и способ получения текущего состояния. Набор полностью нормализованных реляционных таблиц - это хороший способ убедиться, что операции записи никогда не приведут к повреждению данных. Но получение данных с помощью множества объединений может быть медленным. В таких случаях обычно добавляют некоторые денормализованные представления, создают реплики для чтения или даже добавляют уровни кэширования.
13.10. Время полностью Jump the Shark[1]
На этой ноте: Убедили ли мы вас, что наша версия необработанного SQL не такая уж странная, как кажется на первый взгляд? Возможно, мы преувеличивали ради эффекта? Подожди.
Итак, разумно или нет, но этот жестко закодированный SQL-запрос довольно уродлив, верно? Что если мы сделаем его посимпатичнее…
def allocations(orderid: str, uow: unit_of_work.SqlAlchemyUnitOfWork):
with uow:
results = list(uow.session.execute(
'SELECT sku, batchref FROM allocations_view WHERE orderid = :orderid',
dict(orderid=orderid)
))
...…путем сохранения совершенно отдельного, денормализованного хранилища данных для нашей модели представления?
allocations_view = Table(
'allocations_view', metadata,
Column('orderid', String(255)),
Column('sku', String(255)),
Column('batchref', String(255)),
)Конечно, более красивые SQL-запросы не могут служить оправданием для чего-либо, но создание денормализованной копии данных, оптимизированной для операций чтения, не является редкостью, как только вы достигли пределов возможностей индексов.
Даже с хорошо настроенными индексами реляционная база данных использует много CPU для выполнения соединений. Самые быстрые запросы всегда будут проходить:[<code>SELECT * from <em>mytable</em> WHERE <em>key</em> = :<em>value</em></code>].
Однако этот подход покупает нам не только скорость, но и масштаб. Когда мы записываем данные в реляционную базу данных, нам нужно убедиться, что мы получаем блокировку изменяемых строк, чтобы не столкнуться с проблемами согласованности.
Если несколько клиентов изменяют данные одновременно, мы получим странные условия гонки. Однако, когда мы читаем данные, то количество клиентов, которые могут одновременно выполнять операции, не ограничено. По этой причине хранилища только для чтения можно масштабировать горизонтально.
| Поскольку реплики чтения могут быть непоследовательными, нет предела тому, сколько их может быть. Если вам трудно масштабировать систему со сложным хранилищем данных, поинтересуйтесь, можно ли построить более простую модель чтения. |
Поддерживать модель чтения в актуальном состоянии - вот в чем сложность! Представления базы данных (материализованные или иные) и триггеры являются распространенным решением, но это ограничивает вас вашей базой данных. Мы хотели бы показать вам, как можно использовать нашу событийно-управляемую архитектуру вместо этого.
13.10.1. Обновление Read Model Table с помощью Event Handler
Мы добавляем второй обработчик к событию Allocated:
EVENT_HANDLERS = {
events.Allocated: [
handlers.publish_allocated_event,
handlers.add_allocation_to_read_model
],Вот как выглядит наш код update-view-model:
def add_allocation_to_read_model(
event: events.Allocated, uow: unit_of_work.SqlAlchemyUnitOfWork,
):
with uow:
uow.session.execute(
'INSERT INTO allocations_view (orderid, sku, batchref)'
' VALUES (:orderid, :sku, :batchref)',
dict(orderid=event.orderid, sku=event.sku, batchref=event.batchref)
)
uow.commit()Хотите верьте, хотите нет, но это вполне сработает! И он будет работать с теми же интеграционными тестами, что и остальные наши варианты.
OK, вам также нужно будет обрабатывать Deallocated:
events.Deallocated: [
handlers.remove_allocation_from_read_model,
handlers.reallocate
],
...
def remove_allocation_from_read_model(
event: events.Deallocated, uow: unit_of_work.SqlAlchemyUnitOfWork,
):
with uow:
uow.session.execute(
'DELETE FROM allocations_view '
' WHERE orderid = :orderid AND sku = :sku',Диаграмма последовательностей для модели чтения показывает поток между двумя запросами.
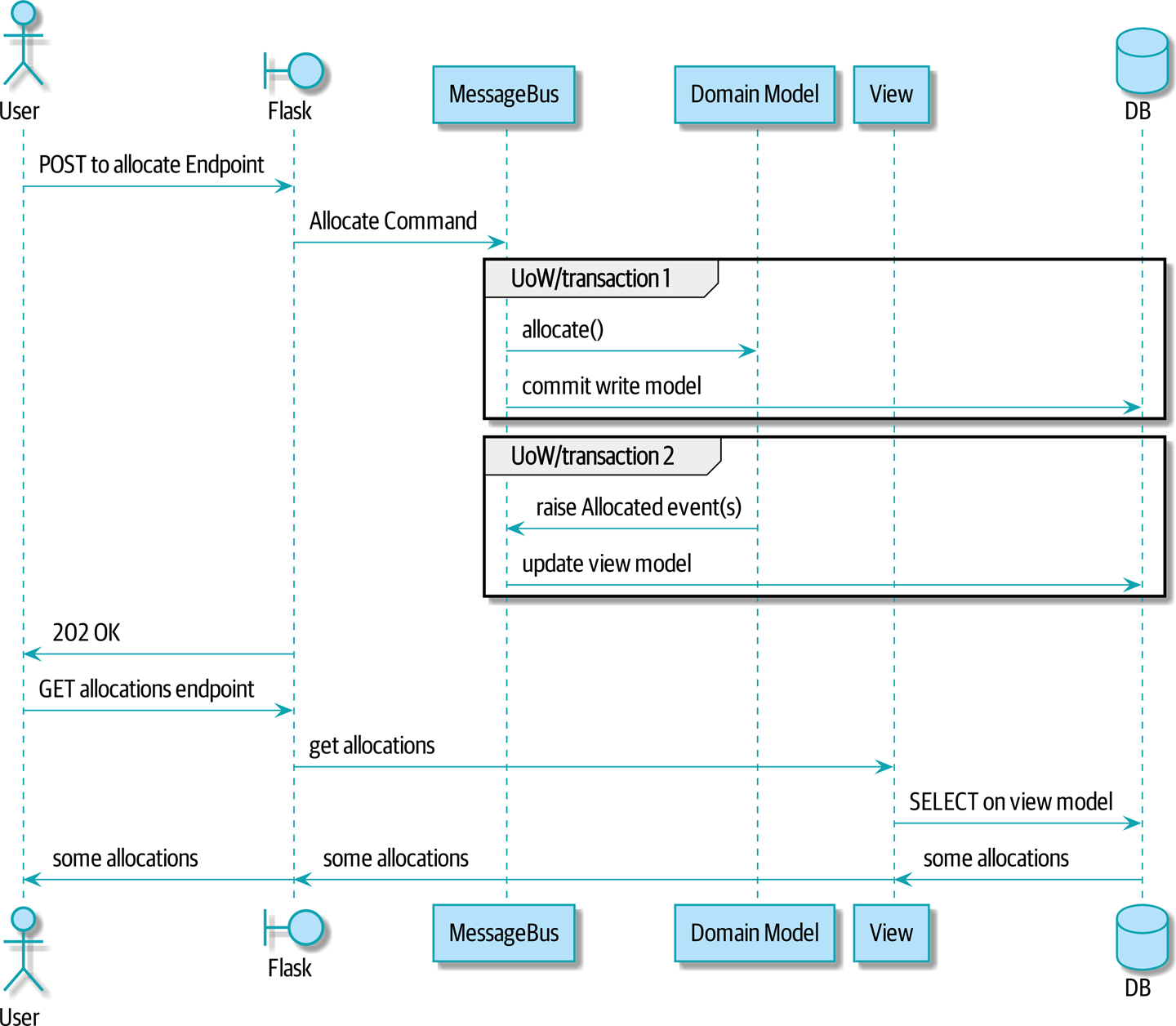
[plantuml, apwp_1202, config=plantuml.cfg]
@startuml
scale 4
!pragma teoz true
actor User order 1
boundary Flask order 2
participant MessageBus order 3
participant "Domain Model" as Domain order 4
participant View order 9
database DB order 10
User -> Flask: POST to allocate Endpoint
Flask -> MessageBus : Allocate Command
group UoW/transaction 1
MessageBus -> Domain : allocate()
MessageBus -> DB: commit write model
end
group UoW/transaction 2
Domain -> MessageBus : raise Allocated event(s)
MessageBus -> DB : update view model
end
Flask -> User: 202 OK
User -> Flask: GET allocations endpoint
Flask -> View: get allocations
View -> DB: SELECT on view model
DB -> View: some allocations
& View -> Flask: some allocations
& Flask -> User: some allocations
@enduml
В Диаграмма последовательностей для модели чтения можно увидеть две транзакции в операции POST/write, одна для обновления модели записи, другая для обновления модели чтения, которую может использовать операция GET/read.
13.11. Изменить нашу реализацию Read Model очень просто
Давайте посмотрим на гибкость, которую дает нам наша событийно-ориентированная модель, в действии, увидев, что произойдет, если мы когда-нибудь решим, что хотим реализовать модель чтения, используя совершенно отдельный механизм хранения данных, Redis.
Просто смотрите:
def add_allocation_to_read_model(event: events.Allocated, _):
redis_eventpublisher.update_readmodel(event.orderid, event.sku, event.batchref)
def remove_allocation_from_read_model(event: events.Deallocated, _):
redis_eventpublisher.update_readmodel(event.orderid, event.sku, None)The helpers in our Redis module are one-liners:
def update_readmodel(orderid, sku, batchref):
r.hset(orderid, sku, batchref)
def get_readmodel(orderid):
return r.hgetall(orderid)(Возможно, название redis_eventpublisher.py сейчас звучит неправильно, но вы поняли идею.)
И сам вид меняется очень незначительно, чтобы адаптироваться к новому бэкенду:
def allocations(orderid):
batches = redis_eventpublisher.get_readmodel(orderid)
return [
{'batchref': b.decode(), 'sku': s.decode()}
for s, b in batches.items()
]И такие же интеграционные тесты, которые были у нас раньше, все еще проходят, потому что они написаны на уровне абстракции, отделенном от реализации: setup помещает сообщения на шину сообщений, и утверждения(assertions) противоречат нашему представлению (view).
| Обработчики событий - это отличный способ управления обновлениями модели чтения, если вы решите, что она вам нужна. Они также позволяют легко изменить реализацию этой модели чтения впоследствии. |
13.12. Подведение итогов
Компромиссы различных вариантов модели представления предлагает несколько плюсов и минусов для каждого из вариантов.
Так получилось, что служба распределения на MADE.com действительно использует "полномасштабный" сервис. CQRS, с моделью чтения, хранящейся в Redis, и даже вторым уровнем кэша, обеспечиваемым Varnish. Но его применение значительно отличается от того, что мы показали здесь. Для сервиса распределения, который мы создаем, кажется маловероятным, что вам понадобится использовать отдельную модель чтения и обработчики событий для ее обновления.
Но по мере того, как ваша доменная модель становится все богаче и сложнее, упрощенная модель чтения становится все более убедительной.
| Вариант | Плюсы | Минусы |
|---|---|---|
Просто используйте репозитории |
Простой, последовательный подход. |
Ожидайте проблем с производительностью при сложных шаблонах запросов. |
Использование пользовательских запросов в ORM |
Позволяет повторно использовать конфигурацию БД и определения моделей. |
Добавляет еще один язык запросов со своими причудами и синтаксисом. |
Используйте ручной SQL для запросов к обычным таблицам модели |
Предлагает тонкий контроль над производительностью с помощью стандартного синтаксиса запросов. |
Изменения в схеме БД должны быть внесены в ваши ручные запросы и ваши Определения ORM. Высоко нормализованные схемы все еще могут иметь производительность ограничения. |
Добавьте несколько дополнительных (денормализованных) таблиц в вашу БД в качестве модели чтения |
Денормализованная таблица может быть намного быстрее в запросе. Если мы обновим нормализованные и денормализованные в одной транзакции, мы будем все еще имеют хорошие гарантии согласованности данных |
Это немного замедлит процесс записи |
Создание отдельных хранилищ для чтения с помощью событий |
Копии только для чтения легко масштабировать. Представления могут быть построены, когда данные изменения, чтобы запросы были как можно более простыми. |
Сложная техника. Гарри навсегда останется недоверчивым к твоим вкусам и мотивы. |
Часто ваши операции чтения будут действовать на те же концептуальные объекты, что и ваша модель записи, поэтому использование ORM, добавление некоторых методов чтения в ваши хранилища и использование классов доменной модели для ваших операций чтения - это просто прекрасно.
В нашем примере с книгой операции чтения действуют на совершенно другие концептуальные сущности, чем в нашей модели домена. Служба распределения думает в терминах партий для одного SKU, но пользователи заботятся о распределении для всего заказа, с несколькими SKU, поэтому использование ORM оказывается немного неудобным. У нас был бы большой соблазн использовать представление raw-SQL, которое мы показали в начале главы.
На этой ноте давайте приступим к нашей последней главе.
14. Dependency Injection (и Bootstrapping)
В мире Python к инъекции зависимостей (DI) относятся с подозрением. И до сих пор мы прекрасно обходились без этого в примерах кода для этой книги!
В этой главе мы рассмотрим некоторые болевые точки в нашем коде, которые заставили нас задуматься об использовании DI, и представим несколько вариантов того, как это сделать, оставляя за вами право выбрать тот, который вы считаете наиболее питоническим.
Мы также добавим в нашу архитектуру новый компонент под названием bootstrap.py; он будет отвечать за внедрение зависимостей, а также за некоторые другие вещи инициализации, которые нам часто нужны. Мы объясним, почему такого рода вещи называются композиционным корнем в языках OO, и почему _bootstrap script отлично подходит для наших целей.
Без бутстрапа: точки входа делают многое показывает, как выглядит наше приложение без бутстраппера: точки входа выполняют много инициализации и передачи нашей основной зависимости, UoW.
|
Если вы этого еще не сделали, то перед продолжением этой главы стоит прочитать Краткая интерлюдия: О Связях и Абстракции, особенно обсуждение функционального и объектно-ориентированного управления зависимостями. |
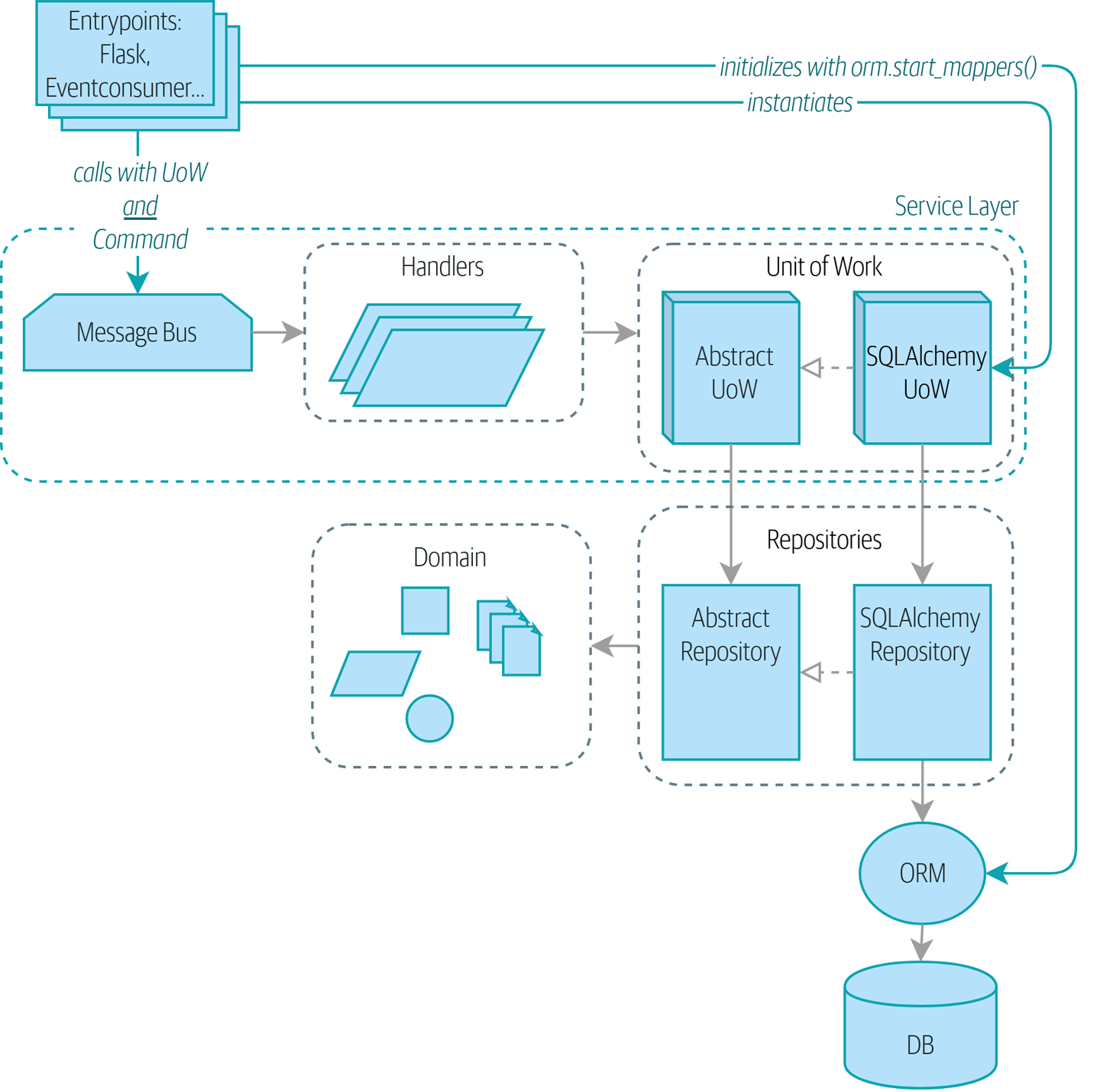
|
Код для этой главы находится в ветке chapter_13_dependency_injection on GitHub: git clone https://github.com/cosmicpython/code.git cd code git checkout chapter_13_dependency_injection # или, чтобы кодить вместе, вспомните предыдущую главу: git checkout chapter_12_cqrs |
Bootstrap позаботится обо всем этом в одном месте показывает, как наш бутстраппер берет на себя эти обязанности.
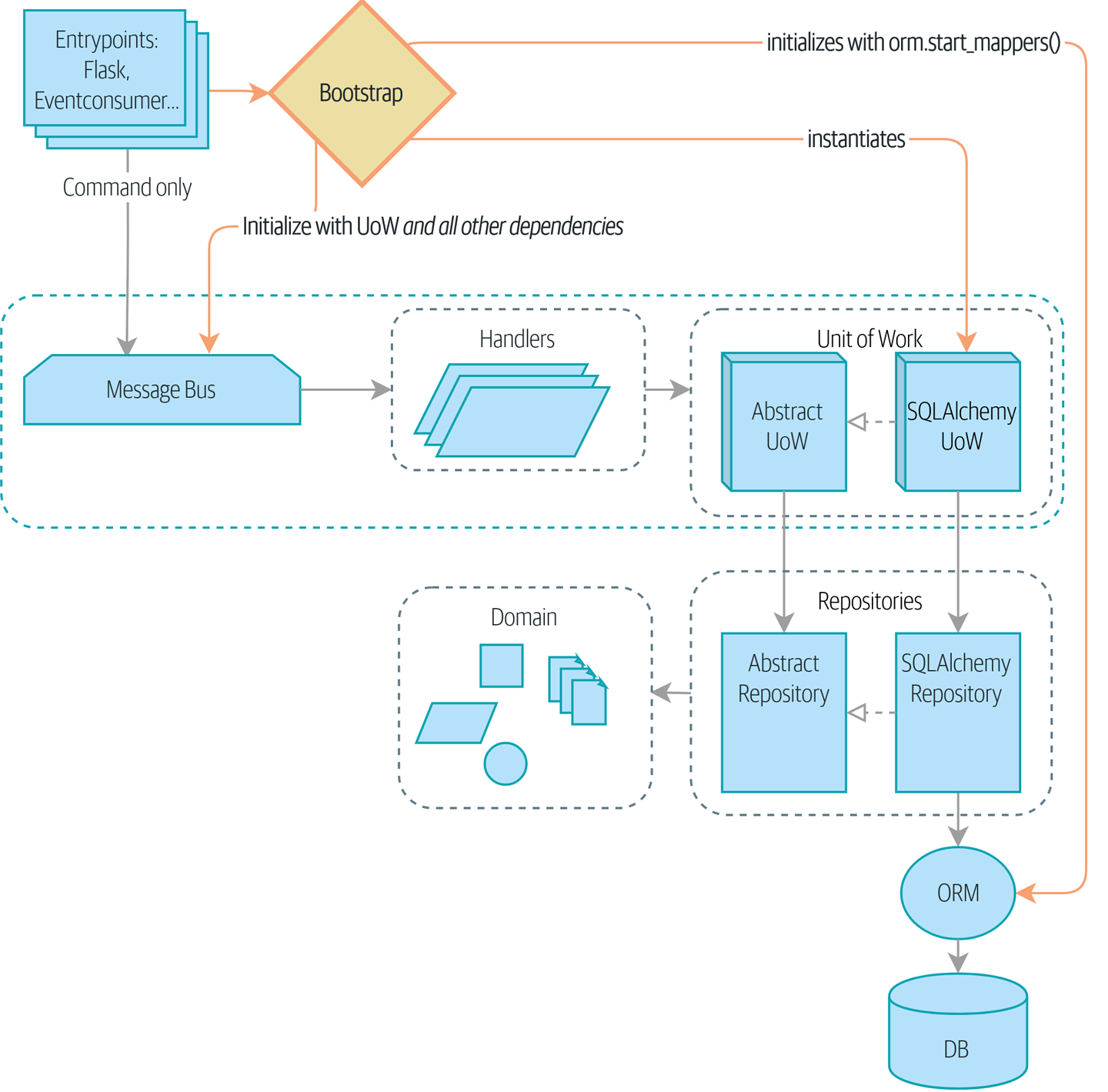
14.1. Неявные и явные зависимости
В зависимости от ваших конкретных "тараканов в голове", в этот момент у вас может возникнуть легкое чувство тревоги на задворках сознания. Давайте вынесем это на всеобщее обозрение. Мы показали вам два способа управления зависимостями и их тестирования.
Для нашей зависимости от базы данных мы создали тщательную структуру явных зависимостей и простых вариантов их переопределения в тестах. Наши основные функции-обработчики декларируют явную зависимость от UoW:
def allocate(
cmd: commands.Allocate, uow: unit_of_work.AbstractUnitOfWork
):И это позволяет легко подменить фейковый UoW в наших тестах сервисного уровня:
uow = FakeUnitOfWork()
messagebus.handle([...], uow)Сам UoW декларирует явную зависимость от фабрики сессий:
class SqlAlchemyUnitOfWork(AbstractUnitOfWork):
def __init__(self, session_factory=DEFAULT_SESSION_FACTORY):
self.session_factory = session_factory
...Мы используем это преимущество в наших интеграционных тестах, чтобы иметь возможность иногда использовать SQLite вместо Postgres:
def test_rolls_back_uncommitted_work_by_default(sqlite_session_factory):
uow = unit_of_work.SqlAlchemyUnitOfWork(sqlite_session_factory) (1)| 1 | Интеграционные тесты заменяют стандартный Postgres session_factory на SQLite. |
14.2. Разве явные зависимости не являются совершенно странными и Java-выми?
Если вы привыкли к тому, как все обычно происходит в Python, вам покажется, что все это немного странно. Стандартный способ сделать это - объявить нашу зависимость неявно, просто импортировав ее, а затем, если нам когда-нибудь понадобится изменить ее для тестов, мы можем сделать monkeypatch, как это правильно и верно в динамических языках:
from allocation.adapters import email, redis_eventpublisher (1)
...
def send_out_of_stock_notification(
event: events.OutOfStock, uow: unit_of_work.AbstractUnitOfWork,
):
email.send( (2)
'stock@made.com',
f'Out of stock for {event.sku}',
)| 1 | Захардкоженный импорт |
| 2 | Вызывает конкретного отправителя электронной почты напрямую |
Зачем загрязнять код приложения ненужными аргументами только ради тестов? mock.patch позволяет легко и просто выполнять обезьянье сопряжение:
with mock.patch("allocation.adapters.email.send") as mock_send_mail:
...Проблема в том, что мы упростили задачу, потому что наш игрушечный пример не отправляет реальную почту (email.send_mail просто выполняет print), но в реальной жизни вам пришлось бы вызывать mock.patch для каждого теста, который может вызвать уведомление о нехватке товара. Если вы работали над кодовыми базами с большим количеством моков, используемых для предотвращения нежелательных побочных эффектов, вы знаете, насколько раздражающим становится этот кодовый шаблон.
И вы знаете, что моделирование жестко связывает нас с реализацией. Выбрав monkeypatch email.send_mail, мы привязаны к выполнению import email, и если мы когда-нибудь захотим сделать from email import send_mail, что является тривиальным рефактором, нам придется изменить все наши mocks.
Так что это компромисс. Да, объявление явных зависимостей, строго говоря, не нужно, и их использование незначительно усложнило бы код нашего приложения. Но взамен мы получим тесты, которые легче писать и управлять ими.
Кроме того, объявление явной зависимости является примером принципа инверсии зависимости - вместо того, чтобы иметь (неявную) зависимость от конкретной детали, мы имеем (явную) зависимость от абстракции:
Явное лучше неявного.
def send_out_of_stock_notification(
event: events.OutOfStock, send_mail: Callable,
):
send_mail(
'stock@made.com',
f'Out of stock for {event.sku}',
)Но если мы перейдем к явному объявлению всех этих зависимостей, кто и как будет их внедрять? До сих пор мы действительно имели дело только с передачей UoW: наши тесты используют FakeUnitOfWork, в то время как точки входа Flask и Redis eventconsumer используют настоящие UoW, а шина сообщений передает их нашим обработчикам команд. Если мы добавим классы настоящих и фальшивых электронных адресов, кто будет их создавать и передавать?
Это должно происходить как можно раньше в жизненном цикле процесса, поэтому самое очевидное место - это наши точки входа. Это будет означать дополнительную (дублирующуюся) нагрузку на Flask и Redis, а также на наши тесты. Кроме того, нам пришлось бы возложить ответственность за передачу зависимостей на шину сообщений, у которой и так есть чем заняться; это похоже на нарушение SRP.[37]
Вместо этого мы обратимся к шаблону под названием Composition Root (для нас с вами - загрузочный скрипт),сноска:[Поскольку Python не является "чистым" ОО-язык, разработчики Python не всегда привыкли к концепции необходимости составить набор объектов в работающее приложение. Мы просто выбираем точку входа и выполняем код сверху вниз], и мы сделаем немного "ручного DI". (внедрение зависимостей без фреймворка). См. Bootstrapper между точками входа и шиной сообщений.сноска:[Марк Симанн называет это Pure DI или иногда Vanilla DI].

[ditaa, apwp_1303]
+---------------+
| Entrypoints |
| (Flask/Redis) |
+---------------+
|
| call
V
/--------------\
| | подготавливает обработчики с правильными зависимостями, инжектированными в
| Bootstrapper | (тестовый бутстраппер будет использовать фейки, а продакшн - настоящий)
| |
\--------------/
|
| передача инжектированных обработчиков в
V
/---------------\
| Message Bus |
+---------------+
|
| отправка события и команды в инжектированные обработчики
|
V
14.3. Подготовка обработчиков: Ручной DI с Closures(замыканиями) и Partials(Частично определенными функции)
Один из способов превратить функцию с зависимостями в функцию, готовую к последующему вызову с уже внедренными зависимостями, - использовать замыкания или частичные функции для компоновки функции с её зависимостями:
# existing allocate function, with abstract uow dependency
def allocate(
cmd: commands.Allocate, uow: unit_of_work.AbstractUnitOfWork
):
line = OrderLine(cmd.orderid, cmd.sku, cmd.qty)
with uow:
...
# скрипт bootstrap подготавливает реальный UoW
def bootstrap(..):
uow = unit_of_work.SqlAlchemyUnitOfWork()
# подготовить версию fn allocate с зависимостью UoW, зафиксированной в замыкании
allocate_composed = lambda cmd: allocate(cmd, uow)
# или, эквивалентно (при этом вы получите более красивую трассировку стека)
def allocate_composed(cmd):
return allocate(cmd, uow)
# альтернативно с partial
import functools
allocate_composed = functools.partial(allocate, uow=uow) (1)
# позже, во время выполнения, мы можем вызвать partial-функцию, и она будет иметь уже привязанную UoW
allocate_composed(cmd)| 1 | Разница между замыканиями (ламбдами или именованными функциями) и functools.partial заключается в том, что первые используют позднее связывание переменных, что может стать источником путаницы, если какая-либо из зависимостей является изменяемой.
|
Вот та же схема для обработчика send_out_of_stock_notification(), который имеет другие зависимости:
def send_out_of_stock_notification(
event: events.OutOfStock, send_mail: Callable,
):
send_mail(
'stock@made.com',
...
# подготовить версию уведомления send_out_of_stock_notification с зависимостями sosn_composed = lambda event: send_out_of_stock_notification(event, email.send_mail)
...
# позже, во время выполнения:
sosn_composed(event) # будет иметь email.send_mail, уже внедренный14.4. Альтернатива с использованием классов
Замыкания и Частично определенные функции покажутся знакомыми тем, кто немного занимался функциональным программированием. Вот альтернативный вариант с использованием классов, который может понравиться другим. Однако это требует переписать все наши функции-обработчики в виде классов:
# мы заменяем старый `def allocate(cmd, uow)` на:
class AllocateHandler:
def __init__(self, uow: unit_of_work.AbstractUnitOfWork): (2)
self.uow = uow
def __call__(self, cmd: commands.Allocate): (1)
line = OrderLine(cmd.orderid, cmd.sku, cmd.qty)
with self.uow:
# остальная часть метода обработчика как раньше
...
# сценарий bootstrap подготавливает реальный UoW
uow = unit_of_work.SqlAlchemyUnitOfWork()
# затем подготавливает версию fn allocate с уже внедренными зависимостями
allocate = AllocateHandler(uow)
...
# позже, во время выполнения, мы можем вызвать экземпляр обработчика, и в него уже будет внедрен UoW
allocate(cmd)| 1 | Класс предназначен для создания вызываемой функции, поэтому у него есть __call__ method. |
| 2 | Но мы используем init для объявления необходимых зависимостей. Подобные вещи покажутся вам знакомыми, если вы когда-либо создавали дескрипторы, основанные на классах, или контекстный менеджер, основанный на классах и принимающий аргументы. |
Используйте то, с чем вам и вашей команде удобнее работать.
14.5. Сценарий Bootstrap
Мы хотим, чтобы наш сценарий bootstrap выполнял следующие действия:
-
Объявите зависимости по умолчанию, но позвольте нам их переопределить
-
Сделайте "инициализацию", которая нам нужна для запуска нашего приложения
-
Внедрите все зависимости в наши обработчики
-
Верните нам основной объект для нашего приложения-шину сообщений
Вот первый разрез:
def bootstrap(
start_orm: bool = True, (1)
uow: unit_of_work.AbstractUnitOfWork = unit_of_work.SqlAlchemyUnitOfWork(), (2)
send_mail: Callable = email.send,
publish: Callable = redis_eventpublisher.publish,
) -> messagebus.MessageBus:
if start_orm:
orm.start_mappers() (1)
dependencies = {'uow': uow, 'send_mail': send_mail, 'publish': publish}
injected_event_handlers = { (3)
event_type: [
inject_dependencies(handler, dependencies)
for handler in event_handlers
]
for event_type, event_handlers in handlers.EVENT_HANDLERS.items()
}
injected_command_handlers = { (3)
command_type: inject_dependencies(handler, dependencies)
for command_type, handler in handlers.COMMAND_HANDLERS.items()
}
return messagebus.MessageBus( (4)
uow=uow,
event_handlers=injected_event_handlers,
command_handlers=injected_command_handlers,
)| 1 | orm.start_mappers() - это наш пример инициализации, которую необходимо выполнить один раз в начале работы приложения. Другим распространенным примером является настройка модуля logging.
|
| 2 | Мы можем использовать аргумент defaults, чтобы определить, какими будут normal/production значения по умолчанию. Хорошо иметь их в одном месте, но иногда зависимости имеют некоторые побочные эффекты во время конструирования, и в этом случае вы можете предпочесть вместо них значение по умолчанию None. |
| 3 | Мы создаем наши инжектированные версии связок обработчиков с помощью функции inject_dependencies(), которую мы покажем далее. |
| 4 | Мы возвращаем сконфигурированную шину сообщений, готовую к использованию. |
Вот как мы вводим зависимости в функцию обработчика, проверяя ее:
def inject_dependencies(handler, dependencies):
params = inspect.signature(handler).parameters (1)
deps = {
name: dependency
for name, dependency in dependencies.items() (2)
if name in params
}
return lambda message: handler(message, **deps) (3)| 1 | Мы проверяем аргументы нашего обработчика command/event. |
| 2 | Мы сопоставляем их по имени с нашими зависимостями. |
| 3 | Мы вводим их как kwargs для создания Частично определенной функции. |
14.6. Шина сообщений получает обработчики на этапе выполнения
Наша шина сообщений больше не будет статичной; она должна получить уже введенные обработчики. Таким образом, мы превращаем её из модуля в настраиваемый класс:
class MessageBus: (1)
def __init__(
self,
uow: unit_of_work.AbstractUnitOfWork,
event_handlers: Dict[Type[events.Event], List[Callable]], (2)
command_handlers: Dict[Type[commands.Command], Callable], (2)
):
self.uow = uow
self.event_handlers = event_handlers
self.command_handlers = command_handlers
def handle(self, message: Message): (3)
self.queue = [message] (4)
while self.queue:
message = self.queue.pop(0)
if isinstance(message, events.Event):
self.handle_event(message)
elif isinstance(message, commands.Command):
self.handle_command(message)
else:
raise Exception(f'{message} was not an Event or Command')| 1 | Шина сообщений становится классом… |
| 2 | …который получает свои уже инжектированные в зависимости обработчики. |
| 3 | Основная функция handle() по сути та же самая, только несколько атрибутов и методов перенесены на self. |
| 4 | Использование self.queue таким образом не является потокобезопасным, что может быть проблемой, если вы используете потоки, потому что экземпляр шины является глобальным в контексте приложения Flask, как мы и написали. Просто нужно быть начеку. |
Что еще меняется в …бусе?
def handle_event(self, event: events.Event):
for handler in self.event_handlers[type(event)]: (1)
try:
logger.debug('handling event %s with handler %s', event, handler)
handler(event) (2)
self.queue.extend(self.uow.collect_new_events())
except Exception:
logger.exception('Exception handling event %s', event)
continue
def handle_command(self, command: commands.Command):
logger.debug('handling command %s', command)
try:
handler = self.command_handlers[type(command)] (1)
handler(command) (2)
self.queue.extend(self.uow.collect_new_events())
except Exception:
logger.exception('Exception handling command %s', command)
raise| 1 | handle_event и handle_command по сути одно и то же, но вместо индексации в статической дикте EVENT_HANDLERS или COMMAND_HANDLERS они используют версии на self. |
| 2 | Вместо того чтобы передавать UoW в обработчик, мы ожидаем, что обработчики уже имеют все свои зависимости, поэтому им нужен только один аргумент - конкретное событие или команда. |
14.7. Использование Bootstrap в наших точках входа
Теперь в точках входа нашего приложения мы просто вызываем bootstrap.bootstrap() и получаем готовую к работе шину сообщений, вместо того чтобы настраивать UoW и все остальное:
-from allocation import views
+from allocation import bootstrap, views
app = Flask(__name__)
-orm.start_mappers() (1)
+bus = bootstrap.bootstrap()
@app.route("/add_batch", methods=['POST'])
@@ -19,8 +16,7 @@ def add_batch():
cmd = commands.CreateBatch(
request.json['ref'], request.json['sku'], request.json['qty'], eta,
)
- uow = unit_of_work.SqlAlchemyUnitOfWork() (2)
- messagebus.handle(cmd, uow)
+ bus.handle(cmd) (3)
return 'OK', 201| 1 | Нам больше не нужно вызывать start_orm(); этапы инициализации скрипта bootstrap сделают это. |
| 2 | Нам больше не нужно явно создавать конкретный тип UoW; скрипт bootstrap по умолчанию позаботится об этом. |
| 3 | И наша шина сообщений теперь является конкретным экземпляром, а не глобальным модулем.[38] |
14.8. Инициализация DI в наших тестах
В тестах мы можем использовать bootstrap.bootstrap() с переопределенными значениями по умолчанию, чтобы получить пользовательскую шину сообщений. Вот пример в интеграционном тесте:
@pytest.fixture
def sqlite_bus(sqlite_session_factory):
bus = bootstrap.bootstrap(
start_orm=True, (1)
uow=unit_of_work.SqlAlchemyUnitOfWork(sqlite_session_factory), (2)
send_mail=lambda *args: None, (3)
publish=lambda *args: None, (3)
)
yield bus
clear_mappers()
def test_allocations_view(sqlite_bus):
sqlite_bus.handle(commands.CreateBatch('sku1batch', 'sku1', 50, None))
sqlite_bus.handle(commands.CreateBatch('sku2batch', 'sku2', 50, today))
...
assert views.allocations('order1', sqlite_bus.uow) == [
{'sku': 'sku1', 'batchref': 'sku1batch'},
{'sku': 'sku2', 'batchref': 'sku2batch'},
]| 1 | Мы все еще хотим стартовать ОРМ… |
| 2 | …потому что мы будем использовать настоящий UoW, хотя и с базой данных in-memory. |
| 3 | Но нам не нужно отправлять электронную почту или публиковать, поэтому мы делаем эти noops.[39] |
В наших модульных тестах, напротив, мы можем повторно использовать наш FakeUnitOfWork:
def bootstrap_test_app():
return bootstrap.bootstrap(
start_orm=False, (1)
uow=FakeUnitOfWork(), (2)
send_mail=lambda *args: None, (3)
publish=lambda *args: None, (3)
)| 1 | Нет необходимости запускать ORM… |
| 2 | …потому что фейковый UoW не использует его. |
| 3 | Мы также хотим подделать наши адаптеры электронной почты и Redis. |
Таким образом, мы избавились от дублирования и перенесли множество настроек и разумных значений по умолчанию в одно место.
14.9. Построение адаптера "Properly": Пример из практики
Чтобы действительно понять, как все это работает, давайте рассмотрим пример того, как вы могли бы "правильно" построить адаптер и сделать для него инъекцию зависимостей.
На данный момент у нас есть два типа зависимостей:
uow: unit_of_work.AbstractUnitOfWork, (1)
send_mail: Callable, (2)
publish: Callable, (2)| 1 | UoW имеет абстрактный базовый класс. Это самый тяжелый вариант для объявления и управления внешней зависимостью. Мы бы использовали это для случая, когда зависимость относительно сложная. |
| 2 | Отправитель электронной почты и издатель pub/sub определяются как функции. Это отлично работает для простых зависимостей. |
Вот некоторые из вещей, которые мы вводим в работу:
-
Клиент файловой системы S3
-
Клиент хранилища ключ/значение
-
Объект сессии
requests
Большинство из них будут иметь более сложные API, которые вы не сможете охватить в виде одной функции: чтение и запись, GET и POST, и так далее.
Несмотря на простоту, давайте на примере send_mail рассмотрим, как можно определить более сложную зависимость.
14.9.1. Определите абстрактную и конкретную реализации
Мы представим себе более общий API уведомлений. Это может быть электронная почта, может быть SMS, могут быть сообщения в Slack в один прекрасный день.
class AbstractNotifications(abc.ABC):
@abc.abstractmethod
def send(self, destination, message):
raise NotImplementedError
...
class EmailNotifications(AbstractNotifications):
def __init__(self, smtp_host=DEFAULT_HOST, port=DEFAULT_PORT):
self.server = smtplib.SMTP(smtp_host, port=port)
self.server.noop()
def send(self, destination, message):
msg = f'Subject: allocation service notification\n{message}'
self.server.sendmail(
from_addr='allocations@example.com',
to_addrs=[destination],
msg=msg
)Мы изменим зависимость в сценарии bootstrap:
def bootstrap(
start_orm: bool = True,
uow: unit_of_work.AbstractUnitOfWork = unit_of_work.SqlAlchemyUnitOfWork(),
- send_mail: Callable = email.send,
+ notifications: AbstractNotifications = EmailNotifications(),
publish: Callable = redis_eventpublisher.publish,
) -> messagebus.MessageBus:14.9.2. Создайте фейковую версию для ваших тестов
Мы прорабатываем и определяем фейковую версию для модульного тестирования:
class FakeNotifications(notifications.AbstractNotifications):
def __init__(self):
self.sent = defaultdict(list) # type: Dict[str, List[str]]
def send(self, destination, message):
self.sent[destination].append(message)
...И мы используем его в наших тестах:
def test_sends_email_on_out_of_stock_error(self):
fake_notifs = FakeNotifications()
bus = bootstrap.bootstrap(
start_orm=False,
uow=FakeUnitOfWork(),
notifications=fake_notifs,
publish=lambda *args: None,
)
bus.handle(commands.CreateBatch("b1", "POPULAR-CURTAINS", 9, None))
bus.handle(commands.Allocate("o1", "POPULAR-CURTAINS", 10))
assert fake_notifs.sent['stock@made.com'] == [
f"Out of stock for POPULAR-CURTAINS",
]14.9.3. Разберитесь, как провести интеграционное тестирование реальной вещи
Теперь мы тестируем реальную вещь, обычно с помощью сквозного или интеграционного тестирования. Мы использовали MailHog в качестве реального почтового сервера для нашей среды разработки Docker:
version: "3"
services:
redis_pubsub:
build:
context: .
dockerfile: Dockerfile
image: allocation-image
...
api:
image: allocation-image
...
postgres:
image: postgres:9.6
...
redis:
image: redis:alpine
...
mailhog:
image: mailhog/mailhog
ports:
- "11025:1025"
- "18025:8025"
В наших интеграционных тестах мы используем настоящий класс EmailNotifications, общающийся с сервером MailHog в кластере Docker:
@pytest.fixture
def bus(sqlite_session_factory):
bus = bootstrap.bootstrap(
start_orm=True,
uow=unit_of_work.SqlAlchemyUnitOfWork(sqlite_session_factory),
notifications=notifications.EmailNotifications(), (1)
publish=lambda *args: None,
)
yield bus
clear_mappers()
def get_email_from_mailhog(sku): (2)
host, port = map(config.get_email_host_and_port().get, ['host', 'http_port'])
all_emails = requests.get(f'http://{host}:{port}/api/v2/messages').json()
return next(m for m in all_emails['items'] if sku in str(m))
def test_out_of_stock_email(bus):
sku = random_sku()
bus.handle(commands.CreateBatch('batch1', sku, 9, None)) (3)
bus.handle(commands.Allocate('order1', sku, 10))
email = get_email_from_mailhog(sku)
assert email['Raw']['From'] == 'allocations@example.com' (4)
assert email['Raw']['To'] == ['stock@made.com']
assert f'Out of stock for {sku}' in email['Raw']['Data']| 1 | Мы используем наш bootstrapper для создания шины сообщений, которая взаимодействует с настоящим классом уведомлений. |
| 2 | Мы выяснили, как получать электронные письма из нашего "настоящего" сервера электронной почты. |
| 3 | Мы используем шину для проведения тестовой установки. |
| 4 | Вопреки всему, это действительно сработало, причем практически с первого раза! |
И это все.
14.10. Подведение итогов
-
Как только у вас появится более одного адаптера, вы начнете испытывать сильную боль от передачи зависимостей вручную, если только вы не сделаете что-то вроде инъекции зависимостей.
-
Настройка внедрения зависимостей - это лишь одно из многих типичных действий по setup/initialization, которые необходимо выполнить всего один раз при запуске приложения. Часто хорошей идеей является объединение всего этого в bootstrap-скрипт.
-
Сценарий bootstrap также хорош как место для предоставления разумной конфигурации по умолчанию для ваших адаптеров и как единственное место для переопределения этих адаптеров с подделками для ваших тестов.
-
Фреймворк для инъекции зависимостей может быть полезен, если вам нужно сделать DI на нескольких уровнях - например, если у вас есть цепочки зависимостей компонентов, которые все нуждаются в DI.
-
В этой главе также представлен пример изменения неявной/простой зависимости на "правильную". адаптер, вычисляя ABC, определяя его реальные и ложные реализации и продумывая интеграционное тестирование.
These were the last patterns we wanted to cover, which brings us to the end of Событийно-Ориентированная архитектура. In the epilogue, we’ll try to give you some pointers for applying these techniques in the Real WorldTM.
Это были последние паттерны, которые мы хотели охватить, что подводит нас к концу [части 2]. В the epilogue мы постараемся дать вам несколько советов по применению этих методов в Real WorldTM.
Appendix A: Эпилог
Что теперь?
Фух! В этой книге рассмотрено много тем, и для большей части аудитории все эти идеи являются новыми. Учитывая это, надежда сделать вас экспертами в этих техниках, конечно есть, но всё, что можно сделать, это предоставить общие идеи и достаточно кода, чтобы попытаться написать что-то с нуля.
Код, который представлен в этой книге, не является закаленным в боях Production code: это набор блоков Lego, с которыми можно играть, чтобы сделать свой первый дом, космический корабль и небоскреб.
Таким образом, остается две большие задачи. Надо бы поговорить о том, как начать реально применять эти идеи в существующей системе, и стоит предупредить вас о некоторых особенностях, которые пришлось пропустить. Мы предоставили читателю целый арсенал способов "выстрелить себе в ногу", поэтому следует обсудить некоторые основы безопасности при обращении с "огнестрельным оружием".
Как попасть отсюда в светлое будущее?
Скорее всего, многие подумают примерно следующее:
"Хорошо, Боб и Гарри, это все хорошо, и если меня когда-нибудь наймут для работы над новым проектом, я знаю, что делать. Но пока что я здесь со своей кучей говнкода Django, и я не вижу никакого способа добраться до вашей хорошей, чистой, идеальной, незапятнанной, упрощенной модели. Точно не отсюда".
Мы вас слышим. Когда вы уже построили большой клубок грязного кода, трудно понять, как начать что-то улучшать. В действительности, надо решать проблемы шаг за шагом.
Прежде всего определить: какую проблему вы пытаетесь решить? Сложно ли изменить программное обеспечение? Является ли производительность неприемлемой? Есть ли у странные, необъяснимые ошибки?
Наличие четкой цели поможет расставить приоритеты в работе, которую необходимо выполнить, и, что очень важно, донести до остальных членов команды причины её выполнения. Бизнес, как правило, прагматично подходит к техническому долгу и рефакторингу, если инженеры могут аргументированно доказать необходимость исправления.
| Внесение сложных изменений в систему часто легче продать, если связать их с работой над функциями. Возможно, вы запускаете новый продукт или выводите свои услуги на новые рынки? Это подходящее время для того, чтобы потратить инженерные ресурсы на исправление фундамента. Если проект рассчитан на шесть месяцев, легче привести аргументы в пользу трех недель работы по очистке. Боб называет это архитектурным налогом. |
Разделение запутанных обязанностей
В начале книги мы говорили, что основной характеристикой БОЛЬШОГО ШАРА ГРЯЗИ является однородность: каждая часть системы выглядит одинаково, потому что нами не были чётко определены обязанности каждого компонента. Чтобы исправить это, следовало бы начать разделять обязанности и вводить четкие границы. Однима из первых шагов, который было бы правильно сделать, это начать строить сервисный слой (Домен системы совместной работы).
[plantuml, apwp_ep01, config=plantuml.cfg] @startuml scale 4 hide empty members Workspace *- Folder : contains Account *- Workspace : owns Account *-- Package : has User *-- Account : manages Workspace *-- User : has members User *-- Document : owns Folder *-- Document : contains Document *- Version: has User *-- Version: authors @enduml
Это была система, в которой Боб впервые научился разгребать "клубок грязи", и это было очень непросто. Логика была всюду - на веб-страницах, в объектах менеджеров, в помощниках, в жирных классах сервисов, которые мы написали для абстрагирования менеджеров и помощников, и в зпутанносложных командных объектах, которые были созданы для разделения сервисов.
Если вы работаете в системе, которая достигла этой точки, ситуация может казаться безнадежной, но никогда не поздно начать прополку заросшего сада. В конце концов, был нанят архитектор, который знал, что делает, и он помог нам вернуть всё под контроль.
Начните с разработки use cases вашей системы. Если у вас есть пользовательский интерфейс, какие действия он выполняет? Если есть компонент обработки бэкенда, возможно, каждое задание cron или задание Celery является единственным вариантом использования. Каждый из вариантов использования должен иметь императивное имя: Например, применить начисления по счетам, очистить заброшенные счета или поднять заказ на поставку.
В нашем случае большинство вариантов использования были частью классов менеджеров и имели такие названия, как Create Workspace или Delete Document Version. Каждый пример использования вызывался с веб-фронтэнда.
Мы стремимся создать единую функцию или класс для каждой из этих поддерживаемых операций, которая занимается оркестровкой выполняемой работы. Каждый вариант использования должен делать следующее:
-
Начать собственную транзакцию базы данных, если это необходимо
-
Получеать все необходимыe данныe
-
Проверять все предварительные условия (см. шаблон Ensure в Validation).
-
Обновлять модели домена
-
Сохранять любые изменения
Каждый вариант использования должен быть успешным или неудачным как атомарная единица. Вполне может понадобиться вызвать один вариант использования из другого. Всё в порядке; просто запишите это и старайтесь избегать длительных транзакций с базой данных.
| Одна из самых больших проблем, с которой мы столкнулись, заключалась в том, что методы менеджера вызывали другие методы менеджера, и доступ к данным мог происходить из самих объектов модели. Было трудно понять, что делает каждая операция, не отправляясь на поиски сокровищ по всей кодовой базе. Сведение всей логики в один метод и использование UoW для управления нашими транзакциями упростило работу с системой. |
| Это нормально, если у вас есть дублирование в функциях прецедентов. Мы не пытаемся написать идеальный код; мы просто пытаемся извлечь некоторые значимые слои. Лучше дублировать некоторый код в нескольких местах, чем иметь функции прецедентов, вызывающие друг друга в длинной цепочке. |
Это хорошая возможность вытащить любой код доступа к данным или оркестровки из модели домена и в варианты использования. Мы также должны попытаться вытащить проблемы ввода-вывода (например, отправка электронной почты, запись файлов) из модели домена и в функции прецедентов. Мы применяем методы из Краткая интерлюдия: О Связях и Абстракции к абстракциям, чтобы наши обработчики могли тестироваться даже при выполнении ввода-вывода.
В основном эти функции будут связаны с протоколированием, доступом к данным и обработкой ошибок. Выполнив этот шаг, вы получите представление о том, что на самом деле делает ваша программа, и способ убедиться, что каждая операция имеет четко определенное начало и конец. Мы сделаем шаг к построению чистой модели домена.
Читать Working Effectively with Legacy Code by Michael C. Feathers (Prentice Hall) для руководства по тестированию унаследованного кода и началу разделения ответственности.
Определение агрегатов и ограниченных контекстов
Частично проблема с кодовой базой в нашем примере заключалась в том, что граф объектов был сильно связан. Каждый аккаунт имел множество рабочих пространств, а каждое рабочее пространство имело множество членов, у всех из которых были свои собственные аккаунты. Каждое рабочее пространство содержало множество документов, которые имели множество версий.
Вы не можете выразить весь ужас вещи в диаграмме классов. Во-первых, не было ни одной учетной записи, связанной с пользователем. Вместо этого существовало странное правило, требующее перечислить все учетные записи, связанные с пользователем через рабочие пространства, и выбрать ту, у которой самая ранняя дата создания.
Каждый объект в системе был частью иерархии наследования, которая включала SecureObject и Version. Эта иерархия наследования была отражена непосредственно в схеме базы данных, так что каждый запрос должен был объединять 10 различных таблиц и просматривать столбец дискриминатора, чтобы определить, с какими объектами вы работаете.
Кодовая база позволила легко "расставить точки" прокладывая свой путь через эти объекты следующим образом:
user.account.workspaces[0].documents.versions[1].owner.account.settings[0];Построить систему таким образом с помощью Django ORM или SQLAlchemy легко, но следует избегать. Хотя это удобно, это очень затрудняет рассуждения о производительности, потому что каждое свойство может вызвать поиск в базе данных.
| Агрегаты - это граница непротиворечивости. В целом, каждый случай использования должен обновлять один агрегат за раз. Один обработчик получает один агрегат из хранилища, изменяет его состояние и вызывает любые события, которые происходят в результате. Если вам нужны данные из другой части системы, совершенно нормально использовать модель чтения, но избегайте обновления нескольких агрегатов в одной транзакции. Когда мы решаем разделить код на различные агрегаты, мы явно решаем сделать их временно согласованными друг с другом. |
Многие операции требуют, чтобы мы перебирали объекты таким образом - например:
# Блокировка рабочих пространств пользователя за неуплату
def lock_account(user):
for workspace in user.account.workspaces:
workspace.archive()Или даже пересмотреть коллекции папок и документов:
def lock_documents_in_folder(folder):
for doc in folder.documents:
doc.archive()
for child in folder.children:
lock_documents_in_folder(child)Эти операции убивали производительность, но их исправление означало отказ от нашего графа с одним объектом. Вместо этого мы начали идентифицировать агрегаты и разрывать прямые связи между объектами.
Мы говорили о печально известной проблеме SELECT N+1 в Command-Query Responsibility Segregation (CQRS)[1] и о том, как мы можем использовать различные методики при чтении данных для запросов по сравнению с чтением данных для команд.
|
В основном мы делали это, заменяя прямые ссылки идентификаторами.
До агрегатов было так:
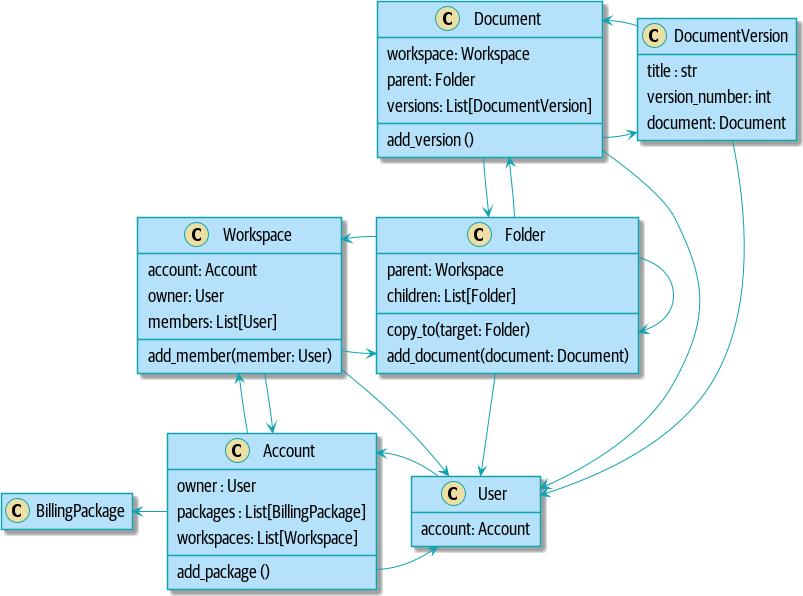
[plantuml, apwp_ep02, config=plantuml.cfg]
@startuml
scale 4
hide empty members
together {
class Document {
add_version()
workspace: Workspace
parent: Folder
versions: List[DocumentVersion]
}
class DocumentVersion {
title : str
version_number: int
document: Document
}
class Folder {
parent: Workspace
children: List[Folder]
copy_to(target: Folder)
add_document(document: Document)
}
}
together {
class User {
account: Account
}
class Account {
add_package()
owner : User
packages : List[BillingPackage]
workspaces: List[Workspace]
}
}
class BillingPackage {
}
class Workspace {
add_member(member: User)
account: Account
owner: User
members: List[User]
}
Account --> Workspace
Account -left-> BillingPackage
Account -right-> User
Workspace --> User
Workspace --> Folder
Workspace --> Account
Folder --> Folder
Folder --> Document
Folder --> Workspace
Folder --> User
Document -right-> DocumentVersion
Document --> Folder
Document --> User
DocumentVersion -right-> Document
DocumentVersion --> User
User -left-> Account
@enduml
После моделирования с помощью агрегатов:
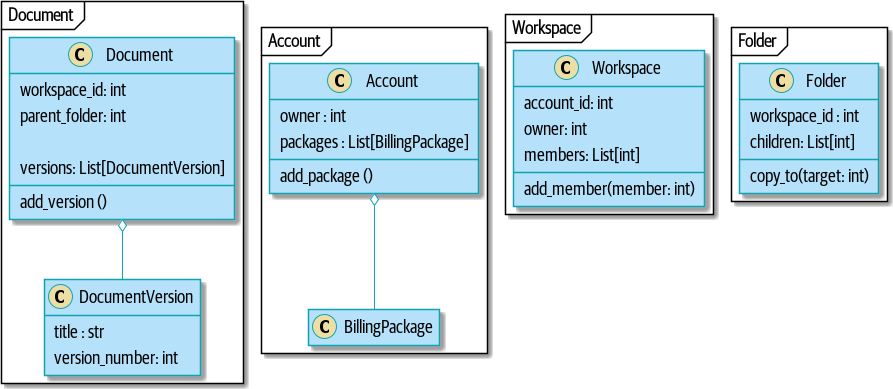
[plantuml, apwp_ep03, config=plantuml.cfg]
@startuml
scale 4
hide empty members
frame Document {
class Document {
add_version()
workspace_id: int
parent_folder: int
versions: List[DocumentVersion]
}
class DocumentVersion {
title : str
version_number: int
}
}
frame Account {
class Account {
add_package()
owner : int
packages : List[BillingPackage]
}
class BillingPackage {
}
}
frame Workspace {
class Workspace {
add_member(member: int)
account_id: int
owner: int
members: List[int]
}
}
frame Folder {
class Folder {
workspace_id : int
children: List[int]
copy_to(target: int)
}
}
Document o-- DocumentVersion
Account o-- BillingPackage
@enduml
Двунаправленные ссылки часто являются признаком неправильной работы агрегаторов. В нашем первоначальном коде Документ знал о содержащейся в нем Папке, а Папка имела коллекцию Документов. Это упрощает обход графа объектов, но мешает нам правильно продумать границы согласованности, которые нам нужны. Мы разбиваем агрегаты на части, используя вместо этого ссылки. В новой модели документ имел ссылку на свою родительскую_папку, но не имел возможности прямого доступа к папке.
|
Если нам нужно было читать данные, мы избегали написания сложных циклов и преобразований и старались заменить их прямым SQL. Например, один из наших экранов представлял собой древовидное представление папок и документов.
Этот экран был невероятно тяжелым для базы данных, потому что он полагался на вложенные циклы for, которые запускали лениво загруженную ORM.
| Мы используем эту же технику в [главе_12_cqrs], где мы заменяем вложенный цикл над объектами ORM простым SQL-запросом. Это первый шаг в подходе к CQRS. |
После долгих раздумий мы заменили код ORM большой и уродливой хранимой процедурой. Код выглядел ужасно, но он был намного быстрее и помог разорвать связи между Folder и Document.
Когда нам нужно было записать данные, мы изменяли по одному агрегату за раз, а для обработки событий ввели шину сообщений. Например, в новой модели, когда мы блокируем учетную запись, мы можем сначала запросить все затронутые рабочие пространства с помощью SELECT id FROM workspace WHERE account_id = ?.
Затем мы могли бы поднять новую команду для каждого рабочего пространства:
for workspace_id in workspaces:
bus.handle(LockWorkspace(workspace_id))Событийно-управляемый подход к переходу к микросервисам с помощью паттерна Strangler
Модель Strangler Fig предполагает создание новой системы по краям старой системы, сохраняя ее работоспособность. Части старой функциональности постепенно перехватываются и заменяются, пока старая система вообще ничего не будет делать и её можно будет отключить.
При создании службы доступности мы использовали технику под названием перехват событий для перемещения функциональности из одного места в другое. Это трехэтапный процесс:
-
Поднять события, представляющие изменения, происходящие в системе, которую вы хотите заменить.
-
Построить вторую систему, которая потребляет эти события и использует их для построения собственной модели домена.
-
Заменить старую систему на новую.
Мы использовали перехват event для перехода от Было: сильное двунаправленное соединение на основе XML-RPC…

[plantuml, apwp_ep04, config=plantuml.cfg] @startuml Ecommerce Context !include images/C4_Context.puml LAYOUT_LEFT_RIGHT scale 2 Person_Ext(customer, "Customer", "Wants to buy furniture") System(fulfillment, "Fulfillment System", "Manages order fulfillment and logistics") System(ecom, "Ecommerce website", "Allows customers to buy furniture") Rel(customer, ecom, "Uses") Rel(fulfillment, ecom, "Updates stock and orders", "xml-rpc") Rel(ecom, fulfillment, "Sends orders", "xml-rpc") @enduml
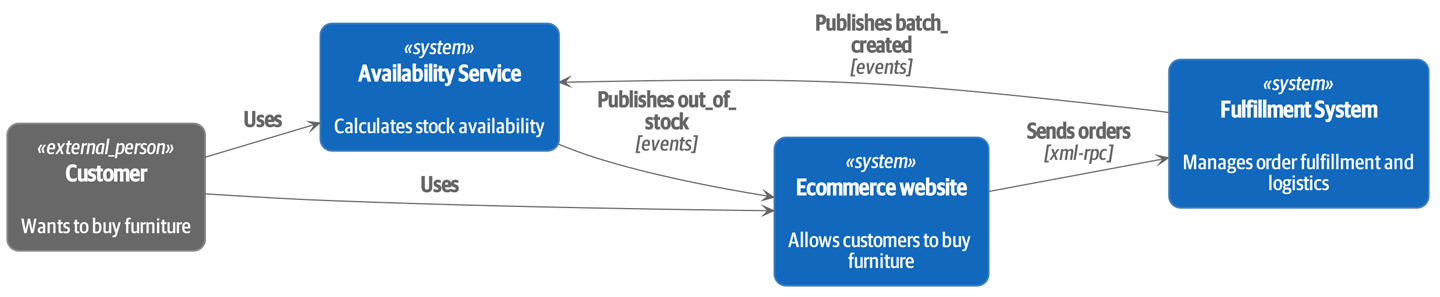
[plantuml, apwp_ep05, config=plantuml.cfg] @startuml Ecommerce Context !include images/C4_Context.puml LAYOUT_LEFT_RIGHT scale 2 Person_Ext(customer, "Customer", "Wants to buy furniture") System(av, "Availability Service", "Calculates stock availability") System(fulfillment, "Fulfillment System", "Manages order fulfillment and logistics") System(ecom, "Ecommerce website", "Allows customers to buy furniture") Rel(customer, ecom, "Uses") Rel(customer, av, "Uses") Rel(fulfillment, av, "Publishes batch_created", "events") Rel(av, ecom, "Publishes out_of_stock", "events") Rel(ecom, fulfillment, "Sends orders", "xml-rpc") @enduml
Практически, это был проект длительностью в несколько месяцев. Нашим первым шагом было написание модели домена, которая могла бы представлять партии, поставки и продукты. Мы использовали TDD для создания игрушечной системы, которая могла бы ответить на один вопрос: "Если мне нужно N единиц HAZARDOUS_RUG, сколько времени займет их доставка?".
| При развертывании событийно-управляемой системы начните с "ходячего скелета". Развертывание системы, которая просто регистрирует свои входные данные, заставляет нас решить все инфраструктурные вопросы и начать работать в production. |
Как только у нас появилась рабочая модель домена, мы перешли к созданию некоторых инфраструктурных элементов. Наша первая производственная установка представляла собой крошечную систему, которая могла получать событие batch_created и регистрировать его JSON-представление. Это "Hello World" событийно-управляемой архитектуры. Это заставило нас развернуть шину сообщений, подключить производителя и потребителя, построить конвейер развертывания и написать простой обработчик сообщений.
Получив конвейер развертывания, необходимую инфраструктуру и базовую модель домена, мы приступили к работе. Через пару месяцев мы уже работали на производстве и обслуживали реальных клиентов.
Убедить заинтересованные стороны попробовать что-то новое
Если вы думаете о том, чтобы вырезать новую систему из большого клубка грязи, вы, вероятно, испытываете проблемы с надежностью, производительностью, ремонтопригодностью или со всеми тремя одновременно. Глубокие, неразрешимые проблемы требуют радикальных мер!
В качестве первого шага мы рекомендуем моделирование домена. Во многих разросшихся системах инженеры, владельцы продуктов и клиенты больше не говорят на одном языке. Заинтересованные стороны бизнеса говорят о системе в абстрактных, сфокусированных на процессе терминах, в то время как разработчики вынуждены говорить о системе, как она физически существует в своем диком и хаотичном состоянии.
Выяснение того, как смоделировать свой домен, - сложная задача, которая сама по себе является предметом многих достойных книг. Нам нравится использовать интерактивные методы, такие как штурм событий и CRC-моделирование, потому что люди хорошо умеют сотрудничать через игру. Моделирование событий - это еще одна техника, которая объединяет инженеров и владельцев продуктов для понимания системы в терминах команд, запросов и событий.
СОВЕТ: Посмотрите на www.eventmodeling.org и www.eventstorming.org несколько отличных руководств по визуальному моделированию систем с событиями.
Цель состоит в том, чтобы иметь возможность говорить о системе, используя один и тот же вездесущий язык, чтобы вы могли договориться о том, где кроется сложность.
Мы нашли много полезного в том, чтобы рассматривать проблемы домена как ката TDD. Например, первым кодом, который мы написали для службы доступности, была модель партии и линии заказов. Вы можете рассматривать это как семинар за обедом или как всплеск в начале проекта. Как только вы сможете продемонстрировать ценность моделирования, вам будет легче привести аргументы в пользу структурирования проекта, чтобы оптимизировать его для моделирования.
Вопросы, которые задавали наши технические обозреватели и которые мы не смогли изложить в прозе
Вот некоторые вопросы, которые мы услышали во время подготовки, но не нашли подходящего места для ответа в других разделах книги:
- Нужно ли мне делать все это сразу? Могу ли я делать понемногу за раз?
-
Нет, вы абсолютно точно можете осваивать эти техники постепенно. Если у вас есть существующая система, мы рекомендуем создать слой сервисов, чтобы попытаться сохранить оркестровку в одном месте. Как только у вас есть это, гораздо проще внедрить логику в модель и перенести пограничные проблемы, такие как валидация или обработка ошибок, на точки входа.
Стоит иметь сервисный слой, даже если у вас все еще есть большой, грязный Django ORM, потому что это способ начать понимать границы операций.
Извлечение примеров использования сломает много моего существующего кода; все слишком запутанно: Просто скопируйте и вставьте. В краткосрочной перспективе можно вызвать большее дублирование. Подумайте об этом как о многоступенчатом процессе. Ваш код сейчас находится в плохом состоянии, поэтому скопируйте и вставьте его в новое место, а затем сделайте этот новый код чистым и аккуратным.
+ После этого вы можете заменить использование старого кода вызовами нового кода и, наконец, удалить беспорядок. Исправление больших кодовых баз - грязный и болезненный процесс. Не ждите, что все сразу станет лучше, и не волнуйтесь, если некоторые части вашего приложения останутся неаккуратными.
- Нужно ли мне заниматься CQRS? Это звучит странно. Разве я не могу просто использовать репозитории?
-
Конечно, можно! Техники, которые мы представляем в этой книге, призваны сделать вашу жизнь легче. Это не какая-то аскетическая дисциплина, которой можно себя наказывать.
В системе рабочего пространства/документов, на примере которой проводилось исследование, у нас было много объектов View Builder, которые использовали хранилища для получения данных, а затем выполняли некоторые преобразования, чтобы вернуть модели для немого чтения. Преимущество заключается в том, что при возникновении проблем с производительностью можно легко переписать конструктор представлений для использования пользовательских запросов или необработанного SQL.
- Как должны взаимодействовать варианты использования в рамках более крупной системы? Разве это проблема для одного называть другого?
-
Это может быть промежуточным шагом. Опять же, в примере с документами у нас были обработчики, которые должны были вызывать другие обработчики. Однако это становится очень запутанным, и гораздо лучше перейти к использованию шины сообщений для разделения этих проблем.
Как правило, ваша система будет иметь одну реализацию шины сообщений и кучу поддоменов, которые сосредоточены на определенном агрегате или наборе агрегатов. Когда ваш сценарий использования завершен, он может поднять событие, и обработчик в другом месте может быть запущен.
- Является ли запахом кода для сценария использования использование нескольких repositories/aggregates, и если да, то почему?
-
Агрегат - это граница согласованности, поэтому если в вашем случае требуется обновить два агрегата атомарно (в рамках одной транзакции), то ваша граница согласованности, строго говоря, неверна. В идеале вам следует подумать о переезде в новый агрегат, который одновременно охватывает все вещи, которые вы хотите изменить.
Если вы действительно обновляете только один агрегат и используете другой (другие) для доступа только для чтения, то это вполне, хотя вы могли бы рассмотреть возможность создания read/view модели для получения этих данных вместо этого - это делает вещи чище, если каждый случай использования имеет только один агрегат.
Если вам необходимо изменить два агрегата, но эти две операции не должны быть в одной транзакции/UoW, то рассмотрите возможность разделения работы на два разных обработчика и использования события домена для передачи информации между ними. Более подробно вы можете прочитать в эти работы по проектированию агрегатов Вона Вернона.
- Что если у меня система только для чтения, но с тяжелой бизнес-логикой?
-
Модели представления могут содержать сложную логику. В этой книге мы призывали вас разделять модели чтения и записи, поскольку у них разные требования к согласованности и пропускной способности. В основном, для чтения мы можем использовать более простую логику, но это не всегда так. В частности, разрешения и модели авторизации могут добавить много сложностей на стороне чтения.
Мы писали системы, в которых модели представлений нуждались в обширных модульных тестах. В этих системах мы разделяем построитель представлений и поисковик представлений, как в Построитель представлений и сборщик представлений (вы можете найти версию этой диаграммы в высоком разрешении на cosmicpython.com).
[plantuml, apwp_ep06, config=plantuml.cfg] @startuml View Fetcher Component Diagram !include images/C4_Component.puml ComponentDb(db, "Database", "RDBMS") Component(fetch, "View Fetcher", "Reads data from db, returning list of tuples or dicts") Component(build, "View Builder", "Filters and maps tuples") Component(api, "API", "Handles HTTP and serialization concerns") Rel(api, build, "Invokes") Rel_R(build, fetch, "Invokes") Rel_D(fetch, db, "Reads data from") @enduml
+ Это позволяет легко протестировать конструктор представлений, предоставив ему поддельные данные (например, список dicts). "Модный CQRS" с обработчиками событий на самом деле является способом запуска сложной логики представления, когда мы пишем, чтобы избежать ее запуска при чтении.
- Нужно ли мне создавать микросервисы для выполнения этих задач?
-
Боже, нет! Эти методы появились раньше микросервисов примерно на десятилетие. Агрегаты, события домена и инверсия зависимостей - это способы управления сложностью в больших системах. Так получилось, что когда вы создали набор сценариев использования и модель бизнес-процесса, перенести его в собственный сервис относительно просто, но это не является обязательным условием.
- Я использую Django. Может нуегонах?
-
У нас есть целое приложение специально для вас: [appendix_django]!
Footguns
Итак, мы дали вам целую кучу новых игрушек для игр. Вот мелкий шрифт. Гарри и Боб не рекомендуют вам копировать и вставлять наш код в производственную систему и перестраивать свою автоматизированную торговую платформу на Redis pub/sub. В целях краткости и простоты мы обошли стороной многие щекотливые темы. Вот список того, что, по нашему мнению, вы должны знать, прежде чем попробовать это по-настоящему.
- Надежные сообщения - это сложно
-
Redis pub/sub ненадежен и не должен использоваться в качестве инструмента обмена сообщениями общего назначения. Мы выбрали его, потому что он хорошо знаком и прост в управлении. В MADE мы используем Event Store в качестве инструмента обмена сообщениями, но у нас есть опыт работы с RabbitMQ и Amazon EventBridge.
На сайте Тайлера Трэта bravenewgeek.com есть несколько отличных статей; вам следует хотя бы прочитать "You Cannot Have Exactly-Once Delivery" и "What You Want Is What You Don’t: Понимание компромиссов в распределенном обмене сообщениями".
- Мы однозначно выбираем небольшие, целенаправленные сделки, которые могут потерпеть неудачу самостоятельно
-
В главе События и шина сообщений мы обновляем наш процесс таким образом, чтобы распределение строки заказа и перераспределение строки происходили в двух отдельных единицах работы. Вам понадобится мониторинг, чтобы знать, когда эти транзакции терпят неудачу, и инструменты для воспроизведения событий. Некоторые из этих задач упрощаются при использовании журнала транзакций в качестве брокера сообщений (например, Kafka или EventStore). Вы также можете посмотреть на Outbox pattern.
- Мы не обсуждаем идемпотентность
-
Мы не задумывались о том, что происходит при повторном обращении к обработчикам. На практике вы захотите сделать обработчики идемпотентными, чтобы их повторный вызов с одним и тем же сообщением не приводил к повторным изменениям состояния. Это ключевая техника для создания надежности, поскольку она позволяет нам безопасно повторять события, если они не удались.
Есть много хорошего материала по идемпотентной обработке сообщений, попробуйте начать с "How to Ensure Idempotency in an Eventual Consistent DDD/CQRS Application" и "(Un)Reliability in Messaging".
- Ваши события должны будут изменить свою схему со временем
-
Вам необходимо найти способ документировать события и делиться схемами с потребителями. Нам нравится использовать схему JSON и разметку, потому что это просто, но есть и другой уровень техники. Грег Янг написал целую книгу об управлении системами, управляемыми событиями, с течением времени: Versioning in an Event Sourced System (Leanpub).
Больше обязательного чтения
Еще несколько книг, которые мы хотели бы порекомендовать в помощь читателю:
-
Clean Architectures in Python Леонардо Джордани (Leanpub), вышедшая в 2019 году, является одной из немногих предыдущих книг по архитектуре приложений на Python.
-
Enterprise Integration Patterns Грегора Хохпе и Бобби Вульфа (Addison-Wesley Professional) - это довольно хорошее начало для изучения моделей обмена сообщениями.
-
Monolith to Microservices Сэма Ньюмана (O’Reilly), а также первая книга Ньюмана, Building Microservices (O’Reilly). Узор Strangler Fig упоминается как любимая, наряду со многими другими. С ними стоит ознакомиться, если вы думаете о переходе на микросервисы, также они хорошо описывают паттерны интеграции и соображения, связанные с асинхронным обменом сообщениями на основе интеграции.
Подведение итогов
Фух! Это множество предупреждений и предложений по чтению; надеемся, что мы не отпугнули вас окончательно. Наша цель в этой книге - дать вам достаточно знаний и интуиции, чтобы вы могли начать строить что-то из этого для себя. Мы будем рады узнать, как у вас идут дела и с какими проблемами вы сталкиваетесь при использовании техник в своих системах, так почему бы не связаться с нами по адресу www.cosmicpython.com?
Appendix B: Сводная диаграмма и таблица
Вот как выглядит наша архитектура к концу книги:
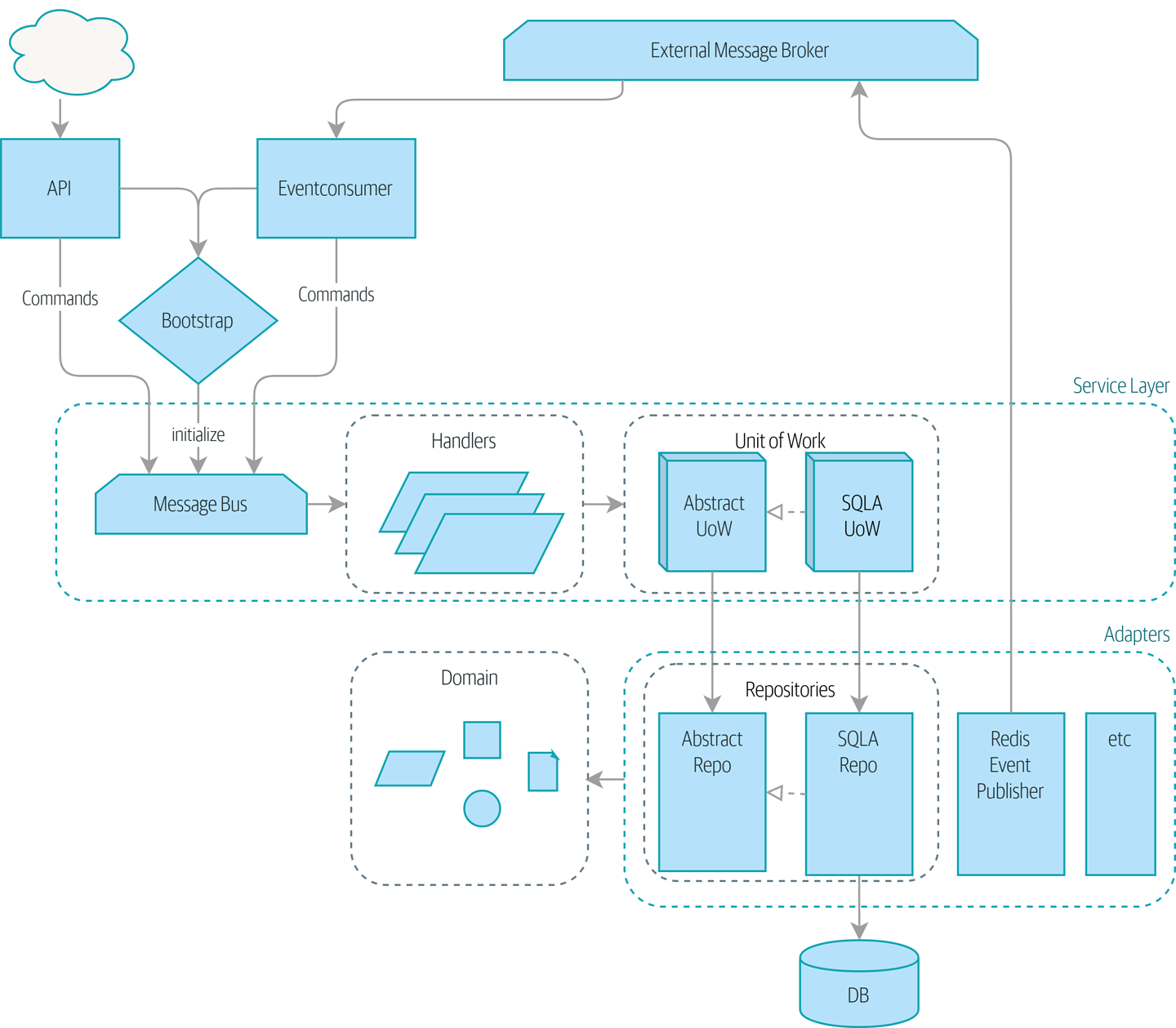
Компоненты нашей архитектуры и то, что все они делают описывает каждый паттерн и его действие.
| Уровень | Компонент | Описание |
|---|---|---|
Домен определяет бизнес-логику.. |
Entity |
Объект домена, атрибуты которого могут меняться, но который имеет узнаваемую идентичность с течением времени. |
Value object |
Неизменяемый объект домена, атрибуты которого полностью определяют его. Он взаимозаменяем с другими идентичными объектами. |
|
Aggregate |
Кластер связанных объектов, которые мы рассматриваем как единое целое для целей изменения данных. Определяет и обеспечивает границу согласованности. |
|
Event |
Событие Представляет собой нечто произошедшее. |
|
Command |
Представляет собой задание, которое должна выполнить система. |
|
Сервисный уровень Определяет задачи, которые должна выполнять система, и организует работу различных компонентов. |
Handler |
Получает команду или событие и выполняет то, что должно произойти. |
Unit of work |
Абстракция вокруг целостности данных. Каждая единица работы представляет собой атомарное обновление. Делает репозитории доступными. Отслеживает новые события по полученным агрегатам. |
|
Message bus (internal) |
Обрабатывает команды и события, направляя их в соответствующий обработчик. |
|
Адаптеры (вторичные) Конкретные реализации интерфейса, который идет от нашей системы к внешнему миру (вход/выход).. |
Repository |
Абстракция вокруг постоянного хранилища. Каждый агрегат имеет свой собственный репозиторий. |
Event publisher |
Выдаёт события на внешнюю шину сообщений. |
|
Entrypoints (первичные адаптеры) Переводить внешние входные данные в вызовы на сервисном уровне.. |
Web |
Получает веб-запросы и преобразует их в команды, передавая их на внутреннюю шину сообщений. |
Event consumer |
Считывает события из внешней шины сообщений и преобразует их в команды, передавая их во внутреннюю шину сообщений. |
|
N/A |
Внешняя шина сообщений (брокер сообщений) |
Часть инфраструктуры, которую различные службы используют для взаимодействия через события. |
Appendix C: Шаблонная структура проекта
Примерно в [главе_04_service_layer] мы перешли от простого хранения всего в одной папке к более структурированному дереву, и подумали, что будет интересно описать переместившиеся части.
|
Код этого приложения находится в ветке appendix_project_structure на GitHub: git clone https://github.com/cosmicpython/code.git cd code git checkout appendix_project_structure |
Основная структура папок выглядит следующим образом:
.
├── Dockerfile (1)
├── Makefile (2)
├── README.md
├── docker-compose.yml (1)
├── license.txt
├── mypy.ini
├── requirements.txt
├── src (3)
│ ├── allocation
│ │ ├── __init__.py
│ │ ├── adapters
│ │ │ ├── __init__.py
│ │ │ ├── orm.py
│ │ │ └── repository.py
│ │ ├── config.py
│ │ ├── domain
│ │ │ ├── __init__.py
│ │ │ └── model.py
│ │ ├── entrypoints
│ │ │ ├── __init__.py
│ │ │ └── flask_app.py
│ │ └── service_layer
│ │ ├── __init__.py
│ │ └── services.py
│ └── setup.py (3)
└── tests (4)
├── conftest.py (4)
├── e2e
│ └── test_api.py
├── integration
│ ├── test_orm.py
│ └── test_repository.py
├── pytest.ini (4)
└── unit
├── test_allocate.py
├── test_batches.py
└── test_services.py| 1 | docker-compose.yml и Dockerfile являются основными элементами конфигурации для контейнеров, которые запускают приложение, и они также могут запускать тесты (для CI). Более сложный проект может иметь несколько Docker-файлов, хотя замечено, что минимизация количества образов обычно является хорошей идеей.[40] |
| 2 | Makefile обеспечивает точку входа для всех типичных команд, которые разработчик (или сервер CI) может захотеть выполнить во время своего обычного рабочего процесса: make build, make test и так далее.[41] Это необязательно. Вы можете просто использовать docker-compose и pytest напрямую, но если ничего другого нет, то приятно иметь все "общие команды". в каком-нибудь списке, и в отличие от документации, Makefile - это код, поэтому он имеет меньше шансов устареть. |
| 3 | Весь исходный код приложения, включая модель домена, приложение Flask и код инфраструктуры, находится в пакете Python внутри src,[42] который мы устанавливаем с помощью pip install -e и файла setup.py. Это упрощает импорт. В настоящее время структура внутри этого модуля абсолютно плоская, но для более сложного проекта можно ожидать роста иерархии папок, включающей в себя domain_model/, infrastructure/, services/, and api/. |
| 4 | Тесты живут в своей собственной папке. Вложенные папки выделяют различные типы тестов и позволяют запускать их отдельно. Можно хранить общие фикстуры (conftest.py) в основной папке с тестами и при желании вложить более специфические. Это также место для хранения pytest.ini. |
| На сайте pytest docs очень хорошо описана компоновка тестов и возможность их импорта. |
Давайте рассмотрим некоторые из этих файлов и концепций более подробно.
C.1. Env Vars, 12-Factor, и Config, внутренние и внешние контейнеры
Основная проблема, которую мы пытаемся решить, заключается в том, что нам нужны разные настройки конфигурации для следующего:
-
Запуск кода или тестов непосредственно с вашей собственной dev-машины, возможно, обращаясь к сопоставленным портам из контейнеров Docker
-
Запуск на самих контейнерах, с "реальными" портами и именами хостов
-
Различные контейнерные среды (dev, staging, prod и т.д.)
Конфигурирование через переменные окружения, как это предлагается в 12-факторный манифест, решит эту проблему, но конкретно, как мы реализуем это в коде и контейнерах?
C.2. Config.py
Всякий раз, когда коду приложения требуется доступ к некоторой конфигурации, он будет получать её из файла под названием config.py. Вот несколько примеров:
import os
def get_postgres_uri(): (1)
host = os.environ.get('DB_HOST', 'localhost') (2)
port = 54321 if host == 'localhost' else 5432
password = os.environ.get('DB_PASSWORD', 'abc123')
user, db_name = 'allocation', 'allocation'
return f"postgresql://{user}:{password}@{host}:{port}/{db_name}"
def get_api_url():
host = os.environ.get('API_HOST', 'localhost')
port = 5005 if host == 'localhost' else 80
return f"http://{host}:{port}"| 1 | Используем функции для получения текущей конфигурации, а не константы, доступные во время импорта, потому что это позволяет клиентскому коду изменять os.environ, если это необходимо. |
| 2 | В config.py также определены некоторые настройки по умолчанию, предназначенные для работы при запуске кода с локальной машины разработчика.[43] |
Если вы устали от ручной работы по созданию собственных функций конфигурации на основе окружения, стоит обратить внимание на элегантный пакет Python под названием environ-config.
| Не позволяйте этому конфигурационному модулю стать свалкой, которая полна вещей, только смутно связанных с конфигурацией, а затем импортируется повсюду. Сохраняйте вещи неизменными и изменяйте их только с помощью переменных среды. Если вы решите использовать скрипт начальной загрузки, вы можете сделать его единственным местом (кроме тестов), в которое импортируется конфигурация. |
C.3. Docker-Compose и Containers Config
Мы используем легкий инструмент оркестровки контейнеров Docker под названием docker-compose. Его основная конфигурация осуществляется через YAML-файл (вздох):[44]
version: "3"
services:
app: (1)
build:
context: .
dockerfile: Dockerfile
depends_on:
- postgres
environment: (3)
- DB_HOST=postgres (4)
- DB_PASSWORD=abc123
- API_HOST=app
- PYTHONDONTWRITEBYTECODE=1 (5)
volumes: (6)
- ./src:/src
- ./tests:/tests
ports:
- "5005:80" (7)
postgres:
image: postgres:9.6 (2)
environment:
- POSTGRES_USER=allocation
- POSTGRES_PASSWORD=abc123
ports:
- "54321:5432"| 1 | В файле docker-compose определяем различные сервисы (контейнеры), которые нужны для нашего приложения. Обычно один главный образ содержит весь код, и можно использовать его для запуска API, тестов или любого другого сервиса, которому нужен доступ к доменной модели. |
| 2 | Вероятно, у вас будут и другие инфраструктурные службы, включая базу данных. В производстве вы можете не использовать для этого контейнеры; Вы можете использовать облачного провайдера, но docker-compose дает нам возможность создать подобный сервис для dev или CI. |
| 3 | Строфа environment позволяет вам установить переменные окружения для ваших контейнеров, имена хостов и портов, как это видно из кластера Docker. Если у вас достаточно контейнеров, чтобы информация начала дублироваться в этих разделах, вы можете использовать environment_file вместо этого. Мы обычно называем наш container.env. |
| 4 | Внутри кластера docker-compose устанавливает сетевое взаимодействие таким образом, чтобы контейнеры были доступны друг другу через имена хостов, названные по имени их сервиса. |
| 5 | Совет профессионала: Если вы монтируете тома для обмена папками с исходными текстами между локальной машиной разработчиков и контейнером, переменная окружения PYTHONDONTWRITEBYTECODE указывает Python не писать файлы .pyc, и это избавит вас от миллионов файлов, принадлежащих корню, разбросанных по всей локальной файловой системе, раздражающих удалением и вызывающих странные ошибки компилятора Python. |
| 6 | Монтирование исходного и тестового кода в виде томов означает, что нам не нужно перестраивать наши контейнеры каждый раз, когда мы вносим изменения в код. |
| 7 | Секция ports позволяет нам открывать порты из контейнеров во внешний мирСноска:[На CI-сервере вы не сможете надежно открывать произвольные порты, но это лишь удобство для локальных разработчиков. Вы можете найти способы сделать эти сопоставления портов необязательными (например, с помощью docker-compose.override.yml).]- они соответствуют портам по умолчанию, которые заданы в config.py. |
Внутри Docker другие контейнеры доступны через имена хостов, названные по имени их службы. Вне Docker они доступны на localhost, на порту, определенном в разделе ports.
|
C.4. Установка вашего источника в виде пакета
Весь код всё, кроме тестов) находится в папке src:
├── src
│ ├── allocation (1)
│ │ ├── config.py
│ │ └── ...
│ └── setup.py (2)| 1 | Вложенные папки определяют имена модулей верхнего уровня. Вы можете иметь несколько, если хотите. |
| 2 | А setup.py - это файл, который нужен для того, чтобы сделать его pip-инсталлируемым, как показано далее. |
from setuptools import setup
setup(
name='allocation',
version='0.1',
packages=['allocation'],
)Это все, что вам нужно. packages= указывает имена вложенных папок, которые вы хотите установить в качестве модулей верхнего уровня. Запись " имя " является просто косметической, но она обязательна. Для пакета, который на самом деле никогда не попадет в PyPI, это будет прекрасно.сноска:[Дополнительные советы setup.py см. в разделе эта статья об упаковке Хайнека.]
C.5. Dockerfile
Dockerfiles будет очень специфичным для конкретного проекта, но вот несколько основных этапов, которые ожидаемы:
FROM python:3.8-alpine
(1)
RUN apk add --no-cache --virtual .build-deps gcc postgresql-dev musl-dev python3-dev
RUN apk add libpq
(2)
COPY requirements.txt /tmp/
RUN pip install -r /tmp/requirements.txt
RUN apk del --no-cache .build-deps
(3)
RUN mkdir -p /src
COPY src/ /src/
RUN pip install -e /src
COPY tests/ /tests/
(4)
WORKDIR /src
ENV FLASK_APP=allocation/entrypoints/flask_app.py FLASK_DEBUG=1 PYTHONUNBUFFERED=1
CMD flask run --host=0.0.0.0 --port=80| 1 | Установка зависимостей системного уровня |
| 2 | Установка зависимостей Python (возможно, вы захотите разделить свои зависимости dev и prod; для простоты мы этого не делаем). |
| 3 | Копирование и установка источника |
| 4 | Опциональная настройка команды запуска по умолчанию (вероятно, вы будете часто изменять её из командной строки) |
| Следует отметить, что мы устанавливаем сущности и значения в том порядке, как часто они могут меняться. Это позволяет нам максимально использовать кэш сборки Docker повторно. Я не могу передать, сколько боли и разочарования лежит в основе этого урока. Этот и многие другие советы по улучшению Python Dockerfile смотрите на сайте "Production-Ready Docker Packaging". |
C.6. Тесты
Тесты хранятся вместе со всем остальным, как показано здесь:
└── tests
├── conftest.py
├── e2e
│ └── test_api.py
├── integration
│ ├── test_orm.py
│ └── test_repository.py
├── pytest.ini
└── unit
├── test_allocate.py
├── test_batches.py
└── test_services.pyЗдесь нет ничего особенно умного, просто некоторое разделение различных типов тестов, которые вы, скорее всего, захотите запускать отдельно, и несколько файлов для общих приспособлений, конфигурации и так далее.
В тестовых папках нет папки src или setup.py, потому что обычно нам не нужно делать тесты pip-инсталлируемыми, но если у вас есть трудности с путями импорта, это может вам помочь.
C.7. Подведение итогов
Это наши основные строительные блоки:
-
Исходный код в папке src, pip-инсталлируемый с помощью setup.py.
-
Некоторые конфигурации Docker для создания локального кластера, максимально повторяющего производственный.
-
Конфигурация через переменные окружения, централизованные в файле Python под названием config.py, с настройками по умолчанию, позволяющими запускать вещи вне контейнеров.
-
Makefile для полезных команд командной строки.
Мы сомневаемся, что у кого-то в итоге получатся точно такие же решения, как у нас, но надеемся, что вы найдете здесь вдохновение.
Appendix D: Замена инфраструктуры: Делайте все с CSV
Это приложение предназначено в качестве небольшой иллюстрации преимуществ паттернов Repository, Unit of Work и Service Layer. Она должна следовать из [главы_06_uow].
Как раз когда мы закончили создание нашего Flask API и подготовили его к выпуску, к нам приходит бизнес с извинениями, говоря, что они не готовы использовать наш API, и спрашивая, не могли бы мы создать вещь, которая считывает только партии и заказы из пары CSV и выводит третий CSV с распределениями.
В обычном случае это тот случай, когда команда может ругаться, плеваться и делать заметки для своих мемуаров. Но не мы! О нет, мы убедились, что наши инфраструктурные проблемы хорошо отделены от нашей доменной модели и сервисного уровня. Переход на CSV будет простым делом написания пары новых классов Repository и UnitOfWork, и тогда мы сможем повторно использовать всю нашу логику из уровня домена и уровня сервиса.
Вот тест E2E, показывающий, как CSV поступают и выводятся:
def test_cli_app_reads_csvs_with_batches_and_orders_and_outputs_allocations(
make_csv
):
sku1, sku2 = random_ref('s1'), random_ref('s2')
batch1, batch2, batch3 = random_ref('b1'), random_ref('b2'), random_ref('b3')
order_ref = random_ref('o')
make_csv('batches.csv', [
['ref', 'sku', 'qty', 'eta'],
[batch1, sku1, 100, ''],
[batch2, sku2, 100, '2011-01-01'],
[batch3, sku2, 100, '2011-01-02'],
])
orders_csv = make_csv('orders.csv', [
['orderid', 'sku', 'qty'],
[order_ref, sku1, 3],
[order_ref, sku2, 12],
])
run_cli_script(orders_csv.parent)
expected_output_csv = orders_csv.parent / 'allocations.csv'
with open(expected_output_csv) as f:
rows = list(csv.reader(f))
assert rows == [
['orderid', 'sku', 'qty', 'batchref'],
[order_ref, sku1, '3', batch1],
[order_ref, sku2, '12', batch2],
]Погружаясь в процесс и реализуя его, не думая о репозиториях и прочей чепухе, вы можете начать с чего-то вроде этого:
#!/usr/bin/env python
import csv
import sys
from datetime import datetime
from pathlib import Path
from allocation import model
def load_batches(batches_path):
batches = []
with batches_path.open() as inf:
reader = csv.DictReader(inf)
for row in reader:
if row['eta']:
eta = datetime.strptime(row['eta'], '%Y-%m-%d').date()
else:
eta = None
batches.append(model.Batch(
ref=row['ref'],
sku=row['sku'],
qty=int(row['qty']),
eta=eta
))
return batches
def main(folder):
batches_path = Path(folder) / 'batches.csv'
orders_path = Path(folder) / 'orders.csv'
allocations_path = Path(folder) / 'allocations.csv'
batches = load_batches(batches_path)
with orders_path.open() as inf, allocations_path.open('w') as outf:
reader = csv.DictReader(inf)
writer = csv.writer(outf)
writer.writerow(['orderid', 'sku', 'batchref'])
for row in reader:
orderid, sku = row['orderid'], row['sku']
qty = int(row['qty'])
line = model.OrderLine(orderid, sku, qty)
batchref = model.allocate(line, batches)
writer.writerow([line.orderid, line.sku, batchref])
if __name__ == '__main__':
main(sys.argv[1])Выглядит не так уж плохо! И мы повторно используем объекты нашей доменной модели и нашу доменную службу.
Но это не сработает. Существующие распределения также должны быть частью нашего постоянного хранилища CSV. Мы можем написать второй тест, чтобы заставить нас улучшить ситуацию:
def test_cli_app_also_reads_existing_allocations_and_can_append_to_them(
make_csv
):
sku = random_ref('s')
batch1, batch2 = random_ref('b1'), random_ref('b2')
old_order, new_order = random_ref('o1'), random_ref('o2')
make_csv('batches.csv', [
['ref', 'sku', 'qty', 'eta'],
[batch1, sku, 10, '2011-01-01'],
[batch2, sku, 10, '2011-01-02'],
])
make_csv('allocations.csv', [
['orderid', 'sku', 'qty', 'batchref'],
[old_order, sku, 10, batch1],
])
orders_csv = make_csv('orders.csv', [
['orderid', 'sku', 'qty'],
[new_order, sku, 7],
])
run_cli_script(orders_csv.parent)
expected_output_csv = orders_csv.parent / 'allocations.csv'
with open(expected_output_csv) as f:
rows = list(csv.reader(f))
assert rows == [
['orderid', 'sku', 'qty', 'batchref'],
[old_order, sku, '10', batch1],
[new_order, sku, '7', batch2],
]И мы могли бы продолжать халтурить и добавлять дополнительные строки в эту функцию load_batches, и какой-то способ отслеживания и сохранения новых распределений - но у нас уже есть модель для этого! Это называется нашими шаблонами Repository и Unit of Work.
Все, что нам нужно сделать ("all we need to do") - это заново реализовать те же абстракции, но с CSV, лежащими в их основе, вместо базы данных. И, как вы увидите, это действительно относительно просто.
D.1. Реализация репозитория и единицы работы для CSV
Вот как может выглядеть хранилище на основе CSV. Он абстрагирует всю логику чтения CSV с диска, включая тот факт, что он должен читать два разных CSV (один для партий и один для распределений), и дает нам только знакомый API .list(), который обеспечивает иллюзию коллекции объектов домена в памяти:
class CsvRepository(repository.AbstractRepository):
def __init__(self, folder):
self._batches_path = Path(folder) / 'batches.csv'
self._allocations_path = Path(folder) / 'allocations.csv'
self._batches = {} # type: Dict[str, model.Batch]
self._load()
def get(self, reference):
return self._batches.get(reference)
def add(self, batch):
self._batches[batch.reference] = batch
def _load(self):
with self._batches_path.open() as f:
reader = csv.DictReader(f)
for row in reader:
ref, sku = row['ref'], row['sku']
qty = int(row['qty'])
if row['eta']:
eta = datetime.strptime(row['eta'], '%Y-%m-%d').date()
else:
eta = None
self._batches[ref] = model.Batch(
ref=ref, sku=sku, qty=qty, eta=eta
)
if self._allocations_path.exists() is False:
return
with self._allocations_path.open() as f:
reader = csv.DictReader(f)
for row in reader:
batchref, orderid, sku = row['batchref'], row['orderid'], row['sku']
qty = int(row['qty'])
line = model.OrderLine(orderid, sku, qty)
batch = self._batches[batchref]
batch._allocations.add(line)
def list(self):
return list(self._batches.values())А вот как будет выглядеть UoW для CSV:
class CsvUnitOfWork(unit_of_work.AbstractUnitOfWork):
def __init__(self, folder):
self.batches = CsvRepository(folder)
def commit(self):
with self.batches._allocations_path.open('w') as f:
writer = csv.writer(f)
writer.writerow(['orderid', 'sku', 'qty', 'batchref'])
for batch in self.batches.list():
for line in batch._allocations:
writer.writerow(
[line.orderid, line.sku, line.qty, batch.reference]
)
def rollback(self):
passИ как только мы получим это, наше приложение CLI для чтения и записи партий и распределений в CSV будет сведено к тому, чем оно должно быть - немного кода для чтения строк заказов, и немного кода, который вызывает наш existing service layer:
def main(folder):
orders_path = Path(folder) / 'orders.csv'
uow = csv_uow.CsvUnitOfWork(folder)
with orders_path.open() as f:
reader = csv.DictReader(f)
for row in reader:
orderid, sku = row['orderid'], row['sku']
qty = int(row['qty'])
services.allocate(orderid, sku, qty, uow)Та-да! Ну что, вы впечатлены или как?
С большой любовью,
Боб и Гарри
Appendix E: Validation
Всякий раз, когда мы преподаем и говорим об этих техниках, один из вопросов, который возникает снова и снова: "Где я должен проводить валидацию? Относится ли это к моей бизнес-логике в доменной модели, или это инфраструктурная проблема?".
Как и на любой архитектурный вопрос, ответ таков: это зависит!
Самое важное соображение заключается в том, что мы хотим сохранить наш код хорошо разделенным, чтобы каждая часть системы была простой. Мы не хотим загромождать наш код несущественными деталями.
E.1. Что такое валидация?
Когда люди используют слово валидация, они обычно имеют в виду процесс, в ходе которого они проверяют входы операции, чтобы убедиться, что они соответствуют определенным критериям. Входы, соответствующие критериям, считаются действительными, а входы, не соответствующие критериям, - недействительными.
Если входные данные недействительны, операция не может быть продолжена, а должна завершиться с какой-либо ошибкой. Другими словами, валидация - это создание условий. Мы считаем полезным разделить наши предварительные условия на три подтипа: синтаксис, семантика и прагматика.
E.2. Проверка синтаксиса
В лингвистике синтаксис языка - это набор правил, регулирующих структуру грамматических предложений. Например, в английском языке предложение "Allocate three units of TASTELESS-LAMP to order twenty-seven" является грамматически правильным, в то время как фраза "hat hat hat hat hat wibble" не является. Мы можем описать грамматически правильные предложения как хорошо сформированные.
Как это связано с нашим приложением? Вот несколько примеров синтаксических правил:
-
Команда
Allocateдолжна содержать идентификатор заказа, SKU и количество. -
Количество - это целое положительное число.
-
SKU - это строка.
Это правила относительно формы и структуры входящих данных. Команда Allocate без SKU или ID заказа не является действительным сообщением. Это эквивалент фразы "Выделите три для".
Как правило, мы проверяем эти правила на границе системы. Наше эмпирическое правило заключается в том, что обработчик сообщений всегда должен получать только то сообщение, которое хорошо сформировано и содержит всю необходимую информацию.
Один из вариантов - поместить логику проверки в сам тип сообщения:
from schema import And, Schema, Use
@dataclass
class Allocate(Command):
_schema = Schema({ (1)
'orderid': int,
sku: str,
qty: And(Use(int), lambda n: n > 0)
}, ignore_extra_keys=True)
orderid: str
sku: str
qty: int
@classmethod
def from_json(cls, data): (2)
data = json.loads(data)
return cls(**_schema.validate(data))| 1 | schema library позволяет нам описать структуру и проверку наших сообщений в приятной декларативной форме. |
| 2 | Метод from_json считывает строку как JSON и превращает ее в наш тип сообщения. |
Однако это может стать повторяющимся, поскольку нам нужно дважды указывать поля, поэтому мы можем захотеть ввести вспомогательную библиотеку, которая сможет унифицировать проверку и объявление наших типов сообщений:
def command(name, **fields): (1)
schema = Schema(And(Use(json.loads), fields), ignore_extra_keys=True)
cls = make_dataclass(name, fields.keys()) (2)
cls.from_json = lambda s: cls(**schema.validate(s)) (3)
return cls
def greater_than_zero(x):
return x > 0
quantity = And(Use(int), greater_than_zero) (4)
Allocate = command( (5)
orderid=int,
sku=str,
qty=quantity
)
AddStock = command(
sku=str,
qty=quantity| 1 | Функция command принимает имя сообщения, плюс kwargs для полей полезной нагрузки сообщения, где имя kwarg - имя поля, а значение - парсер. |
| 2 | Мы используем функцию make_dataclass из модуля dataclass для динамического создания нашего типа сообщения. |
| 3 | Мы добавляем метод from_json в наш динамический класс данных. |
| 4 | Мы можем создать многократно используемые парсеры для количества, SKU и так далее, чтобы сохранить все DRY. |
| 5 | Объявление типа сообщения становится однострочным. |
Это происходит за счет потери типов в вашем классе данных, так что имейте в виду этот компромисс.
E.3. Закон Постеля и модель толерантного читателя
Закон Постеля, или принцип прочности, говорит нам: "Будьте либеральны в том, что вы принимаете, и консервативны в том, что вы излучаете". Мы считаем, что это особенно хорошо применимо в контексте интеграции с другими нашими системами. Идея заключается в том, что мы должны быть строгими, когда отправляем сообщения в другие системы, но максимально снисходительными, когда получаем сообщения от других.
Например, наша система может проверять формат SKU. Мы использовали такие выдуманные SKU, как UNFORGIVING-CUSHION и MISBEGOTTEN-POUFFE. Они следуют простой схеме: два слова, разделенные тире, где второе слово - тип продукта, а первое слово - прилагательное.
Разработчики любят проверять такие вещи в своих сообщениях и отклоняют все, что выглядит как недопустимый SKU. Это приводит к ужасным проблемам в будущем, когда какой-нибудь анархист выпустит продукт под названием COMFY-CHAISE-LONGUE или когда в результате ошибки поставщика будет поставлена партия CHEAP-CARPET-2.
Действительно, как система распределения, это не наше дело, каким может быть формат SKU. Все, что нам нужно - это идентификатор, поэтому мы можем просто описать его как строку. Это означает, что система закупок может менять формат, когда захочет, а нам будет все равно.
Этот же принцип применим к номерам заказов, номерам телефонов клиентов и многому другому. По большей части, мы можем игнорировать внутреннюю структуру строк.
Аналогично, разработчики любят проверять входящие сообщения с помощью таких инструментов, как JSON Schema, или создавать библиотеки, которые проверяют входящие сообщения и обмениваются ими между системами. Это также не проходит проверку на устойчивость.
Представим, например, что система закупок добавляет новые поля в сообщение ChangeBatchQuantity, которые записывают причину изменения и электронную почту пользователя, ответственного за изменение.
Поскольку эти поля не имеют значения для службы распределения, мы должны просто игнорировать их. Мы можем сделать это в библиотеке schema, передав ключевое слово arg ignore_extra_keys=True.
Этот шаблон, при котором мы извлекаем только те поля, которые нас интересуют, и делаем минимальную проверку этих полей, является шаблоном толерантного читателя.
| Валидируйте как можно меньше. Читайте только те поля, которые вам нужны, и не указывайте их содержимое слишком подробно. Это поможет вашей системе оставаться надежной, когда другие системы меняются со временем. Не поддавайтесь соблазну совместно использовать определения сообщений в разных системах: Вместо этого упростите определение данных, от которых вы зависите. Более подробную информацию можно найти в статье Мартина Фаулера паттерн "Толерантный читатель". |
E.4. Проверка на границе
Ранее мы говорили, что хотим избежать загромождения нашего кода ненужными деталями. В частности, мы не хотим, чтобы код защищался внутри нашей модели домена. Вместо этого мы хотим убедиться, что запросы известны как действительные, прежде чем наша модель домена или обработчики вариантов использования увидят их. Это помогает нашему коду оставаться чистым и ремонтопригодным в долгосрочной перспективе. Мы иногда называем это "валидацией на краю системы".
В дополнение к тому, чтобы ваш код оставался чистым и свободным от бесконечных проверок и утверждений, имейте в виду, что неверные данные, блуждающие по вашей системе, - это бомба замедленного действия; чем глубже он проникает, тем больше вреда он может нанести и тем меньше инструментов у вас есть, чтобы реагировать на него.
Еще в События и шина сообщений мы говорили, что шина сообщений-отличное место для решения сквозных проблем, и проверка является прекрасным примером этого. Вот как мы можем изменить нашу шину, чтобы выполнить проверку для нас:
class MessageBus:
def handle_message(self, name: str, body: str):
try:
message_type = next(mt for mt in EVENT_HANDLERS if mt.__name__ == name)
message = message_type.from_json(body)
self.handle([message])
except StopIteration:
raise KeyError(f"Unknown message name {name}")
except ValidationError as e:
logging.error(
f'invalid message of type {name}\n'
f'{body}\n'
f'{e}'
)
raise eВот как мы можем использовать этот метод из конечной точки Flask API:
@app.route("/change_quantity", methods=['POST'])
def change_batch_quantity():
try:
bus.handle_message('ChangeBatchQuantity', request.body)
except ValidationError as e:
return bad_request(e)
except exceptions.InvalidSku as e:
return jsonify({'message': str(e)}), 400
def bad_request(e: ValidationError):
return e.code, 400И вот как мы могли бы подключить его к нашему асинхронному процессору сообщений:
def handle_change_batch_quantity(m, bus: messagebus.MessageBus):
try:
bus.handle_message('ChangeBatchQuantity', m)
except ValidationError:
print('Skipping invalid message')
except exceptions.InvalidSku as e:
print(f'Unable to change stock for missing sku {e}')Обратите внимание, что наши точки входа занимаются исключительно тем, как получить сообщение из внешнего мира и как сообщить об успехе или неудаче. Наша шина сообщений заботится о проверке наших запросов и направлении их в нужный обработчик, а наши обработчики сосредоточены исключительно на логике нашего сценария использования.
| Когда вы получаете недопустимое сообщение, обычно мало что можно сделать, кроме как зарегистрировать ошибку и продолжить работу. В MADE мы используем метрики для подсчета количества сообщений, которые получает система, и сколько из них успешно обработано, пропущено или недействительно. Наши инструменты мониторинга предупредят нас, если мы увидим всплески количества плохих сообщений. |
E.5. Проверка семантики
В то время как синтаксис занимается структурой сообщений, семантика изучает смысл в сообщениях. Предложение "Отмените четыре многоточия". является синтаксически правильным и имеет ту же структуру, что и предложение "Выделите один чайник на заказ пяти". но это бессмысленно.
Мы можем прочитать этот JSON-блоб как команду Allocate, но не можем успешно выполнить ее, потому что это бессмыслица:
{
"orderid": "superman",
"sku": "zygote",
"qty": -1
}Мы склонны подтверждать семантические проблемы на уровне обработчика сообщений с помощью своего рода программирования на основе контрактов:
"""
Этот модуль содержит предварительные условия, которые мы применяем к нашим обработчикам.
"""
class MessageUnprocessable(Exception): (1)
def __init__(self, message):
self.message = message
class ProductNotFound(MessageUnprocessable): (2)
""""
Это исключение возникает, когда мы пытаемся выполнить действие над продуктом
которого не существует в нашей базе данных.
""""
def __init__(self, message):
super().__init__(message)
self.sku = message.sku
def product_exists(event, uow): (3)
product = uow.products.get(event.sku)
if product is None:
raise ProductNotFound(event)| 1 | Мы используем общий базовый класс для ошибок, которые означают, что сообщение недопустимо. |
| 2 | Использование конкретного типа ошибки для этой проблемы облегчает составление отчета и обработку ошибки. Например, во Flask легко сопоставить ProductNotFound с 404. |
| 3 | product_exists является предварительным условием. Если условие False, мы выдаем ошибку. |
Таким образом, основной поток нашей логики в сервисном уровне остается чистым и декларативным:
# services.py
from allocation import ensure
def allocate(event, uow):
line = model.OrderLine(event.orderid, event.sku, event.qty)
with uow:
ensure.product_exists(event, uow)
product = uow.products.get(line.sku)
product.allocate(line)
uow.commit()Мы можем расширить эту технику, чтобы убедиться, что мы применяем сообщения идемпотентно. Например, мы хотим убедиться, что мы не вставляем партию запасов более одного раза.
Если нас попросят создать партию, которая уже существует, мы выдадим предупреждение и перейдем к следующему сообщению:
class SkipMessage (Exception):
""""
Это исключение возникает, когда сообщение не может быть обработано,
но нет никакого неправильного поведения. Например, мы можем получить
одно и то же сообщение несколько раз, или мы можем получить сообщение,
которое уже устарело.
""""
def __init__(self, reason):
self.reason = reason
def batch_is_new(self, event, uow):
batch = uow.batches.get(event.batchid)
if batch is not None:
raise SkipMessage(f"Batch with id {event.batchid} already exists")Внедрение исключения SkipMessage позволяет нам обрабатывать эти случаи общим способом в нашей шине сообщений:
class MessageBus:
def handle_message(self, message):
try:
...
except SkipMessage as e:
logging.warn(f"Skipping message {message.id} because {e.reason}")Здесь есть несколько подводных камней, о которых следует знать. Во-первых, мы должны быть уверены, что используем тот же UoW, который мы используем для основной логики нашего варианта использования. В противном случае мы открываемся для раздражающих ошибок параллелизма.
Во-вторых, мы должны стараться не включать всю нашу бизнес-логику в эти проверки предварительных условий. Как правило, если правило _ может быть протестировано внутри нашей модели домена, то оно _ должно быть протестировано в модели домена.
E.6. Проверка прагматики
Прагматика - это изучение того, как мы понимаем язык в контексте. После того, как мы разобрали сообщение и поняли его смысл, нам все еще нужно обработать его в контексте. Например, если вы получите комментарий к заявке: "Я думаю, это очень смело". это может означать, что рецензент восхищается вашей смелостью - если только он не британец, в этом случае он пытается сказать вам, что то, что вы делаете, безумно рискованно, и только дурак попытается это сделать. Контекст - это все.
| После того как вы проверили синтаксис и семантику команд на границах вашей системы, домен становится местом для остальной проверки. Валидация прагматики часто является основной частью ваших бизнес-правил. |
В терминах программного обеспечения прагматика операции обычно управляется моделью домена. Когда мы получаем сообщение типа "выделите три миллиона единиц SCARCE-CLOCK для заказа 76543," сообщение является синтаксически действительным и семантически действительным, но мы не можем его выполнить, потому что у нас нет в наличии запасов.